 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError Bound Analysis of Physics-Informed Neural Networks-Driven T2 Quantification in Cardiac Magnetic Resonance Imaging
Dec 16, 2025



Physics-Informed Neural Networks (PINN) are emerging as a promising approach for quantitative parameter estimation of Magnetic Resonance Imaging (MRI). While existing deep learning methods can provide an accurate quantitative estimation of the T2 parameter, they still require large amounts of training data and lack theoretical support and a recognized gold standard. Thus, given the absence of PINN-based approaches for T2 estimation, we propose embedding the fundamental physics of MRI, the Bloch equation, in the loss of PINN, which is solely based on target scan data and does not require a pre-defined training database. Furthermore, by deriving rigorous upper bounds for both the T2 estimation error and the generalization error of the Bloch equation solution, we establish a theoretical foundation for evaluating the PINN's quantitative accuracy. Even without access to the ground truth or a gold standard, this theory enables us to estimate the error with respect to the real quantitative parameter T2. The accuracy of T2 mapping and the validity of the theoretical analysis are demonstrated on a numerical cardiac model and a water phantom, where our method exhibits excellent quantitative precision in the myocardial T2 range. Clinical applicability is confirmed in 94 acute myocardial infarction (AMI) patients, achieving low-error quantitative T2 estimation under the theoretical error bound, highlighting the robustness and potential of PINN.
Beyond Frequency: Seeing Subtle Cues Through the Lens of Spatial Decomposition for Fine-Grained Visual Classification
Aug 09, 2025


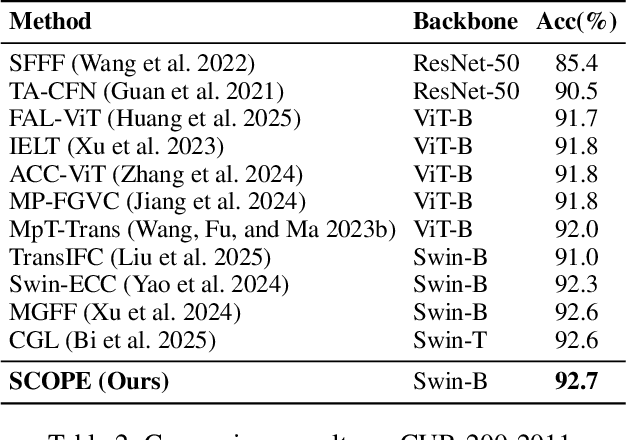
The crux of resolving fine-grained visual classification (FGVC) lies in capturing discriminative and class-specific cues that correspond to subtle visual characteristics. Recently, frequency decomposition/transform based approaches have attracted considerable interests since its appearing discriminative cue mining ability. However, the frequency-domain methods are based on fixed basis functions, lacking adaptability to image content and unable to dynamically adjust feature extraction according to the discriminative requirements of different images. To address this, we propose a novel method for FGVC, named Subtle-Cue Oriented Perception Engine (SCOPE), which adaptively enhances the representational capability of low-level details and high-level semantics in the spatial domain, breaking through the limitations of fixed scales in the frequency domain and improving the flexibility of multi-scale fusion. The core of SCOPE lies in two modules: the Subtle Detail Extractor (SDE), which dynamically enhances subtle details such as edges and textures from shallow features, and the Salient Semantic Refiner (SSR), which learns semantically coherent and structure-aware refinement features from the high-level features guided by the enhanced shallow features. The SDE and SSR are cascaded stage-by-stage to progressively combine local details with global semantics. Extensive experiments demonstrate that our method achieves new state-of-the-art on four popular fine-grained image classification benchmarks.
Learning to Rank Pre-trained Vision-Language Models for Downstream Tasks
Dec 30, 2024Vision language models (VLMs) like CLIP show stellar zero-shot capability on classification benchmarks. However, selecting the VLM with the highest performance on the unlabeled downstream task is non-trivial. Existing VLM selection methods focus on the class-name-only setting, relying on a supervised large-scale dataset and large language models, which may not be accessible or feasible during deployment. This paper introduces the problem of \textbf{unsupervised vision-language model selection}, where only unsupervised downstream datasets are available, with no additional information provided. To solve this problem, we propose a method termed Visual-tExtual Graph Alignment (VEGA), to select VLMs without any annotations by measuring the alignment of the VLM between the two modalities on the downstream task. VEGA is motivated by the pretraining paradigm of VLMs, which aligns features with the same semantics from the visual and textual modalities, thereby mapping both modalities into a shared representation space. Specifically, we first construct two graphs on the vision and textual features, respectively. VEGA is then defined as the overall similarity between the visual and textual graphs at both node and edge levels. Extensive experiments across three different benchmarks, covering a variety of application scenarios and downstream datasets, demonstrate that VEGA consistently provides reliable and accurate estimates of VLMs' performance on unlabeled downstream tasks.
