 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Semantic Quality Awareness Network for Fine-Grained Visual Categorization
Paper and Code
Mar 15, 2024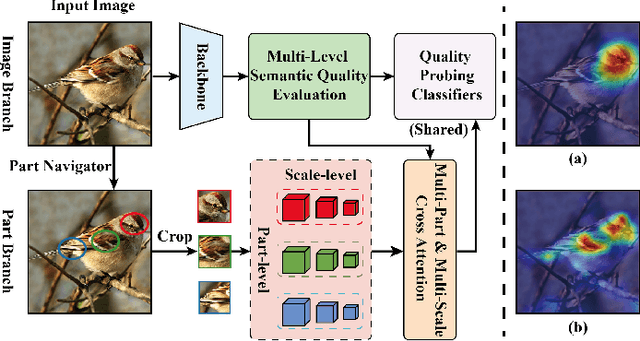
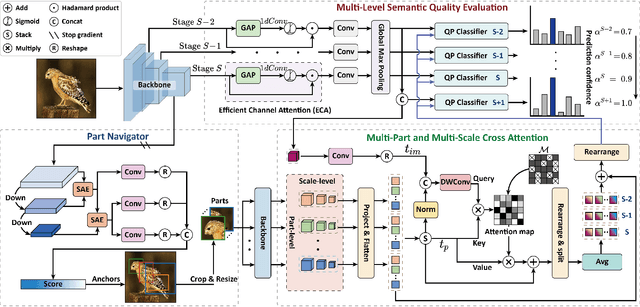
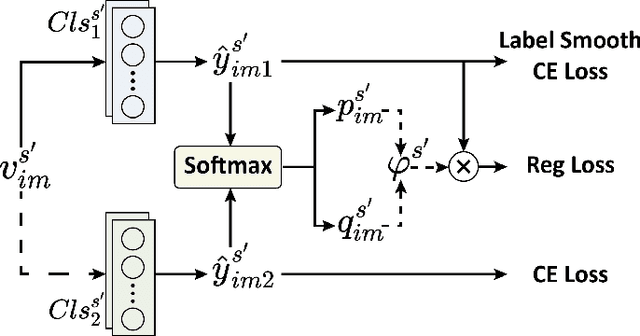
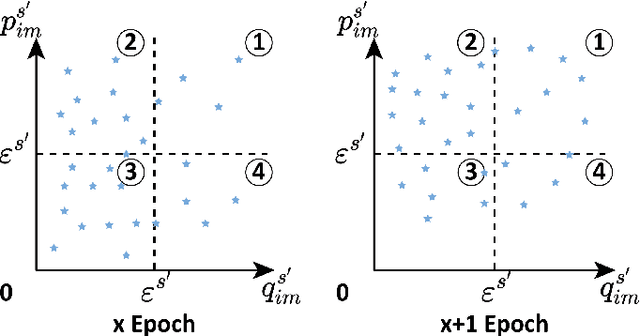
Exploring and mining subtle yet distinctive features between sub-categories with similar appearances is crucial for fine-grained visual categorization (FGVC). However, less effort has been devoted to assessing the quality of extracted visual representations. Intuitively, the network may struggle to capture discriminative features from low-quality samples, which leads to a significant decline in FGVC performance. To tackle this challenge, we propose a weakly supervised Context-Semantic Quality Awareness Network (CSQA-Net) for FGVC. In this network, to model the spatial contextual relationship between rich part descriptors and global semantics for capturing more discriminative details within the object, we design a novel multi-part and multi-scale cross-attention (MPMSCA) module. Before feeding to the MPMSCA module, the part navigator is developed to address the scale confusion problems and accurately identify the local distinctive regions. Furthermore, we propose a generic multi-level semantic quality evaluation module (MLSQE) to progressively supervise and enhance hierarchical semantics from different levels of the backbone network. Finally, context-aware features from MPMSCA and semantically enhanced features from MLSQE are fed into the corresponding quality probing classifiers to evaluate their quality in real-time, thus boosting the discriminability of feature representations. Comprehensive experiments on four popular and highly competitive FGVC datasets demonstrate the superiority of the proposed CSQA-Net in comparison with the state-of-the-art methods.