 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Speech Tokenizers with Diffusion Autoencoders
Feb 06, 2026Speech tokenizers are foundational to speech language models, yet existing approaches face two major challenges: (1) balancing trade-offs between encoding semantics for understanding and acoustics for reconstruction, and (2) achieving low bit rates and low token rates. We propose Speech Diffusion Tokenizer (SiTok), a diffusion autoencoder that jointly learns semantic-rich representations through supervised learning and enables high-fidelity audio reconstruction with diffusion. We scale SiTok to 1.6B parameters and train it on 2 million hours of speech. Experiments show that SiTok outperforms strong baselines on understanding, reconstruction and generation tasks, at an extremely low token rate of $12.5$ Hz and a bit-rate of 200 bits-per-second.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Vevo: Controllable Zero-Shot Voice Imitation with Self-Supervised Disentanglement
Feb 11, 2025The imitation of voice, targeted on specific speech attributes such as timbre and speaking style, is crucial in speech generation. However, existing methods rely heavily on annotated data, and struggle with effectively disentangling timbre and style, leading to challenges in achieving controllable generation, especially in zero-shot scenarios. To address these issues, we propose Vevo, a versatile zero-shot voice imitation framework with controllable timbre and style. Vevo operates in two core stages: (1) Content-Style Modeling: Given either text or speech's content tokens as input, we utilize an autoregressive transformer to generate the content-style tokens, which is prompted by a style reference; (2) Acoustic Modeling: Given the content-style tokens as input, we employ a flow-matching transformer to produce acoustic representations, which is prompted by a timbre reference. To obtain the content and content-style tokens of speech, we design a fully self-supervised approach that progressively decouples the timbre, style, and linguistic content of speech. Specifically, we adopt VQ-VAE as the tokenizer for the continuous hidden features of HuBERT. We treat the vocabulary size of the VQ-VAE codebook as the information bottleneck, and adjust it carefully to obtain the disentangled speech representations. Solely self-supervised trained on 60K hours of audiobook speech data, without any fine-tuning on style-specific corpora, Vevo matches or surpasses existing methods in accent and emotion conversion tasks. Additionally, Vevo's effectiveness in zero-shot voice conversion and text-to-speech tasks further demonstrates its strong generalization and versatility. Audio samples are available at https://versavoice.github.io.