HeGraphAdapter: Tuning Multi-Modal Vision-Language Models with Heterogeneous Graph Adapter
Oct 10, 2024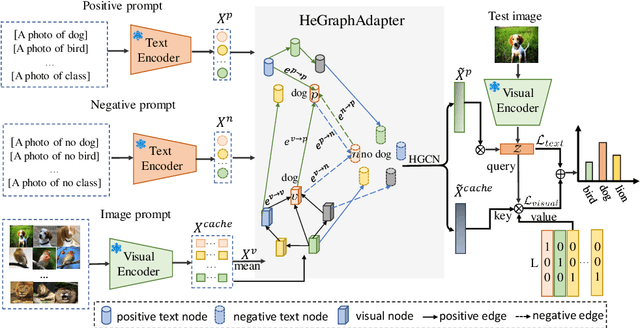
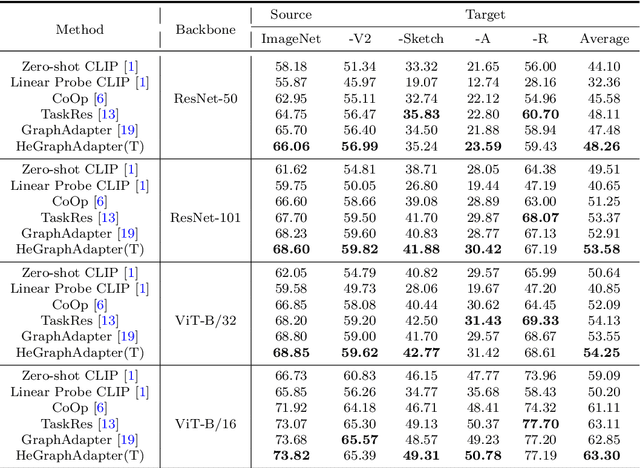
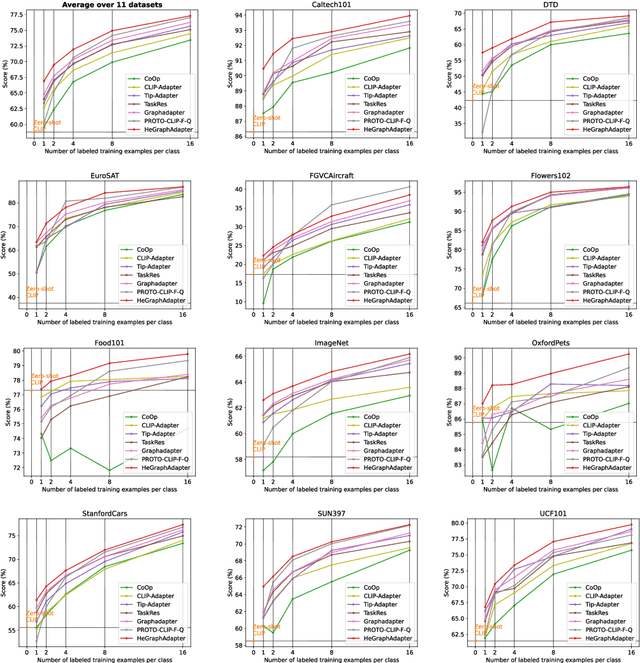
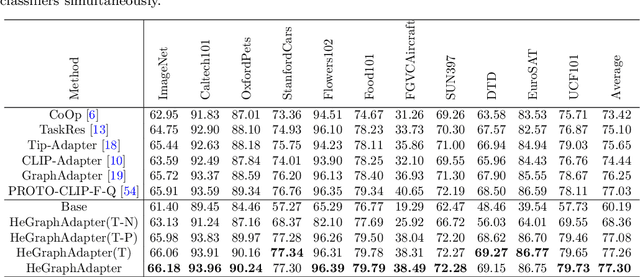
Adapter-based tuning methods have shown significant potential in transferring knowledge from pre-trained Vision-Language Models to the downstream tasks. However, after reviewing existing adapters, we find they generally fail to fully explore the interactions between different modalities in constructing task-specific knowledge. Also, existing works usually only focus on similarity matching between positive text prompts, making it challenging to distinguish the classes with high similar visual contents. To address these issues, in this paper, we propose a novel Heterogeneous Graph Adapter to achieve tuning VLMs for the downstream tasks. To be specific, we first construct a unified heterogeneous graph mode, which contains i) visual nodes, positive text nodes and negative text nodes, and ii) several types of edge connections to comprehensively model the intra-modality, inter-modality and inter-class structure knowledge together. Next, we employ a specific Heterogeneous Graph Neural Network to excavate multi-modality structure knowledge for adapting both visual and textual features for the downstream tasks. Finally, after HeGraphAdapter, we construct both text-based and visual-based classifiers simultaneously to comprehensively enhance the performance of the CLIP model. Experimental results on 11 benchmark datasets demonstrate the effectiveness and benefits of the proposed HeGraphAdapter.
