 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScoutAttention: Efficient KV Cache Offloading via Layer-Ahead CPU Pre-computation for LLM Inference
Mar 28, 2026Large language models encounter critical GPU memory capacity constraints during long-context inference, where KV cache memory consumption severely limits decode batch sizes. While existing research has explored offloading KV cache to DRAM, these approaches either demand frequent GPU-CPU data transfers or impose extensive CPU computation requirements, resulting in poor GPU utilization as the system waits for I/O operations or CPU processing to complete. We propose ScoutAttention, a novel KV cache offloading framework that accelerates LLM inference through collaborative GPU-CPU attention computation. To prevent CPU computation from bottlenecking the system, ScoutAttention introduces GPU-CPU collaborative block-wise sparse attention that significantly reduces CPU load. Unlike conventional parallel computing approaches, our framework features a novel layer-ahead CPU pre-computation algorithm, enabling the CPU to initiate attention computation one layer in advance, complemented by asynchronous periodic recall mechanisms to maintain minimal CPU compute load. Experimental results demonstrate that ScoutAttention maintains accuracy within 2.4% of baseline while achieving 2.1x speedup compared to existing offloading methods.
CycleVLA: Proactive Self-Correcting Vision-Language-Action Models via Subtask Backtracking and Minimum Bayes Risk Decoding
Jan 05, 2026Current work on robot failure detection and correction typically operate in a post hoc manner, analyzing errors and applying corrections only after failures occur. This work introduces CycleVLA, a system that equips Vision-Language-Action models (VLAs) with proactive self-correction, the capability to anticipate incipient failures and recover before they fully manifest during execution. CycleVLA achieves this by integrating a progress-aware VLA that flags critical subtask transition points where failures most frequently occur, a VLM-based failure predictor and planner that triggers subtask backtracking upon predicted failure, and a test-time scaling strategy based on Minimum Bayes Risk (MBR) decoding to improve retry success after backtracking. Extensive experiments show that CycleVLA improves performance for both well-trained and under-trained VLAs, and that MBR serves as an effective zero-shot test-time scaling strategy for VLAs. Project Page: https://dannymcy.github.io/cyclevla/
DeepGo: Predictive Directed Greybox Fuzzing
Jul 29, 2025The state-of-the-art DGF techniques redefine and optimize the fitness metric to reach the target sites precisely and quickly. However, optimizations for fitness metrics are mainly based on heuristic algorithms, which usually rely on historical execution information and lack foresight on paths that have not been exercised yet. Thus, those hard-to-execute paths with complex constraints would hinder DGF from reaching the targets, making DGF less efficient. In this paper, we propose DeepGo, a predictive directed grey-box fuzzer that can combine historical and predicted information to steer DGF to reach the target site via an optimal path. We first propose the path transition model, which models DGF as a process of reaching the target site through specific path transition sequences. The new seed generated by mutation would cause the path transition, and the path corresponding to the high-reward path transition sequence indicates a high likelihood of reaching the target site through it. Then, to predict the path transitions and the corresponding rewards, we use deep neural networks to construct a Virtual Ensemble Environment (VEE), which gradually imitates the path transition model and predicts the rewards of path transitions that have not been taken yet. To determine the optimal path, we develop a Reinforcement Learning for Fuzzing (RLF) model to generate the transition sequences with the highest sequence rewards. The RLF model can combine historical and predicted path transitions to generate the optimal path transition sequences, along with the policy to guide the mutation strategy of fuzzing. Finally, to exercise the high-reward path transition sequence, we propose the concept of an action group, which comprehensively optimizes the critical steps of fuzzing to realize the optimal path to reach the target efficiently.
MoQAE: Mixed-Precision Quantization for Long-Context LLM Inference via Mixture of Quantization-Aware Experts
Jun 09, 2025One of the primary challenges in optimizing large language models (LLMs) for long-context inference lies in the high memory consumption of the Key-Value (KV) cache. Existing approaches, such as quantization, have demonstrated promising results in reducing memory usage. However, current quantization methods cannot take both effectiveness and efficiency into account. In this paper, we propose MoQAE, a novel mixed-precision quantization method via mixture of quantization-aware experts. First, we view different quantization bit-width configurations as experts and use the traditional mixture of experts (MoE) method to select the optimal configuration. To avoid the inefficiency caused by inputting tokens one by one into the router in the traditional MoE method, we input the tokens into the router chunk by chunk. Second, we design a lightweight router-only fine-tuning process to train MoQAE with a comprehensive loss to learn the trade-off between model accuracy and memory usage. Finally, we introduce a routing freezing (RF) and a routing sharing (RS) mechanism to further reduce the inference overhead. Extensive experiments on multiple benchmark datasets demonstrate that our method outperforms state-of-the-art KV cache quantization approaches in both efficiency and effectiveness.
