 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialMem: Unified 3D Memory with Metric Anchoring and Fast Retrieval
Jan 21, 2026We present SpatialMem, a memory-centric system that unifies 3D geometry, semantics, and language into a single, queryable representation. Starting from casually captured egocentric RGB video, SpatialMem reconstructs metrically scaled indoor environments, detects structural 3D anchors (walls, doors, windows) as the first-layer scaffold, and populates a hierarchical memory with open-vocabulary object nodes -- linking evidence patches, visual embeddings, and two-layer textual descriptions to 3D coordinates -- for compact storage and fast retrieval. This design enables interpretable reasoning over spatial relations (e.g., distance, direction, visibility) and supports downstream tasks such as language-guided navigation and object retrieval without specialized sensors. Experiments across three real-life indoor scenes demonstrate that SpatialMem maintains strong anchor-description-level navigation completion and hierarchical retrieval accuracy under increasing clutter and occlusion, offering an efficient and extensible framework for embodied spatial intelligence.
MARC: Memory-Augmented RL Token Compression for Efficient Video Understanding
Oct 09, 2025The rapid progress of large language models (LLMs) has laid the foundation for multimodal models. However, visual language models (VLMs) still face heavy computational costs when extended from images to videos due to high frame rates and long durations. Token compression is a promising solution, yet most existing training-free methods cause information loss and performance degradation. To overcome this, we propose \textbf{Memory-Augmented Reinforcement Learning-based Token Compression (MARC)}, which integrates structured retrieval and RL-based distillation. MARC adopts a \textit{retrieve-then-compress} strategy using a \textbf{Visual Memory Retriever (VMR)} to select key clips and a \textbf{Compression Group Relative Policy Optimization (C-GRPO)} framework to distil reasoning ability from a teacher to a student model. Experiments on six video benchmarks show that MARC achieves near-baseline accuracy using only one frame's tokens -- reducing visual tokens by \textbf{95\%}, GPU memory by \textbf{72\%}, and latency by \textbf{23.9\%}. This demonstrates its potential for efficient, real-time video understanding in resource-constrained settings such as video QA, surveillance, and autonomous driving.
Fashion Captioning: Towards Generating Accurate Descriptions with Semantic Rewards
Aug 06, 2020
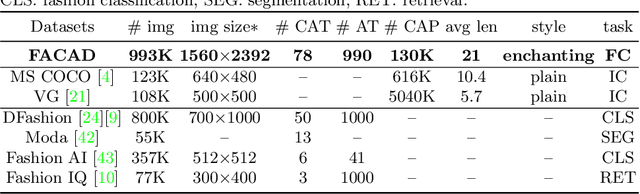
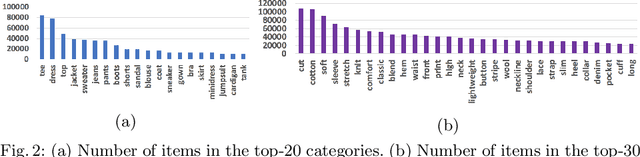
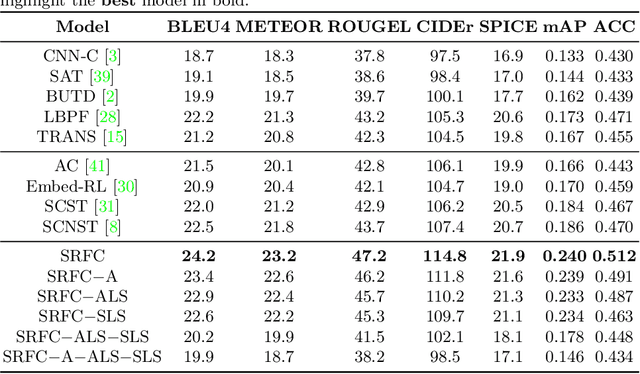
Generating accurate descriptions for online fashion items is important not only for enhancing customers' shopping experiences, but also for the increase of online sales. Besides the need of correctly presenting the attributes of items, the expressions in an enchanting style could better attract customer interests. The goal of this work is to develop a novel learning framework for accurate and expressive fashion captioning. Different from popular work on image captioning, it is hard to identify and describe the rich attributes of fashion items. We seed the description of an item by first identifying its attributes, and introduce attribute-level semantic (ALS) reward and sentence-level semantic (SLS) reward as metrics to improve the quality of text descriptions. We further integrate the training of our model with maximum likelihood estimation (MLE), attribute embedding, and Reinforcement Learning (RL). To facilitate the learning, we build a new FAshion CAptioning Dataset (FACAD), which contains 993K images and 130K corresponding enchanting and diverse descriptions. Experiments on FACAD demonstrate the effectiveness of our model.