Context-Semantic Quality Awareness Network for Fine-Grained Visual Categorization
Mar 15, 2024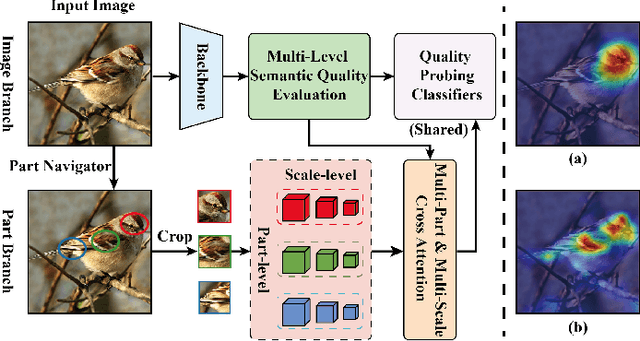
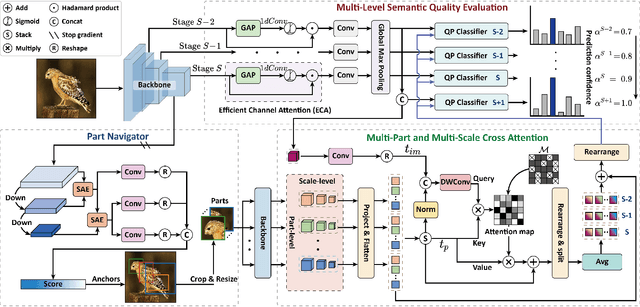
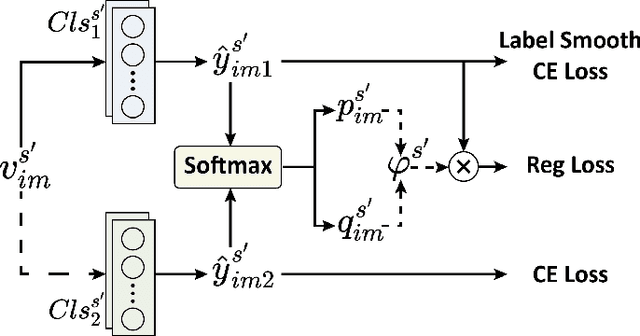
Exploring and mining subtle yet distinctive features between sub-categories with similar appearances is crucial for fine-grained visual categorization (FGVC). However, less effort has been devoted to assessing the quality of extracted visual representations. Intuitively, the network may struggle to capture discriminative features from low-quality samples, which leads to a significant decline in FGVC performance. To tackle this challenge, we propose a weakly supervised Context-Semantic Quality Awareness Network (CSQA-Net) for FGVC. In this network, to model the spatial contextual relationship between rich part descriptors and global semantics for capturing more discriminative details within the object, we design a novel multi-part and multi-scale cross-attention (MPMSCA) module. Before feeding to the MPMSCA module, the part navigator is developed to address the scale confusion problems and accurately identify the local distinctive regions. Furthermore, we propose a generic multi-level semantic quality evaluation module (MLSQE) to progressively supervise and enhance hierarchical semantics from different levels of the backbone network. Finally, context-aware features from MPMSCA and semantically enhanced features from MLSQE are fed into the corresponding quality probing classifiers to evaluate their quality in real-time, thus boosting the discriminability of feature representations. Comprehensive experiments on four popular and highly competitive FGVC datasets demonstrate the superiority of the proposed CSQA-Net in comparison with the state-of-the-art methods.
