 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScoutAttention: Efficient KV Cache Offloading via Layer-Ahead CPU Pre-computation for LLM Inference
Mar 28, 2026Large language models encounter critical GPU memory capacity constraints during long-context inference, where KV cache memory consumption severely limits decode batch sizes. While existing research has explored offloading KV cache to DRAM, these approaches either demand frequent GPU-CPU data transfers or impose extensive CPU computation requirements, resulting in poor GPU utilization as the system waits for I/O operations or CPU processing to complete. We propose ScoutAttention, a novel KV cache offloading framework that accelerates LLM inference through collaborative GPU-CPU attention computation. To prevent CPU computation from bottlenecking the system, ScoutAttention introduces GPU-CPU collaborative block-wise sparse attention that significantly reduces CPU load. Unlike conventional parallel computing approaches, our framework features a novel layer-ahead CPU pre-computation algorithm, enabling the CPU to initiate attention computation one layer in advance, complemented by asynchronous periodic recall mechanisms to maintain minimal CPU compute load. Experimental results demonstrate that ScoutAttention maintains accuracy within 2.4% of baseline while achieving 2.1x speedup compared to existing offloading methods.
Vista: Scene-Aware Optimization for Streaming Video Question Answering under Post-Hoc Queries
Feb 09, 2026Streaming video question answering (Streaming Video QA) poses distinct challenges for multimodal large language models (MLLMs), as video frames arrive sequentially and user queries can be issued at arbitrary time points. Existing solutions relying on fixed-size memory or naive compression often suffer from context loss or memory overflow, limiting their effectiveness in long-form, real-time scenarios. We present Vista, a novel framework for scene-aware streaming video QA that enables efficient and scalable reasoning over continuous video streams. The innovation of Vista can be summarized in three aspects: (1) scene-aware segmentation, where Vista dynamically clusters incoming frames into temporally and visually coherent scene units; (2) scene-aware compression, where each scene is compressed into a compact token representation and stored in GPU memory for efficient index-based retrieval, while full-resolution frames are offloaded to CPU memory; and (3) scene-aware recall, where relevant scenes are selectively recalled and reintegrated into the model input upon receiving a query, enabling both efficiency and completeness. Vista is model-agnostic and integrates seamlessly with a variety of vision-language backbones, enabling long-context reasoning without compromising latency or memory efficiency. Extensive experiments on StreamingBench demonstrate that Vista achieves state-of-the-art performance, establishing a strong baseline for real-world streaming video understanding.
Triage: Hierarchical Visual Budgeting for Efficient Video Reasoning in Vision-Language Models
Jan 30, 2026Vision-Language Models (VLMs) face significant computational challenges in video processing due to massive data redundancy, which creates prohibitively long token sequences. To address this, we introduce Triage, a training-free, plug-and-play framework that reframes video reasoning as a resource allocation problem via hierarchical visual budgeting. Its first stage, Frame-Level Budgeting, identifies keyframes by evaluating their visual dynamics and relevance, generating a strategic prior based on their importance scores. Guided by this prior, the second stage, Token-Level Budgeting, allocates tokens in two phases: it first secures high-relevance Core Tokens, followed by diverse Context Tokens selected with an efficient batched Maximal Marginal Relevance (MMR) algorithm. Extensive experiments demonstrate that Triage improves inference speed and reduces memory footprint, while maintaining or surpassing the performance of baselines and other methods on various video reasoning benchmarks.
MoQAE: Mixed-Precision Quantization for Long-Context LLM Inference via Mixture of Quantization-Aware Experts
Jun 09, 2025One of the primary challenges in optimizing large language models (LLMs) for long-context inference lies in the high memory consumption of the Key-Value (KV) cache. Existing approaches, such as quantization, have demonstrated promising results in reducing memory usage. However, current quantization methods cannot take both effectiveness and efficiency into account. In this paper, we propose MoQAE, a novel mixed-precision quantization method via mixture of quantization-aware experts. First, we view different quantization bit-width configurations as experts and use the traditional mixture of experts (MoE) method to select the optimal configuration. To avoid the inefficiency caused by inputting tokens one by one into the router in the traditional MoE method, we input the tokens into the router chunk by chunk. Second, we design a lightweight router-only fine-tuning process to train MoQAE with a comprehensive loss to learn the trade-off between model accuracy and memory usage. Finally, we introduce a routing freezing (RF) and a routing sharing (RS) mechanism to further reduce the inference overhead. Extensive experiments on multiple benchmark datasets demonstrate that our method outperforms state-of-the-art KV cache quantization approaches in both efficiency and effectiveness.