ReFormer: The Relational Transformer for Image Captioning
Jul 29, 2021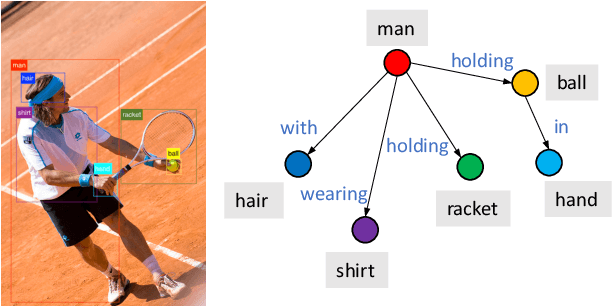
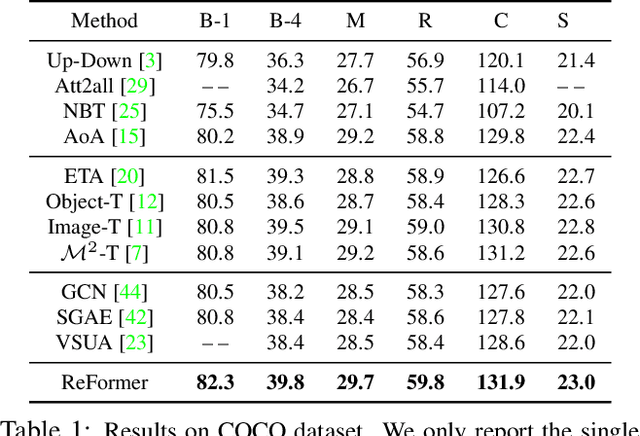
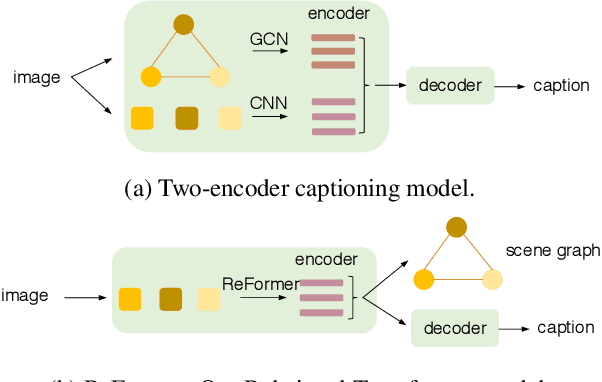
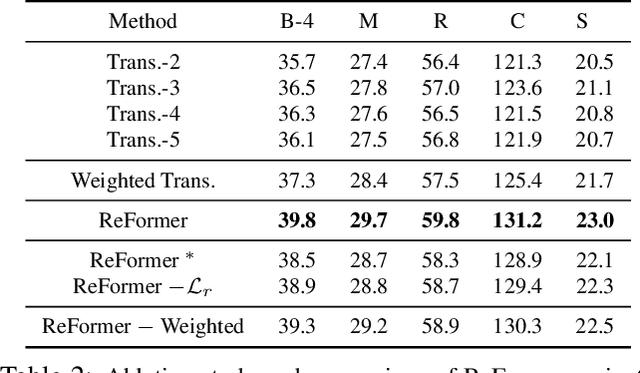
Image captioning is shown to be able to achieve a better performance by using scene graphs to represent the relations of objects in the image. The current captioning encoders generally use a Graph Convolutional Net (GCN) to represent the relation information and merge it with the object region features via concatenation or convolution to get the final input for sentence decoding. However, the GCN-based encoders in the existing methods are less effective for captioning due to two reasons. First, using the image captioning as the objective (i.e., Maximum Likelihood Estimation) rather than a relation-centric loss cannot fully explore the potential of the encoder. Second, using a pre-trained model instead of the encoder itself to extract the relationships is not flexible and cannot contribute to the explainability of the model. To improve the quality of image captioning, we propose a novel architecture ReFormer -- a RElational transFORMER to generate features with relation information embedded and to explicitly express the pair-wise relationships between objects in the image. ReFormer incorporates the objective of scene graph generation with that of image captioning using one modified Transformer model. This design allows ReFormer to generate not only better image captions with the bene-fit of extracting strong relational image features, but also scene graphs to explicitly describe the pair-wise relation-ships. Experiments on publicly available datasets show that our model significantly outperforms state-of-the-art methods on image captioning and scene graph generation
Cubic Spline Smoothing Compensation for Irregularly Sampled Sequences
Oct 03, 2020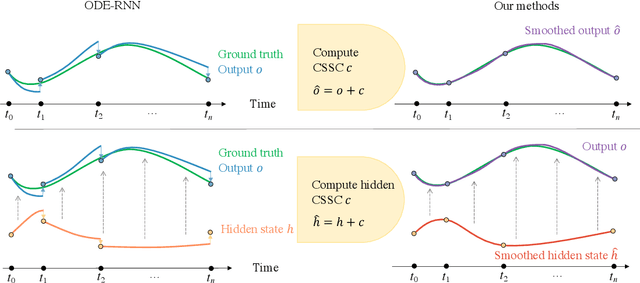
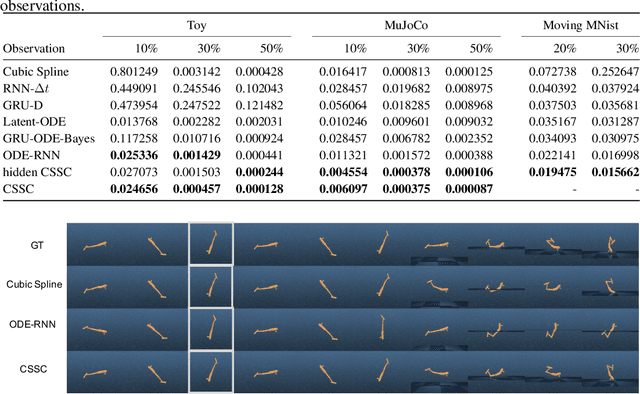
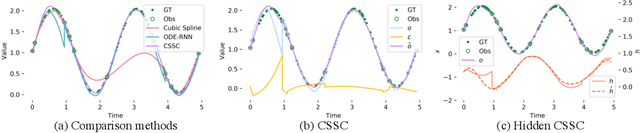
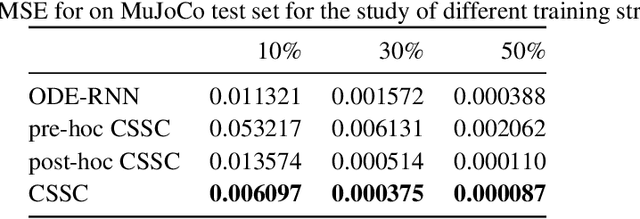
The marriage of recurrent neural networks and neural ordinary differential networks (ODE-RNN) is effective in modeling irregularly-observed sequences. While ODE produces the smooth hidden states between observation intervals, the RNN will trigger a hidden state jump when a new observation arrives, thus cause the interpolation discontinuity problem. To address this issue, we propose the cubic spline smoothing compensation, which is a stand-alone module upon either the output or the hidden state of ODE-RNN and can be trained end-to-end. We derive its analytical solution and provide its theoretical interpolation error bound. Extensive experiments indicate its merits over both ODE-RNN and cubic spline interpolation.