Learning Color Compatibility in Fashion Outfits
Jul 05, 2020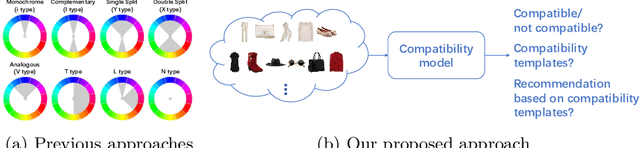
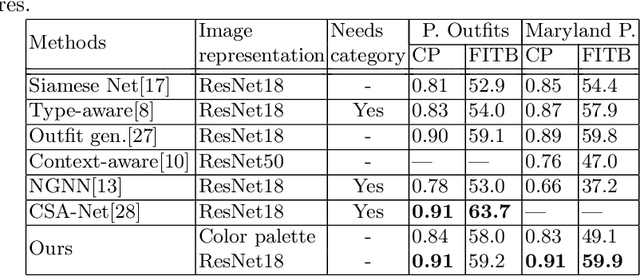
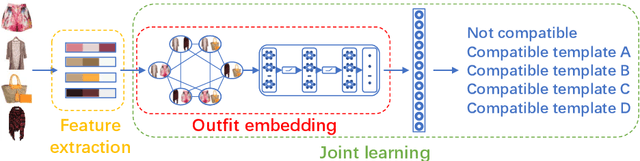
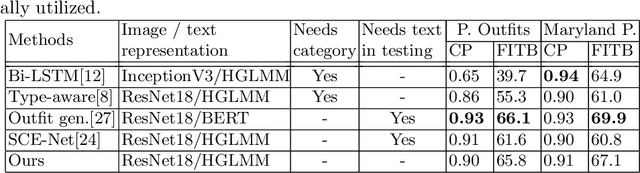
Color compatibility is important for evaluating the compatibility of a fashion outfit, yet it was neglected in previous studies. We bring this important problem to researchers' attention and present a compatibility learning framework as solution to various fashion tasks. The framework consists of a novel way to model outfit compatibility and an innovative learning scheme. Specifically, we model the outfits as graphs and propose a novel graph construction to better utilize the power of graph neural networks. Then we utilize both ground-truth labels and pseudo labels to train the compatibility model in a weakly-supervised manner.Extensive experimental results verify the importance of color compatibility alone with the effectiveness of our framework. With color information alone, our model's performance is already comparable to previous methods that use deep image features. Our full model combining the aforementioned contributions set the new state-of-the-art in fashion compatibility prediction.