MADLLM: Multivariate Anomaly Detection via Pre-trained LLMs
Apr 13, 2025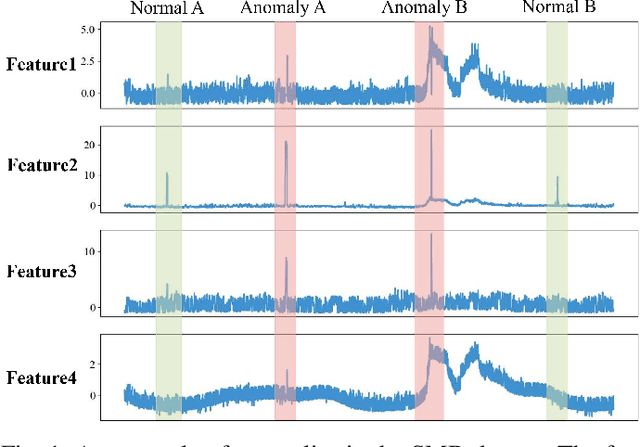
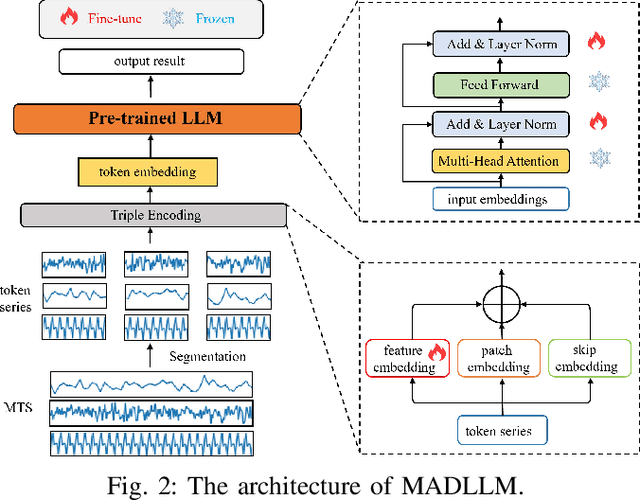
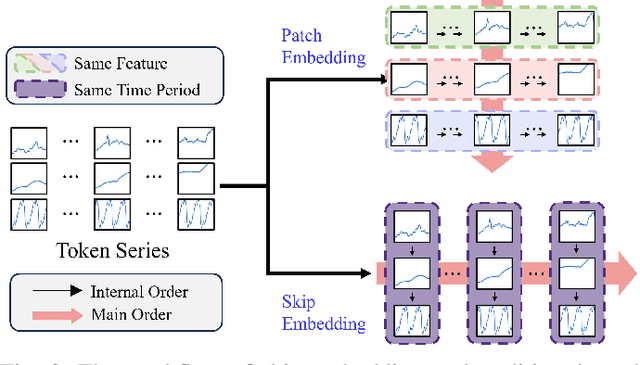
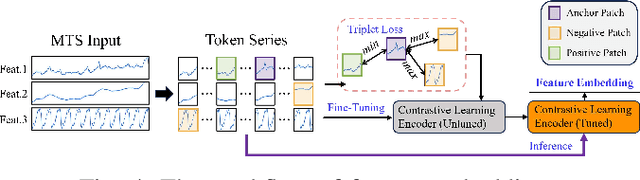
When applying pre-trained large language models (LLMs) to address anomaly detection tasks, the multivariate time series (MTS) modality of anomaly detection does not align with the text modality of LLMs. Existing methods simply transform the MTS data into multiple univariate time series sequences, which can cause many problems. This paper introduces MADLLM, a novel multivariate anomaly detection method via pre-trained LLMs. We design a new triple encoding technique to align the MTS modality with the text modality of LLMs. Specifically, this technique integrates the traditional patch embedding method with two novel embedding approaches: Skip Embedding, which alters the order of patch processing in traditional methods to help LLMs retain knowledge of previous features, and Feature Embedding, which leverages contrastive learning to allow the model to better understand the correlations between different features. Experimental results demonstrate that our method outperforms state-of-the-art methods in various public anomaly detection datasets.