Fashion Captioning: Towards Generating Accurate Descriptions with Semantic Rewards
Aug 06, 2020
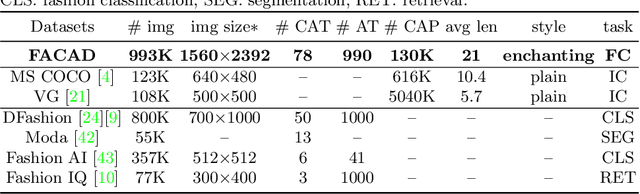
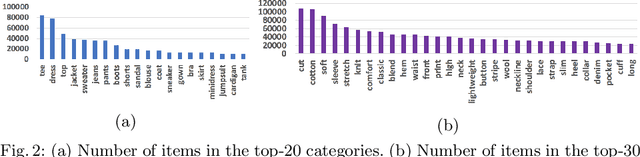
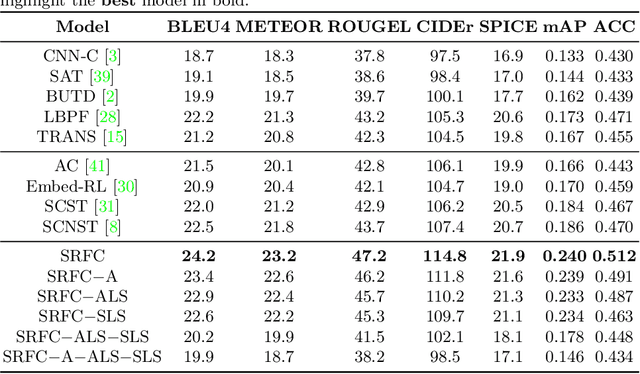
Generating accurate descriptions for online fashion items is important not only for enhancing customers' shopping experiences, but also for the increase of online sales. Besides the need of correctly presenting the attributes of items, the expressions in an enchanting style could better attract customer interests. The goal of this work is to develop a novel learning framework for accurate and expressive fashion captioning. Different from popular work on image captioning, it is hard to identify and describe the rich attributes of fashion items. We seed the description of an item by first identifying its attributes, and introduce attribute-level semantic (ALS) reward and sentence-level semantic (SLS) reward as metrics to improve the quality of text descriptions. We further integrate the training of our model with maximum likelihood estimation (MLE), attribute embedding, and Reinforcement Learning (RL). To facilitate the learning, we build a new FAshion CAptioning Dataset (FACAD), which contains 993K images and 130K corresponding enchanting and diverse descriptions. Experiments on FACAD demonstrate the effectiveness of our model.