Learning Raw Image Denoising with Bayer Pattern Unification and Bayer Preserving Augmentation
Apr 29, 2019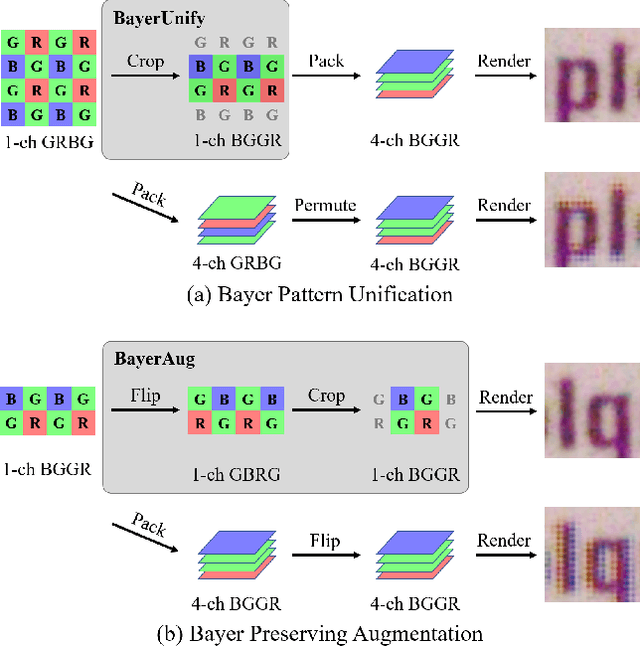



In this paper, we present new data pre-processing and augmentation techniques for DNN-based raw image denoising. Compared with traditional RGB image denoising, performing this task on direct camera sensor readings presents new challenges such as how to effectively handle various Bayer patterns from different data sources, and subsequently how to perform valid data augmentation with raw images. To address the first problem, we propose a Bayer pattern unification (BayerUnify) method to unify different Bayer patterns. This allows us to fully utilize a heterogeneous dataset to train a single denoising model instead of training one model for each pattern. Furthermore, while it is essential to augment the dataset to improve model generalization and performance, we discovered that it is error-prone to modify raw images by adapting augmentation methods designed for RGB images. Towards this end, we present a Bayer preserving augmentation (BayerAug) method as an effective approach for raw image augmentation. Combining these data processing technqiues with a modified U-Net, our method achieves a PSNR of 52.11 and a SSIM of 0.9969 in NTIRE 2019 Real Image Denoising Challenge, demonstrating the state-of-the-art performance.
A Taught-Obesrve-Ask Method for Object Detection with Critical Supervision
Nov 03, 2017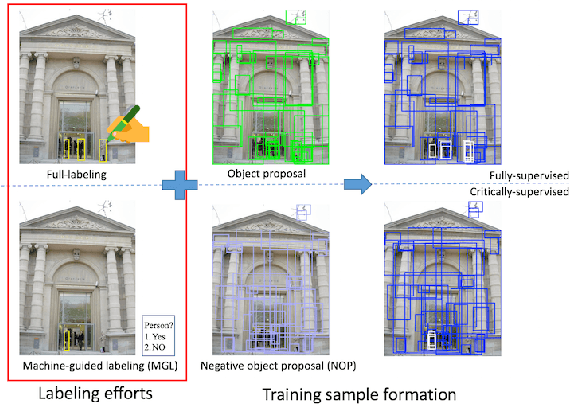

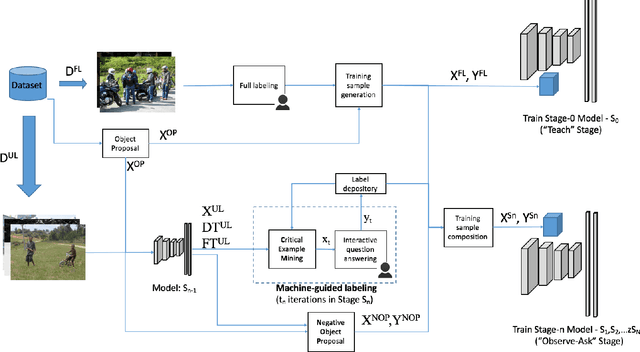

Being inspired by child's learning experience - taught first and followed by observation and questioning, we investigate a critically supervised learning methodology for object detection in this work. Specifically, we propose a taught-observe-ask (TOA) method that consists of several novel components such as negative object proposal, critical example mining, and machine-guided question-answer (QA) labeling. To consider labeling time and performance jointly, new evaluation methods are developed to compare the performance of the TOA method, with the fully and weakly supervised learning methods. Extensive experiments are conducted on the PASCAL VOC and the Caltech benchmark datasets. The TOA method provides significantly improved performance of weakly supervision yet demands only about 3-6% of labeling time of full supervision. The effectiveness of each novel component is also analyzed.