 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 26-Gram Butterfly-Inspired Robot Achieving Autonomous Tailless Flight
Feb 06, 2026Flapping-wing micro air vehicles (FWMAVs) have demonstrated remarkable bio-inspired agility, yet tailless two-winged configurations remain largely unexplored due to their complex fluid-structure and wing-body coupling. Here we present \textit{AirPulse}, a 26-gram butterfly-inspired FWMAV that achieves fully onboard, closed-loop, untethered flight without auxiliary control surfaces. The AirPulse robot replicates key biomechanical traits of butterfly flight, including low wing aspect ratio, compliant carbon-fiber-reinforced wings, and low-frequency, high-amplitude flapping that induces cyclic variations in the center of gravity and moment of inertia, producing characteristic body undulation. We establish a quantitative mapping between flapping modulation parameters and force-torque generation, and introduce the Stroke Timing Asymmetry Rhythm (STAR) generator, enabling smooth, stable, and linearly parameterized wingstroke asymmetry for flapping control. Integrating these with an attitude controller, the AirPulse robot maintains pitch and yaw stability despite strong oscillatory dynamics. Free-flight experiments demonstrate stable climbing and turning maneuvers via either angle offset or stroke timing modulation, marking the first onboard controlled flight of the lightest two-winged, tailless butterfly-inspired FWMAV reported in peer-reviewed literature. This work corroborates a foundational platform for lightweight, collision-proof FWMAVs, bridging biological inspiration with practical aerial robotics. Their non-invasive maneuverability is ideally suited for real-world applications, such as confined-space inspection and ecological monitoring, inaccessible to traditional drones, while their biomechanical fidelity provides a physical model to decode the principles underlying the erratic yet efficient flight of real butterflies.
Harmonizing and Merging Source Models for CLIP-based Domain Generalization
Jun 11, 2025CLIP-based domain generalization aims to improve model generalization to unseen domains by leveraging the powerful zero-shot classification capabilities of CLIP and multiple source datasets. Existing methods typically train a single model across multiple source domains to capture domain-shared information. However, this paradigm inherently suffers from two types of conflicts: 1) sample conflicts, arising from noisy samples and extreme domain shifts among sources; and 2) optimization conflicts, stemming from competition and trade-offs during multi-source training. Both hinder the generalization and lead to suboptimal solutions. Recent studies have shown that model merging can effectively mitigate the competition of multi-objective optimization and improve generalization performance. Inspired by these findings, we propose Harmonizing and Merging (HAM), a novel source model merging framework for CLIP-based domain generalization. During the training process of the source models, HAM enriches the source samples without conflicting samples, and harmonizes the update directions of all models. Then, a redundancy-aware historical model merging method is introduced to effectively integrate knowledge across all source models. HAM comprehensively consolidates source domain information while enabling mutual enhancement among source models, ultimately yielding a final model with optimal generalization capabilities. Extensive experiments on five widely used benchmark datasets demonstrate the effectiveness of our approach, achieving state-of-the-art performance.
Learning to Rank Pre-trained Vision-Language Models for Downstream Tasks
Dec 30, 2024Vision language models (VLMs) like CLIP show stellar zero-shot capability on classification benchmarks. However, selecting the VLM with the highest performance on the unlabeled downstream task is non-trivial. Existing VLM selection methods focus on the class-name-only setting, relying on a supervised large-scale dataset and large language models, which may not be accessible or feasible during deployment. This paper introduces the problem of \textbf{unsupervised vision-language model selection}, where only unsupervised downstream datasets are available, with no additional information provided. To solve this problem, we propose a method termed Visual-tExtual Graph Alignment (VEGA), to select VLMs without any annotations by measuring the alignment of the VLM between the two modalities on the downstream task. VEGA is motivated by the pretraining paradigm of VLMs, which aligns features with the same semantics from the visual and textual modalities, thereby mapping both modalities into a shared representation space. Specifically, we first construct two graphs on the vision and textual features, respectively. VEGA is then defined as the overall similarity between the visual and textual graphs at both node and edge levels. Extensive experiments across three different benchmarks, covering a variety of application scenarios and downstream datasets, demonstrate that VEGA consistently provides reliable and accurate estimates of VLMs' performance on unlabeled downstream tasks.
