 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRENet: A Plane-Fit Redundancy Encoding Point Cloud Sequence Network for Real-Time 3D Action Recognition
May 11, 2024Recognizing human actions from point cloud sequence has attracted tremendous attention from both academia and industry due to its wide applications. However, most previous studies on point cloud action recognition typically require complex networks to extract intra-frame spatial features and inter-frame temporal features, resulting in an excessive number of redundant computations. This leads to high latency, rendering them impractical for real-world applications. To address this problem, we propose a Plane-Fit Redundancy Encoding point cloud sequence network named PRENet. The primary concept of our approach involves the utilization of plane fitting to mitigate spatial redundancy within the sequence, concurrently encoding the temporal redundancy of the entire sequence to minimize redundant computations. Specifically, our network comprises two principal modules: a Plane-Fit Embedding module and a Spatio-Temporal Consistency Encoding module. The Plane-Fit Embedding module capitalizes on the observation that successive point cloud frames exhibit unique geometric features in physical space, allowing for the reuse of spatially encoded data for temporal stream encoding. The Spatio-Temporal Consistency Encoding module amalgamates the temporal structure of the temporally redundant part with its corresponding spatial arrangement, thereby enhancing recognition accuracy. We have done numerous experiments to verify the effectiveness of our network. The experimental results demonstrate that our method achieves almost identical recognition accuracy while being nearly four times faster than other state-of-the-art methods.
Value-Driven Mixed-Precision Quantization for Patch-Based Inference on Microcontrollers
Jan 24, 2024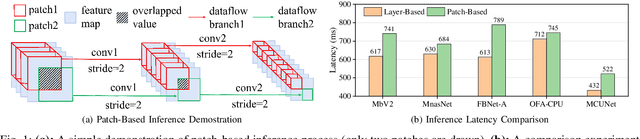
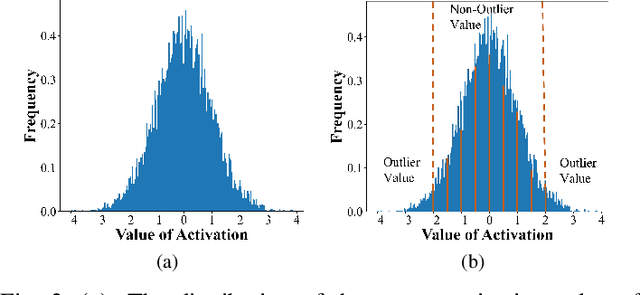
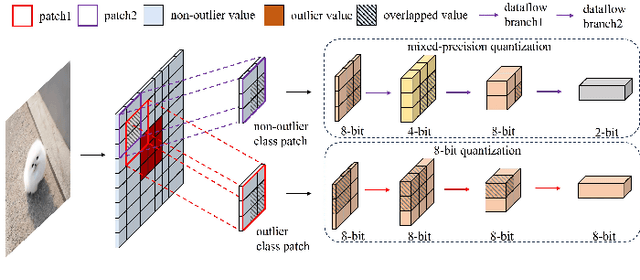
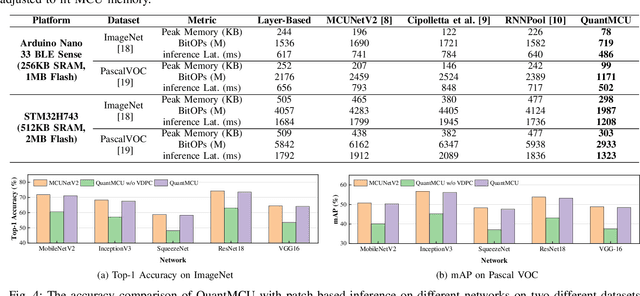
Deploying neural networks on microcontroller units (MCUs) presents substantial challenges due to their constrained computation and memory resources. Previous researches have explored patch-based inference as a strategy to conserve memory without sacrificing model accuracy. However, this technique suffers from severe redundant computation overhead, leading to a substantial increase in execution latency. A feasible solution to address this issue is mixed-precision quantization, but it faces the challenges of accuracy degradation and a time-consuming search time. In this paper, we propose QuantMCU, a novel patch-based inference method that utilizes value-driven mixed-precision quantization to reduce redundant computation. We first utilize value-driven patch classification (VDPC) to maintain the model accuracy. VDPC classifies patches into two classes based on whether they contain outlier values. For patches containing outlier values, we apply 8-bit quantization to the feature maps on the dataflow branches that follow. In addition, for patches without outlier values, we utilize value-driven quantization search (VDQS) on the feature maps of their following dataflow branches to reduce search time. Specifically, VDQS introduces a novel quantization search metric that takes into account both computation and accuracy, and it employs entropy as an accuracy representation to avoid additional training. VDQS also adopts an iterative approach to determine the bitwidth of each feature map to further accelerate the search process. Experimental results on real-world MCU devices show that QuantMCU can reduce computation by 2.2x on average while maintaining comparable model accuracy compared to the state-of-the-art patch-based inference methods.