 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeGraphAdapter: Tuning Multi-Modal Vision-Language Models with Heterogeneous Graph Adapter
Oct 10, 2024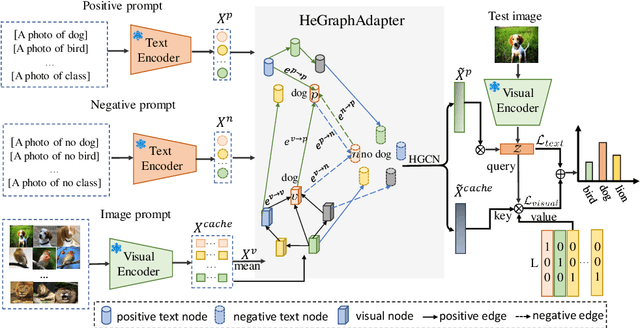
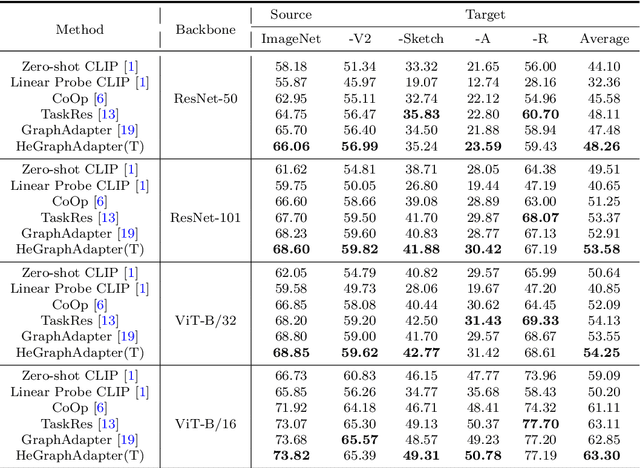
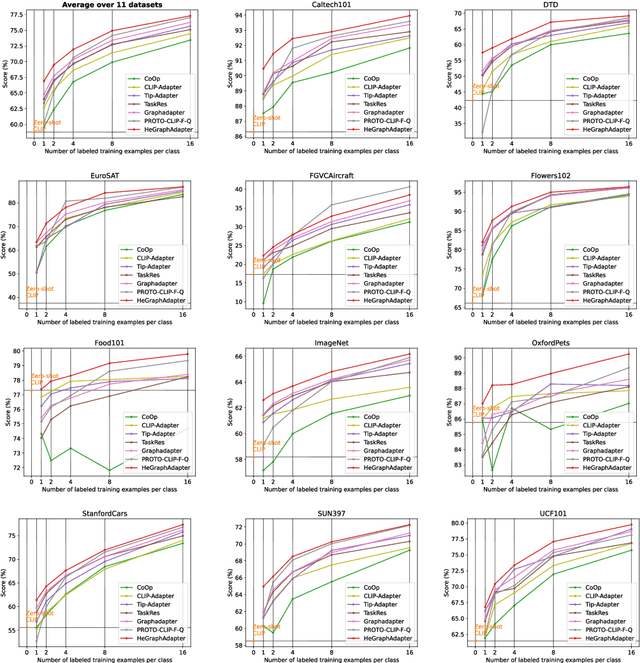
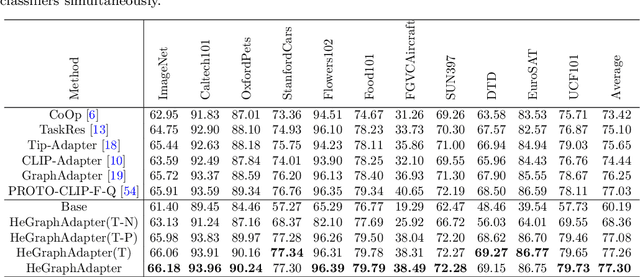
Adapter-based tuning methods have shown significant potential in transferring knowledge from pre-trained Vision-Language Models to the downstream tasks. However, after reviewing existing adapters, we find they generally fail to fully explore the interactions between different modalities in constructing task-specific knowledge. Also, existing works usually only focus on similarity matching between positive text prompts, making it challenging to distinguish the classes with high similar visual contents. To address these issues, in this paper, we propose a novel Heterogeneous Graph Adapter to achieve tuning VLMs for the downstream tasks. To be specific, we first construct a unified heterogeneous graph mode, which contains i) visual nodes, positive text nodes and negative text nodes, and ii) several types of edge connections to comprehensively model the intra-modality, inter-modality and inter-class structure knowledge together. Next, we employ a specific Heterogeneous Graph Neural Network to excavate multi-modality structure knowledge for adapting both visual and textual features for the downstream tasks. Finally, after HeGraphAdapter, we construct both text-based and visual-based classifiers simultaneously to comprehensively enhance the performance of the CLIP model. Experimental results on 11 benchmark datasets demonstrate the effectiveness and benefits of the proposed HeGraphAdapter.