Cocktail: Chunk-Adaptive Mixed-Precision Quantization for Long-Context LLM Inference
Mar 30, 2025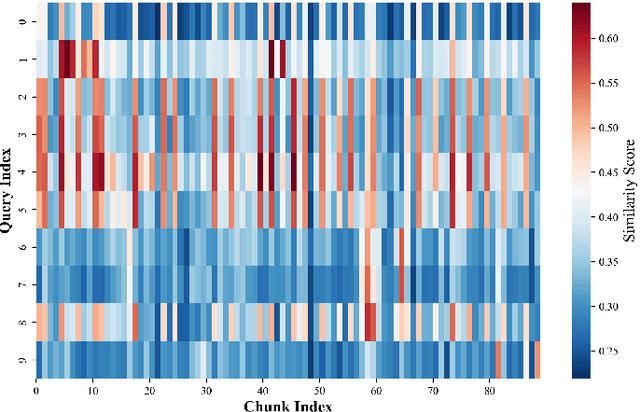
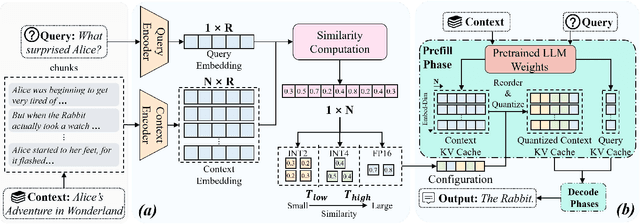
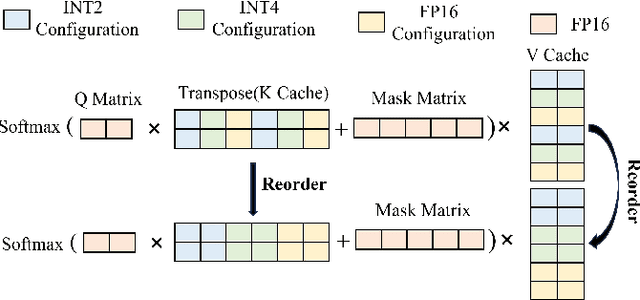
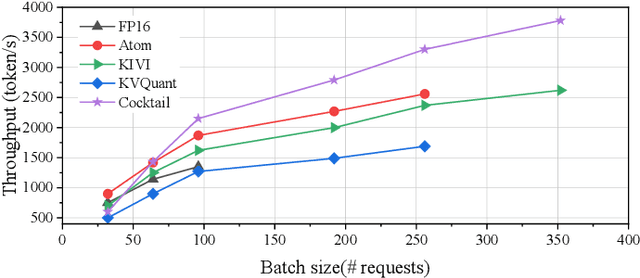
Recently, large language models (LLMs) have been able to handle longer and longer contexts. However, a context that is too long may cause intolerant inference latency and GPU memory usage. Existing methods propose mixed-precision quantization to the key-value (KV) cache in LLMs based on token granularity, which is time-consuming in the search process and hardware inefficient during computation. This paper introduces a novel approach called Cocktail, which employs chunk-adaptive mixed-precision quantization to optimize the KV cache. Cocktail consists of two modules: chunk-level quantization search and chunk-level KV cache computation. Chunk-level quantization search determines the optimal bitwidth configuration of the KV cache chunks quickly based on the similarity scores between the corresponding context chunks and the query, maintaining the model accuracy. Furthermore, chunk-level KV cache computation reorders the KV cache chunks before quantization, avoiding the hardware inefficiency caused by mixed-precision quantization in inference computation. Extensive experiments demonstrate that Cocktail outperforms state-of-the-art KV cache quantization methods on various models and datasets.