State Space Model for New-Generation Network Alternative to Transformers: A Survey
Apr 15, 2024In the post-deep learning era, the Transformer architecture has demonstrated its powerful performance across pre-trained big models and various downstream tasks. However, the enormous computational demands of this architecture have deterred many researchers. To further reduce the complexity of attention models, numerous efforts have been made to design more efficient methods. Among them, the State Space Model (SSM), as a possible replacement for the self-attention based Transformer model, has drawn more and more attention in recent years. In this paper, we give the first comprehensive review of these works and also provide experimental comparisons and analysis to better demonstrate the features and advantages of SSM. Specifically, we first give a detailed description of principles to help the readers quickly capture the key ideas of SSM. After that, we dive into the reviews of existing SSMs and their various applications, including natural language processing, computer vision, graph, multi-modal and multi-media, point cloud/event stream, time series data, and other domains. In addition, we give statistical comparisons and analysis of these models and hope it helps the readers to understand the effectiveness of different structures on various tasks. Then, we propose possible research points in this direction to better promote the development of the theoretical model and application of SSM. More related works will be continuously updated on the following GitHub: https://github.com/Event-AHU/Mamba_State_Space_Model_Paper_List.
Which Model to Transfer? A Survey on Transferability Estimation
Feb 23, 2024Transfer learning methods endeavor to leverage relevant knowledge from existing source pre-trained models or datasets to solve downstream target tasks. With the increase in the scale and quantity of available pre-trained models nowadays, it becomes critical to assess in advance whether they are suitable for a specific target task. Model transferability estimation is an emerging and growing area of interest, aiming to propose a metric to quantify this suitability without training them individually, which is computationally prohibitive. Despite extensive recent advances already devoted to this area, they have custom terminological definitions and experimental settings. In this survey, we present the first review of existing advances in this area and categorize them into two separate realms: source-free model transferability estimation and source-dependent model transferability estimation. Each category is systematically defined, accompanied by a comprehensive taxonomy. Besides, we address challenges and outline future research directions, intending to provide a comprehensive guide to aid researchers and practitioners.
Not all Minorities are Equal: Empty-Class-Aware Distillation for Heterogeneous Federated Learning
Jan 04, 2024



Data heterogeneity, characterized by disparities in local data distribution across clients, poses a significant challenge in federated learning. Substantial efforts have been devoted to addressing the heterogeneity in local label distribution. As minority classes suffer from worse accuracy due to overfitting on local imbalanced data, prior methods often incorporate class-balanced learning techniques during local training. Despite the improved mean accuracy across all classes, we observe that empty classes-referring to categories absent from a client's data distribution-are still not well recognized. This paper introduces FedED, a novel approach in heterogeneous federated learning that integrates both empty-class distillation and logit suppression simultaneously. Specifically, empty-class distillation leverages knowledge distillation during local training on each client to retain essential information related to empty classes from the global model. Moreover, logit suppression directly penalizes network logits for non-label classes, effectively addressing misclassifications in minority classes that may be biased toward majority classes. Extensive experiments validate the efficacy of FedED, surpassing previous state-of-the-art methods across diverse datasets with varying degrees of label distribution shift.
Unleashing the power of Neural Collapse for Transferability Estimation
Oct 09, 2023



Transferability estimation aims to provide heuristics for quantifying how suitable a pre-trained model is for a specific downstream task, without fine-tuning them all. Prior studies have revealed that well-trained models exhibit the phenomenon of Neural Collapse. Based on a widely used neural collapse metric in existing literature, we observe a strong correlation between the neural collapse of pre-trained models and their corresponding fine-tuned models. Inspired by this observation, we propose a novel method termed Fair Collapse (FaCe) for transferability estimation by comprehensively measuring the degree of neural collapse in the pre-trained model. Typically, FaCe comprises two different terms: the variance collapse term, which assesses the class separation and within-class compactness, and the class fairness term, which quantifies the fairness of the pre-trained model towards each class. We investigate FaCe on a variety of pre-trained classification models across different network architectures, source datasets, and training loss functions. Results show that FaCe yields state-of-the-art performance on different tasks including image classification, semantic segmentation, and text classification, which demonstrate the effectiveness and generalization of our method.
MODIFY: Model-driven Face Stylization without Style Images
Mar 17, 2023Existing face stylization methods always acquire the presence of the target (style) domain during the translation process, which violates privacy regulations and limits their applicability in real-world systems. To address this issue, we propose a new method called MODel-drIven Face stYlization (MODIFY), which relies on the generative model to bypass the dependence of the target images. Briefly, MODIFY first trains a generative model in the target domain and then translates a source input to the target domain via the provided style model. To preserve the multimodal style information, MODIFY further introduces an additional remapping network, mapping a known continuous distribution into the encoder's embedding space. During translation in the source domain, MODIFY fine-tunes the encoder module within the target style-persevering model to capture the content of the source input as precisely as possible. Our method is extremely simple and satisfies versatile training modes for face stylization. Experimental results on several different datasets validate the effectiveness of MODIFY for unsupervised face stylization.