MADLLM: Multivariate Anomaly Detection via Pre-trained LLMs
Apr 13, 2025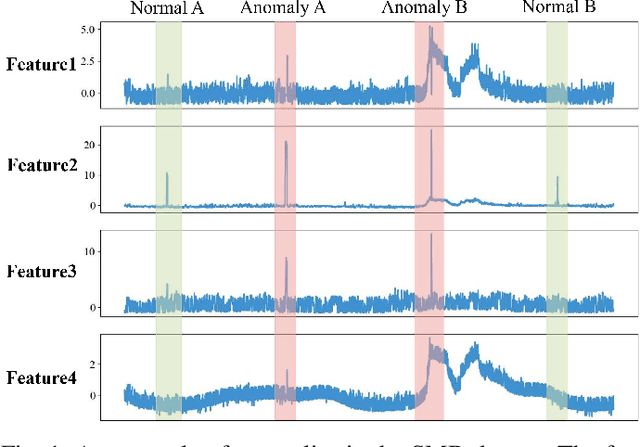
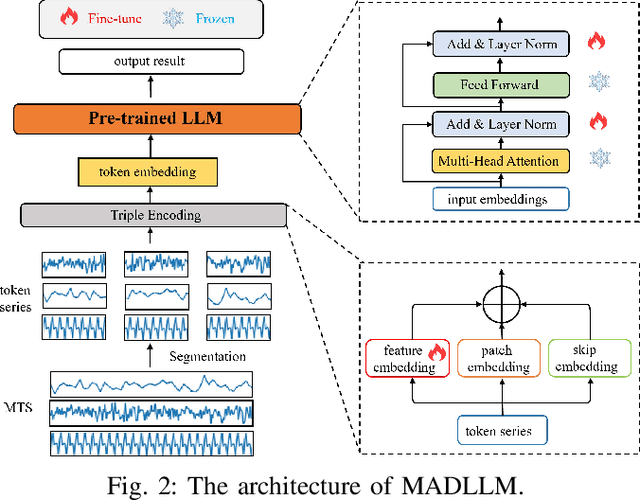
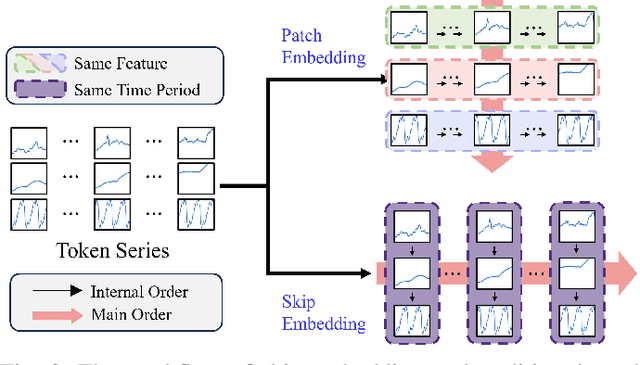
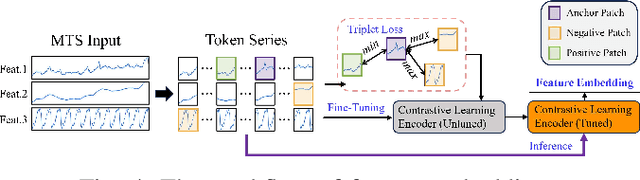
When applying pre-trained large language models (LLMs) to address anomaly detection tasks, the multivariate time series (MTS) modality of anomaly detection does not align with the text modality of LLMs. Existing methods simply transform the MTS data into multiple univariate time series sequences, which can cause many problems. This paper introduces MADLLM, a novel multivariate anomaly detection method via pre-trained LLMs. We design a new triple encoding technique to align the MTS modality with the text modality of LLMs. Specifically, this technique integrates the traditional patch embedding method with two novel embedding approaches: Skip Embedding, which alters the order of patch processing in traditional methods to help LLMs retain knowledge of previous features, and Feature Embedding, which leverages contrastive learning to allow the model to better understand the correlations between different features. Experimental results demonstrate that our method outperforms state-of-the-art methods in various public anomaly detection datasets.