VisTa: Visual-contextual and Text-augmented Zero-shot Object-level OOD Detection
Mar 28, 2025As object detectors are increasingly deployed as black-box cloud services or pre-trained models with restricted access to the original training data, the challenge of zero-shot object-level out-of-distribution (OOD) detection arises. This task becomes crucial in ensuring the reliability of detectors in open-world settings. While existing methods have demonstrated success in image-level OOD detection using pre-trained vision-language models like CLIP, directly applying such models to object-level OOD detection presents challenges due to the loss of contextual information and reliance on image-level alignment. To tackle these challenges, we introduce a new method that leverages visual prompts and text-augmented in-distribution (ID) space construction to adapt CLIP for zero-shot object-level OOD detection. Our method preserves critical contextual information and improves the ability to differentiate between ID and OOD objects, achieving competitive performance across different benchmarks.
RUNA: Object-level Out-of-Distribution Detection via Regional Uncertainty Alignment of Multimodal Representations
Mar 28, 2025Enabling object detectors to recognize out-of-distribution (OOD) objects is vital for building reliable systems. A primary obstacle stems from the fact that models frequently do not receive supervisory signals from unfamiliar data, leading to overly confident predictions regarding OOD objects. Despite previous progress that estimates OOD uncertainty based on the detection model and in-distribution (ID) samples, we explore using pre-trained vision-language representations for object-level OOD detection. We first discuss the limitations of applying image-level CLIP-based OOD detection methods to object-level scenarios. Building upon these insights, we propose RUNA, a novel framework that leverages a dual encoder architecture to capture rich contextual information and employs a regional uncertainty alignment mechanism to distinguish ID from OOD objects effectively. We introduce a few-shot fine-tuning approach that aligns region-level semantic representations to further improve the model's capability to discriminate between similar objects. Our experiments show that RUNA substantially surpasses state-of-the-art methods in object-level OOD detection, particularly in challenging scenarios with diverse and complex object instances.
Hammer: Towards Efficient Hot-Cold Data Identification via Online Learning
Nov 22, 2024Efficient management of storage resources in big data and cloud computing environments requires accurate identification of data's "cold" and "hot" states. Traditional methods, such as rule-based algorithms and early AI techniques, often struggle with dynamic workloads, leading to low accuracy, poor adaptability, and high operational overhead. To address these issues, we propose a novel solution based on online learning strategies. Our approach dynamically adapts to changing data access patterns, achieving higher accuracy and lower operational costs. Rigorous testing with both synthetic and real-world datasets demonstrates a significant improvement, achieving a 90% accuracy rate in hot-cold classification. Additionally, the computational and storage overheads are considerably reduced.
PRENet: A Plane-Fit Redundancy Encoding Point Cloud Sequence Network for Real-Time 3D Action Recognition
May 11, 2024Recognizing human actions from point cloud sequence has attracted tremendous attention from both academia and industry due to its wide applications. However, most previous studies on point cloud action recognition typically require complex networks to extract intra-frame spatial features and inter-frame temporal features, resulting in an excessive number of redundant computations. This leads to high latency, rendering them impractical for real-world applications. To address this problem, we propose a Plane-Fit Redundancy Encoding point cloud sequence network named PRENet. The primary concept of our approach involves the utilization of plane fitting to mitigate spatial redundancy within the sequence, concurrently encoding the temporal redundancy of the entire sequence to minimize redundant computations. Specifically, our network comprises two principal modules: a Plane-Fit Embedding module and a Spatio-Temporal Consistency Encoding module. The Plane-Fit Embedding module capitalizes on the observation that successive point cloud frames exhibit unique geometric features in physical space, allowing for the reuse of spatially encoded data for temporal stream encoding. The Spatio-Temporal Consistency Encoding module amalgamates the temporal structure of the temporally redundant part with its corresponding spatial arrangement, thereby enhancing recognition accuracy. We have done numerous experiments to verify the effectiveness of our network. The experimental results demonstrate that our method achieves almost identical recognition accuracy while being nearly four times faster than other state-of-the-art methods.