Learning Continuous-Time Dynamics by Stochastic Differential Networks
Jun 11, 2020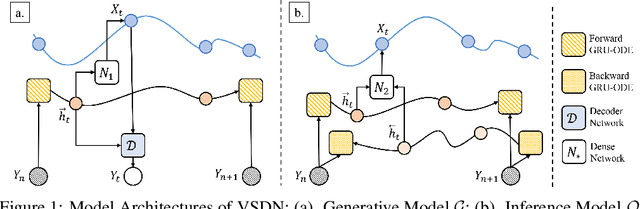
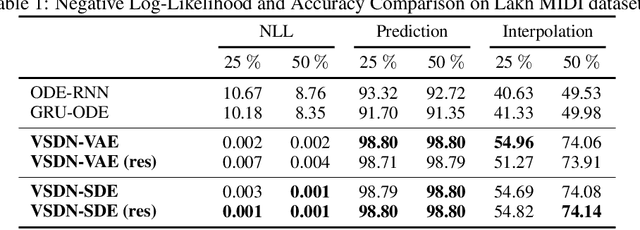
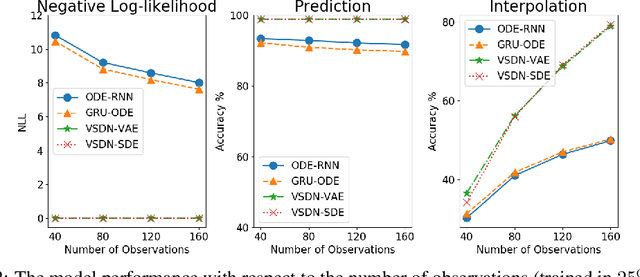
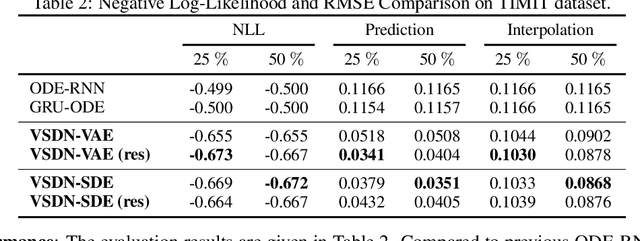
Learning continuous-time stochastic dynamics from sparse or irregular observations is a fundamental and essential problem for many real-world applications. However, for a given system whose latent states and observed data are high-dimensional, it is generally impossible to derive a precise continuous-time stochastic process to describe the system behaviors. To solve the above problem, we apply Variational Bayesian method and propose a flexible continuous-time framework named Variational Stochastic Differential Networks (VSDN), which can model high-dimensional nonlinear stochastic dynamics by deep neural networks. VSDN introduces latent states to modulate the estimated distribution and defines two practical methods to model the stochastic dependency between observations and the states. The first variant, which is called VSDN-VAE, incorporates sequential Variational Auto-Encoder (VAE) to efficiently model the distribution of the latent states. The second variant, called VSDN-SDE, further extends the model capacity of VSDN-VAE by learning a set of Stochastic Differential Equations (SDEs) to fully describe the state transitions. Through comprehensive experiments on symbolic MIDI and speech datasets, we show that VSDNs can accurately model the continuous-time dynamics and achieve remarkable performance on challenging tasks, including online prediction and sequence interpolation.
Adaptive Activation Network and Functional Regularization for Efficient and Flexible Deep Multi-Task Learning
Nov 19, 2019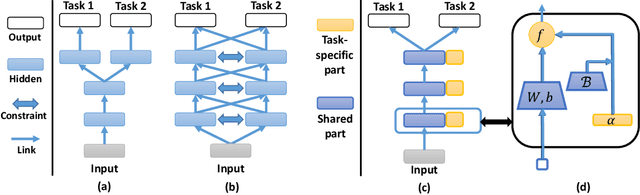
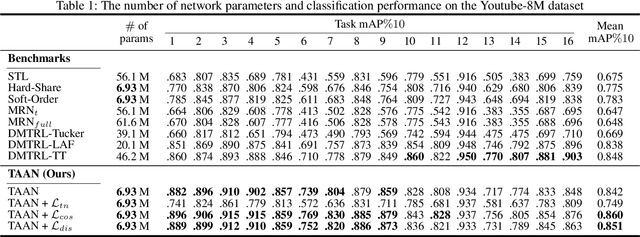
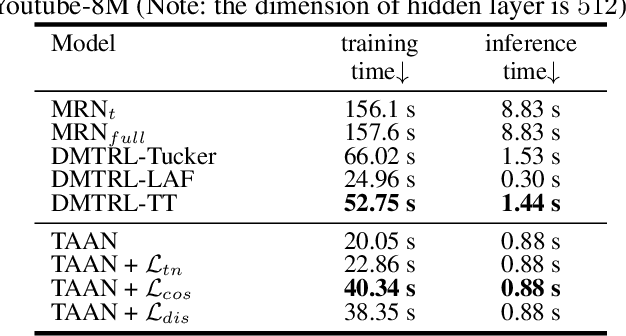
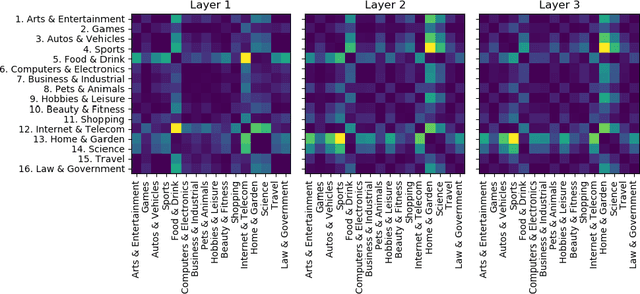
Multi-task learning (MTL) is a common paradigm that seeks to improve the generalization performance of task learning by training related tasks simultaneously. However, it is still a challenging problem to search the flexible and accurate architecture that can be shared among multiple tasks. In this paper, we propose a novel deep learning model called Task Adaptive Activation Network (TAAN) that can automatically learn the optimal network architecture for MTL. The main principle of TAAN is to derive flexible activation functions for different tasks from the data with other parameters of the network fully shared. We further propose two functional regularization methods that improve the MTL performance of TAAN. The improved performance of both TAAN and the regularization methods is demonstrated by comprehensive experiments.