Robust Transductive Few-shot Learning via Joint Message Passing and Prototype-based Soft-label Propagation
Nov 28, 2023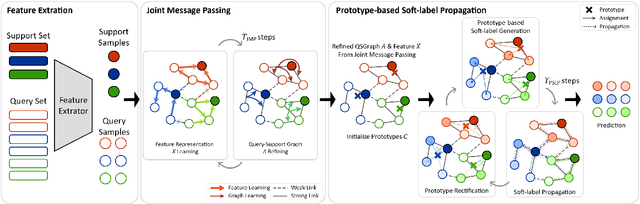
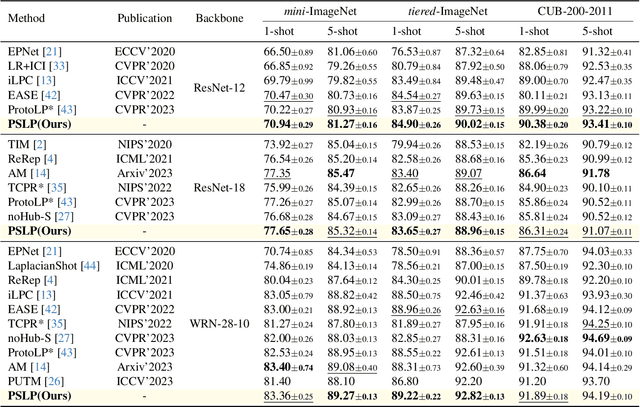
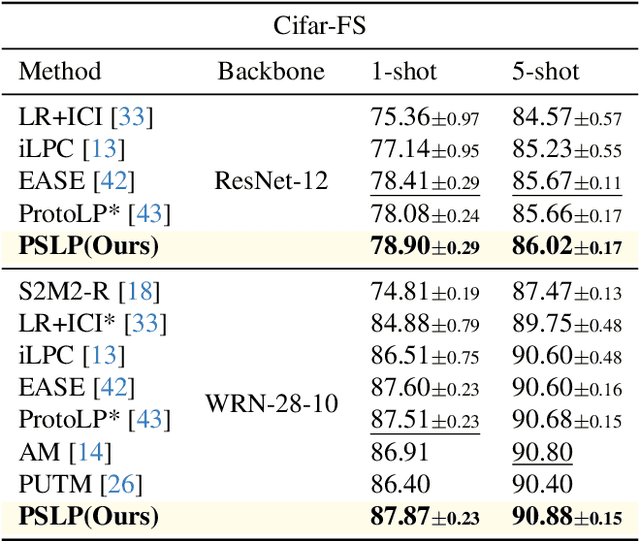
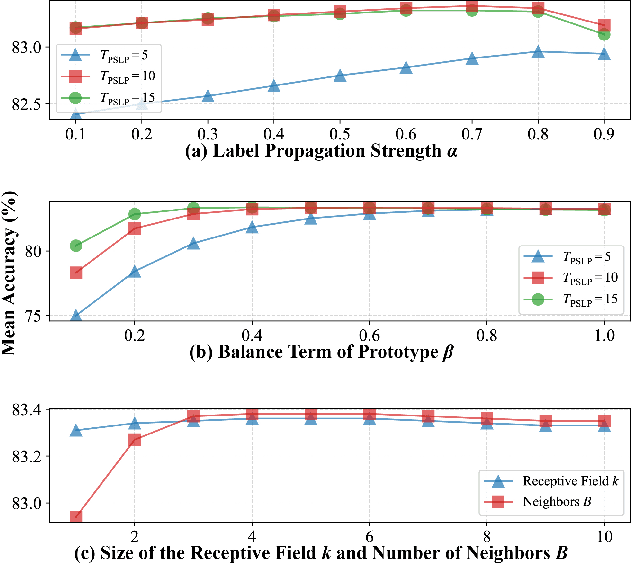
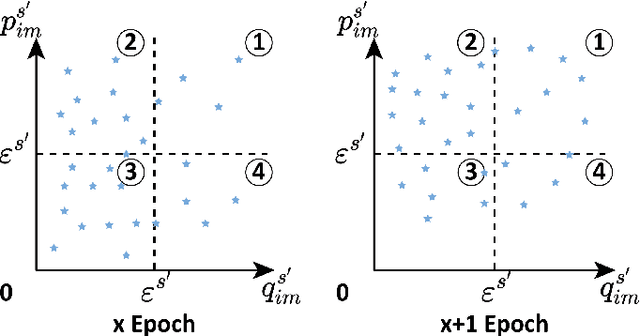
Few-shot learning (FSL) aims to develop a learning model with the ability to generalize to new classes using a few support samples. For transductive FSL tasks, prototype learning and label propagation methods are commonly employed. Prototype methods generally first learn the representative prototypes from the support set and then determine the labels of queries based on the metric between query samples and prototypes. Label propagation methods try to propagate the labels of support samples on the constructed graph encoding the relationships between both support and query samples. This paper aims to integrate these two principles together and develop an efficient and robust transductive FSL approach, termed Prototype-based Soft-label Propagation (PSLP). Specifically, we first estimate the soft-label presentation for each query sample by leveraging prototypes. Then, we conduct soft-label propagation on our learned query-support graph. Both steps are conducted progressively to boost their respective performance. Moreover, to learn effective prototypes for soft-label estimation as well as the desirable query-support graph for soft-label propagation, we design a new joint message passing scheme to learn sample presentation and relational graph jointly. Our PSLP method is parameter-free and can be implemented very efficiently. On four popular datasets, our method achieves competitive results on both balanced and imbalanced settings compared to the state-of-the-art methods. The code will be released upon acceptance.
