 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPS: A Noise-Robust Progressive Learning Approach for Source-Free Domain Adaptive Keypoint Detection
Paper and Code
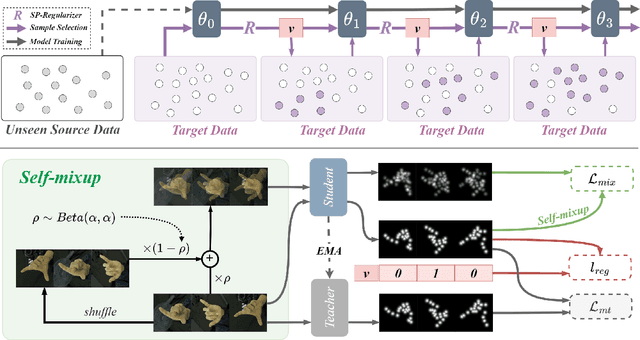
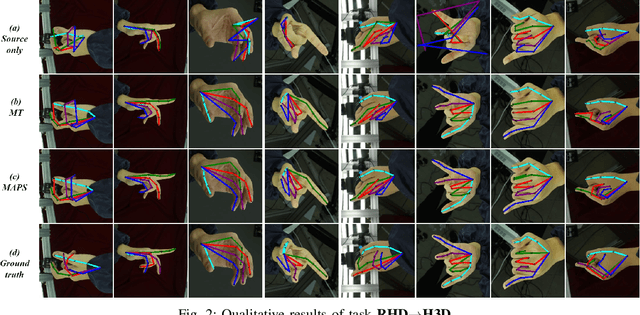

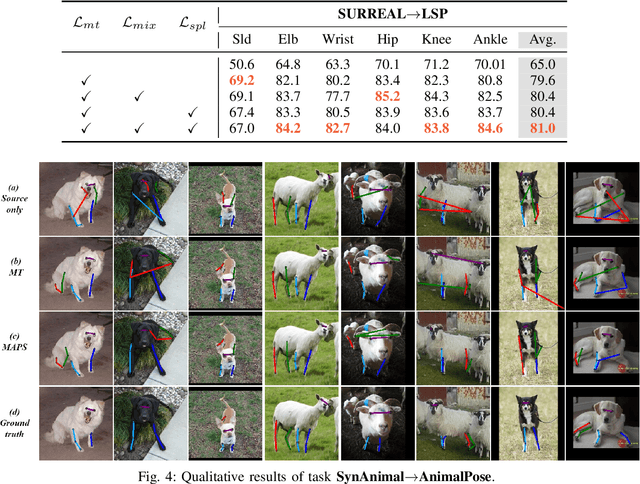
Existing cross-domain keypoint detection methods always require accessing the source data during adaptation, which may violate the data privacy law and pose serious security concerns. Instead, this paper considers a realistic problem setting called source-free domain adaptive keypoint detection, where only the well-trained source model is provided to the target domain. For the challenging problem, we first construct a teacher-student learning baseline by stabilizing the predictions under data augmentation and network ensembles. Built on this, we further propose a unified approach, Mixup Augmentation and Progressive Selection (MAPS), to fully exploit the noisy pseudo labels of unlabeled target data during training. On the one hand, MAPS regularizes the model to favor simple linear behavior in-between the target samples via self-mixup augmentation, preventing the model from over-fitting to noisy predictions. On the other hand, MAPS employs the self-paced learning paradigm and progressively selects pseudo-labeled samples from `easy' to `hard' into the training process to reduce noise accumulation. Results on four keypoint detection datasets show that MAPS outperforms the baseline and achieves comparable or even better results in comparison to previous non-source-free counterparts.