Latent Part-of-Speech Sequences for Neural Machine Translation
Aug 30, 2019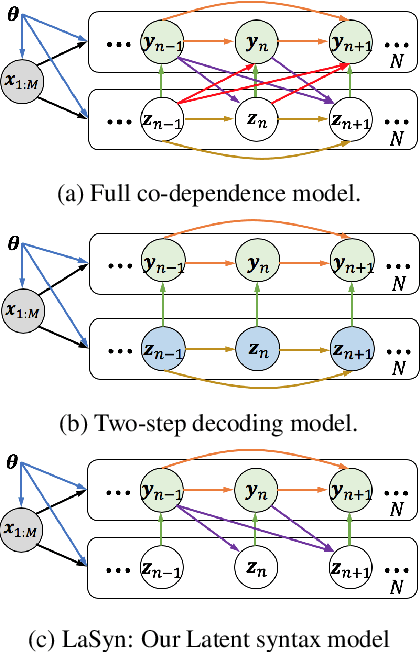
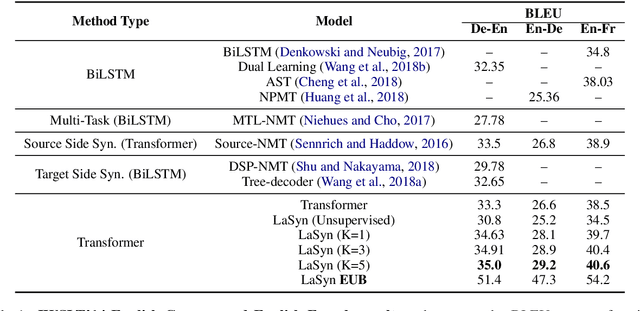
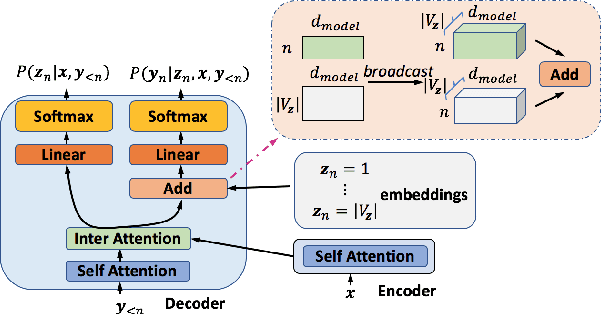

Learning target side syntactic structure has been shown to improve Neural Machine Translation (NMT). However, incorporating syntax through latent variables introduces additional complexity in inference, as the models need to marginalize over the latent syntactic structures. To avoid this, models often resort to greedy search which only allows them to explore a limited portion of the latent space. In this work, we introduce a new latent variable model, LaSyn, that captures the co-dependence between syntax and semantics, while allowing for effective and efficient inference over the latent space. LaSyn decouples direct dependence between successive latent variables, which allows its decoder to exhaustively search through the latent syntactic choices, while keeping decoding speed proportional to the size of the latent variable vocabulary. We implement LaSyn by modifying a transformer-based NMT system and design a neural expectation maximization algorithm that we regularize with part-of-speech information as the latent sequences. Evaluations on four different MT tasks show that incorporating target side syntax with LaSyn improves both translation quality, and also provides an opportunity to improve diversity.