MAPS: A Noise-Robust Progressive Learning Approach for Source-Free Domain Adaptive Keypoint Detection
Feb 09, 2023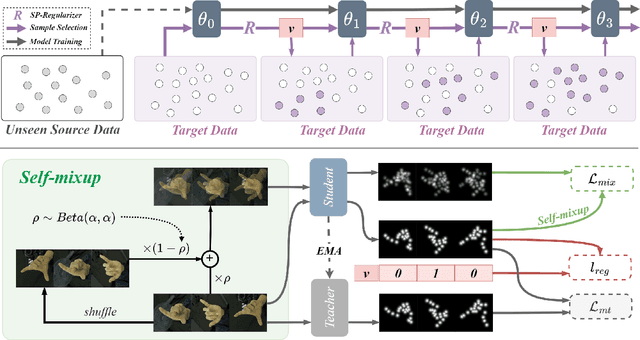
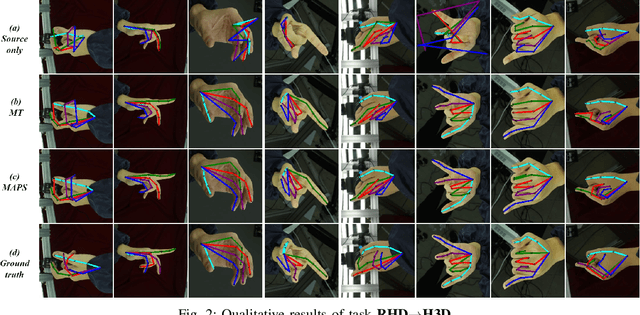

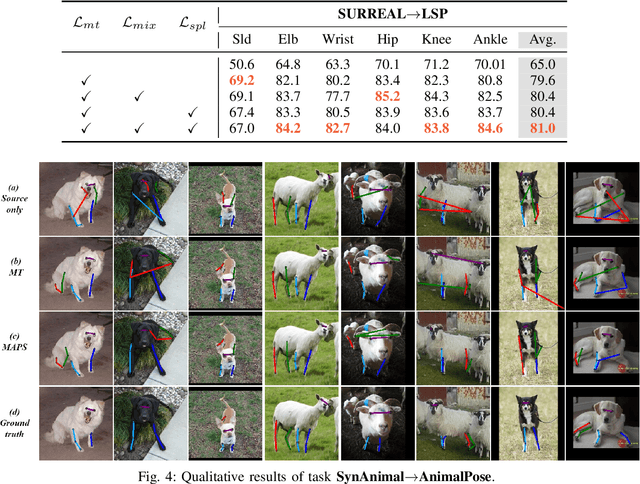
Existing cross-domain keypoint detection methods always require accessing the source data during adaptation, which may violate the data privacy law and pose serious security concerns. Instead, this paper considers a realistic problem setting called source-free domain adaptive keypoint detection, where only the well-trained source model is provided to the target domain. For the challenging problem, we first construct a teacher-student learning baseline by stabilizing the predictions under data augmentation and network ensembles. Built on this, we further propose a unified approach, Mixup Augmentation and Progressive Selection (MAPS), to fully exploit the noisy pseudo labels of unlabeled target data during training. On the one hand, MAPS regularizes the model to favor simple linear behavior in-between the target samples via self-mixup augmentation, preventing the model from over-fitting to noisy predictions. On the other hand, MAPS employs the self-paced learning paradigm and progressively selects pseudo-labeled samples from `easy' to `hard' into the training process to reduce noise accumulation. Results on four keypoint detection datasets show that MAPS outperforms the baseline and achieves comparable or even better results in comparison to previous non-source-free counterparts.