Practical Deep Raw Image Denoising on Mobile Devices
Oct 14, 2020

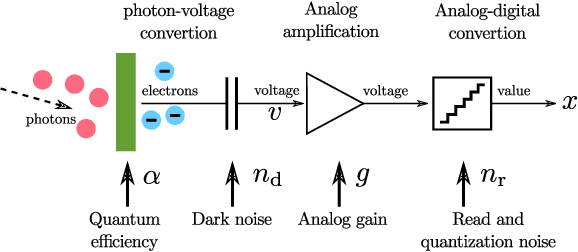
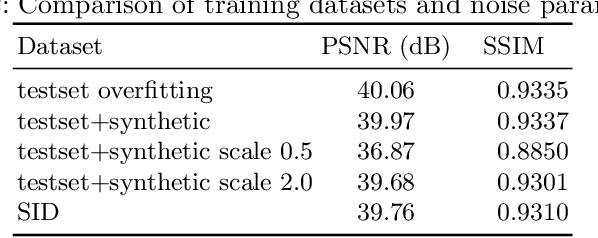
Deep learning-based image denoising approaches have been extensively studied in recent years, prevailing in many public benchmark datasets. However, the stat-of-the-art networks are computationally too expensive to be directly applied on mobile devices. In this work, we propose a light-weight, efficient neural network-based raw image denoiser that runs smoothly on mainstream mobile devices, and produces high quality denoising results. Our key insights are twofold: (1) by measuring and estimating sensor noise level, a smaller network trained on synthetic sensor-specific data can out-perform larger ones trained on general data; (2) the large noise level variation under different ISO settings can be removed by a novel k-Sigma Transform, allowing a small network to efficiently handle a wide range of noise levels. We conduct extensive experiments to demonstrate the efficiency and accuracy of our approach. Our proposed mobile-friendly denoising model runs at ~70 milliseconds per megapixel on Qualcomm Snapdragon 855 chipset, and it is the basis of the night shot feature of several flagship smartphones released in 2019.
Learning Raw Image Denoising with Bayer Pattern Unification and Bayer Preserving Augmentation
Apr 29, 2019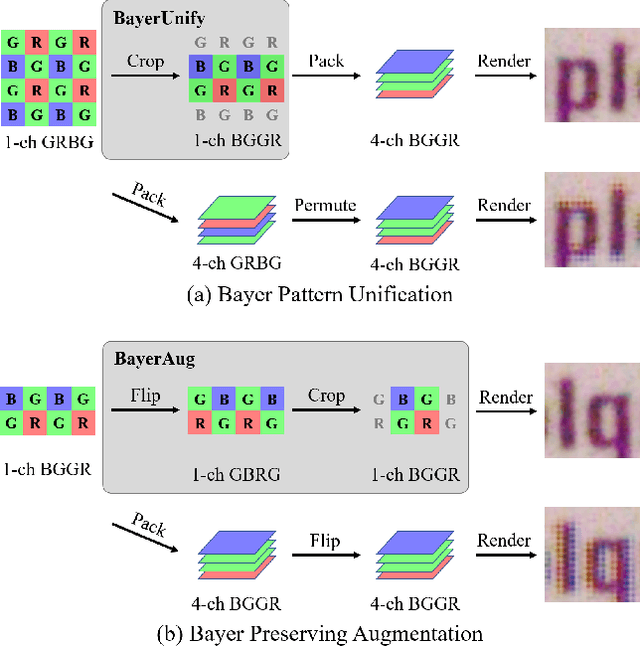



In this paper, we present new data pre-processing and augmentation techniques for DNN-based raw image denoising. Compared with traditional RGB image denoising, performing this task on direct camera sensor readings presents new challenges such as how to effectively handle various Bayer patterns from different data sources, and subsequently how to perform valid data augmentation with raw images. To address the first problem, we propose a Bayer pattern unification (BayerUnify) method to unify different Bayer patterns. This allows us to fully utilize a heterogeneous dataset to train a single denoising model instead of training one model for each pattern. Furthermore, while it is essential to augment the dataset to improve model generalization and performance, we discovered that it is error-prone to modify raw images by adapting augmentation methods designed for RGB images. Towards this end, we present a Bayer preserving augmentation (BayerAug) method as an effective approach for raw image augmentation. Combining these data processing technqiues with a modified U-Net, our method achieves a PSNR of 52.11 and a SSIM of 0.9969 in NTIRE 2019 Real Image Denoising Challenge, demonstrating the state-of-the-art performance.