RUNA: Object-level Out-of-Distribution Detection via Regional Uncertainty Alignment of Multimodal Representations
Mar 28, 2025Enabling object detectors to recognize out-of-distribution (OOD) objects is vital for building reliable systems. A primary obstacle stems from the fact that models frequently do not receive supervisory signals from unfamiliar data, leading to overly confident predictions regarding OOD objects. Despite previous progress that estimates OOD uncertainty based on the detection model and in-distribution (ID) samples, we explore using pre-trained vision-language representations for object-level OOD detection. We first discuss the limitations of applying image-level CLIP-based OOD detection methods to object-level scenarios. Building upon these insights, we propose RUNA, a novel framework that leverages a dual encoder architecture to capture rich contextual information and employs a regional uncertainty alignment mechanism to distinguish ID from OOD objects effectively. We introduce a few-shot fine-tuning approach that aligns region-level semantic representations to further improve the model's capability to discriminate between similar objects. Our experiments show that RUNA substantially surpasses state-of-the-art methods in object-level OOD detection, particularly in challenging scenarios with diverse and complex object instances.
RefSAM3D: Adapting SAM with Cross-modal Reference for 3D Medical Image Segmentation
Dec 07, 2024The Segment Anything Model (SAM), originally built on a 2D Vision Transformer (ViT), excels at capturing global patterns in 2D natural images but struggles with 3D medical imaging modalities like CT and MRI. These modalities require capturing spatial information in volumetric space for tasks such as organ segmentation and tumor quantification. To address this challenge, we introduce RefSAM3D, which adapts SAM for 3D medical imaging by incorporating a 3D image adapter and cross-modal reference prompt generation. Our approach modifies the visual encoder to handle 3D inputs and enhances the mask decoder for direct 3D mask generation. We also integrate textual prompts to improve segmentation accuracy and consistency in complex anatomical scenarios. By employing a hierarchical attention mechanism, our model effectively captures and integrates information across different scales. Extensive evaluations on multiple medical imaging datasets demonstrate the superior performance of RefSAM3D over state-of-the-art methods. Our contributions advance the application of SAM in accurately segmenting complex anatomical structures in medical imaging.
Hammer: Towards Efficient Hot-Cold Data Identification via Online Learning
Nov 22, 2024Efficient management of storage resources in big data and cloud computing environments requires accurate identification of data's "cold" and "hot" states. Traditional methods, such as rule-based algorithms and early AI techniques, often struggle with dynamic workloads, leading to low accuracy, poor adaptability, and high operational overhead. To address these issues, we propose a novel solution based on online learning strategies. Our approach dynamically adapts to changing data access patterns, achieving higher accuracy and lower operational costs. Rigorous testing with both synthetic and real-world datasets demonstrates a significant improvement, achieving a 90% accuracy rate in hot-cold classification. Additionally, the computational and storage overheads are considerably reduced.
InteLiPlan: Interactive Lightweight LLM-Based Planner for Domestic Robot Autonomy
Sep 22, 2024We introduce a lightweight LLM-based framework designed to enhance the autonomy and robustness of domestic robots, targeting onboard embodied intelligence. By addressing challenges such as kinematic constraints and dynamic environments, our approach reduces reliance on large-scale data and incorporates a robot-agnostic pipeline. Our framework, InteLiPlan, ensures that the LLM model's decision-making capabilities are effectively aligned with robotic functions, enhancing operational robustness and adaptability, while our human-in-the-loop mechanism allows for real-time human intervention in the case where the system fails. We evaluate our method in both simulation and on the real Toyota HSR robot. The results show that our method achieves a 93% success rate in the fetch me task completion with system failure recovery, outperforming the baseline method in a domestic environment. InteLiPlan achieves comparable performance to the state-of-the-art large-scale LLM-based robotics planner, while guaranteeing real-time onboard computing with embodied intelligence.
See, Imagine, Plan: Discovering and Hallucinating Tasks from a Single Image
Mar 24, 2024



Humans can not only recognize and understand the world in its current state but also envision future scenarios that extend beyond immediate perception. To resemble this profound human capacity, we introduce zero-shot task hallucination -- given a single RGB image of any scene comprising unknown environments and objects, our model can identify potential tasks and imagine their execution in a vivid narrative, realized as a video. We develop a modular pipeline that progressively enhances scene decomposition, comprehension, and reconstruction, incorporating VLM for dynamic interaction and 3D motion planning for object trajectories. Our model can discover diverse tasks, with the generated task videos demonstrating realistic and compelling visual outcomes that are understandable by both machines and humans. Project Page: https://dannymcy.github.io/zeroshot_task_hallucination/