ProxyMix: Proxy-based Mixup Training with Label Refinery for Source-Free Domain Adaptation
May 29, 2022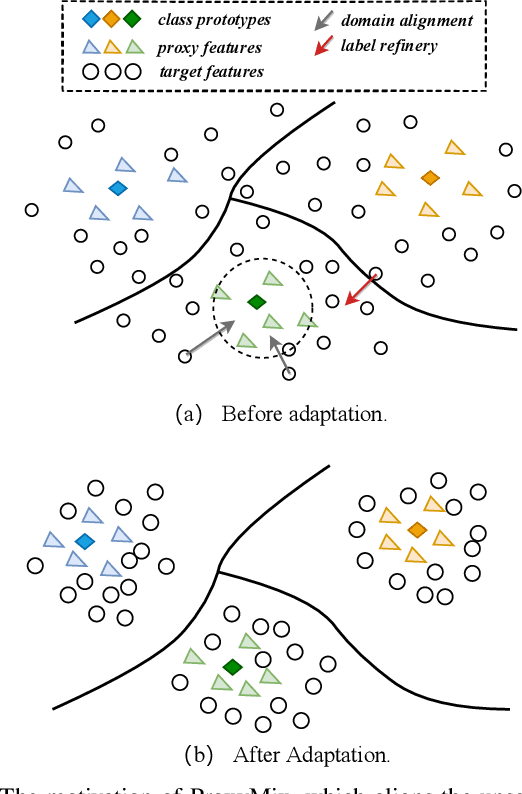
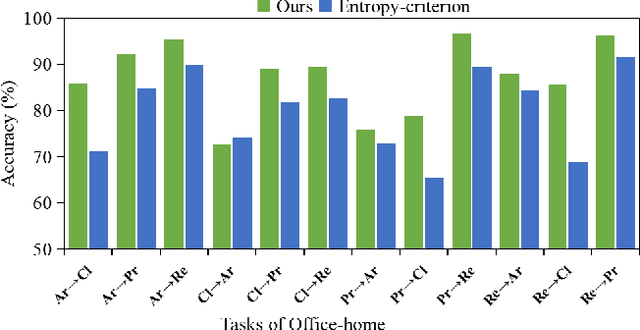
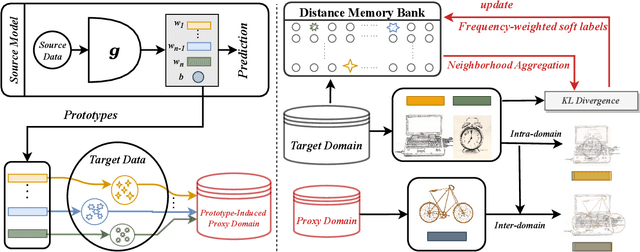
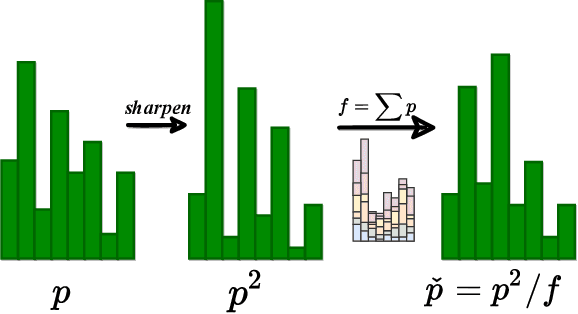
Unsupervised domain adaptation (UDA) aims to transfer knowledge from a labeled source domain to an unlabeled target domain. Owing to privacy concerns and heavy data transmission, source-free UDA, exploiting the pre-trained source models instead of the raw source data for target learning, has been gaining popularity in recent years. Some works attempt to recover unseen source domains with generative models, however introducing additional network parameters. Other works propose to fine-tune the source model by pseudo labels, while noisy pseudo labels may misguide the decision boundary, leading to unsatisfied results. To tackle these issues, we propose an effective method named Proxy-based Mixup training with label refinery (ProxyMix). First of all, to avoid additional parameters and explore the information in the source model, ProxyMix defines the weights of the classifier as the class prototypes and then constructs a class-balanced proxy source domain by the nearest neighbors of the prototypes to bridge the unseen source domain and the target domain. To improve the reliability of pseudo labels, we further propose the frequency-weighted aggregation strategy to generate soft pseudo labels for unlabeled target data. The proposed strategy exploits the internal structure of target features, pulls target features to their semantic neighbors, and increases the weights of low-frequency classes samples during gradient updating. With the proxy domain and the reliable pseudo labels, we employ two kinds of mixup regularization, i.e., inter- and intra-domain mixup, in our framework, to align the proxy and the target domain, enforcing the consistency of predictions, thereby further mitigating the negative impacts of noisy labels. Experiments on three 2D image and one 3D point cloud object recognition benchmarks demonstrate that ProxyMix yields state-of-the-art performance for source-free UDA tasks.