Perceive Where to Focus: Learning Visibility-aware Part-level Features for Partial Person Re-identification
Apr 01, 2019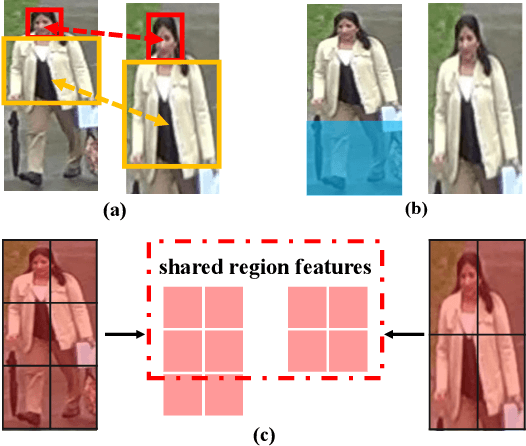
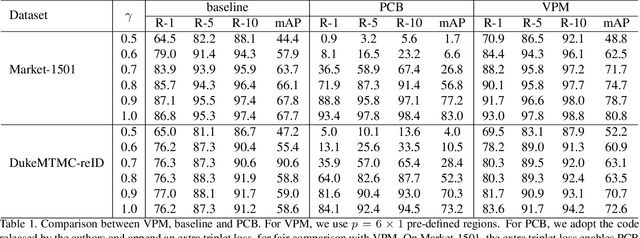
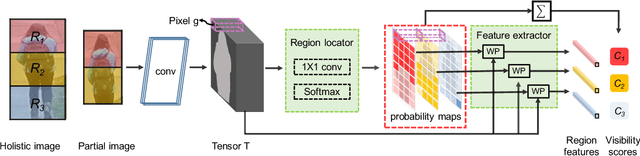
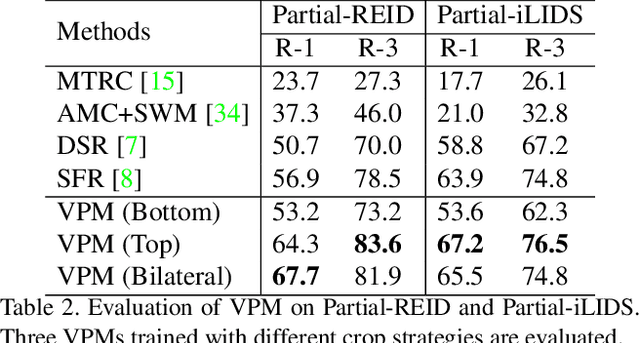
This paper considers a realistic problem in person re-identification (re-ID) task, i.e., partial re-ID. Under partial re-ID scenario, the images may contain a partial observation of a pedestrian. If we directly compare a partial pedestrian image with a holistic one, the extreme spatial misalignment significantly compromises the discriminative ability of the learned representation. We propose a Visibility-aware Part Model (VPM), which learns to perceive the visibility of regions through self-supervision. The visibility awareness allows VPM to extract region-level features and compare two images with focus on their shared regions (which are visible on both images). VPM gains two-fold benefit toward higher accuracy for partial re-ID. On the one hand, compared with learning a global feature, VPM learns region-level features and benefits from fine-grained information. On the other hand, with visibility awareness, VPM is capable to estimate the shared regions between two images and thus suppresses the spatial misalignment. Experimental results confirm that our method significantly improves the learned representation and the achieved accuracy is on par with the state of the art.