 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMADLLM: Multivariate Anomaly Detection via Pre-trained LLMs
Paper and Code
Apr 13, 2025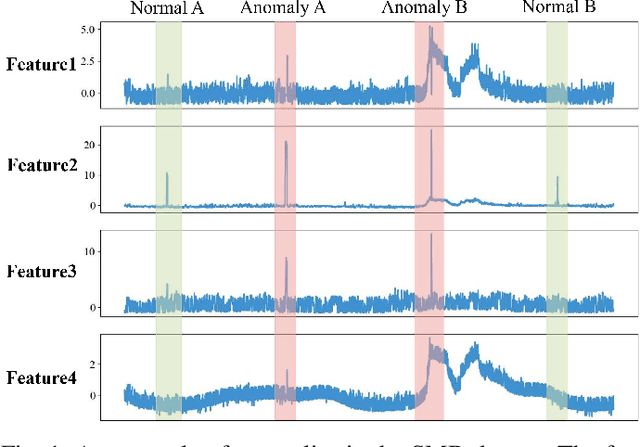
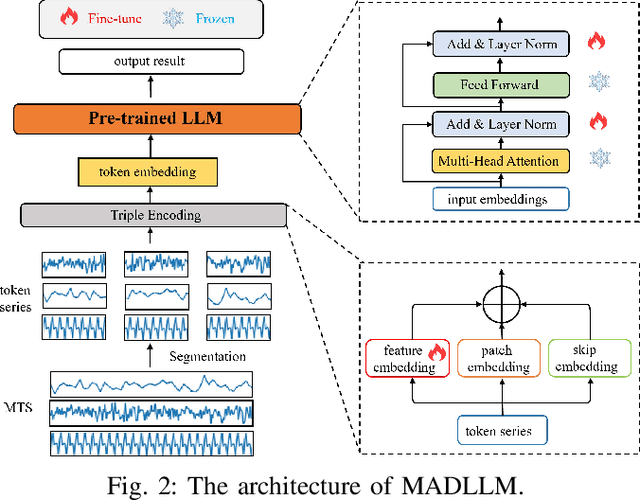
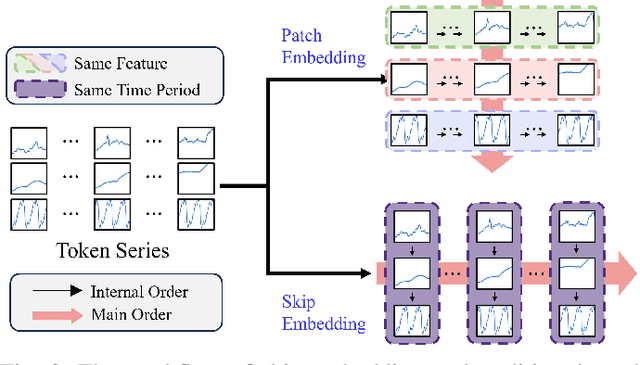
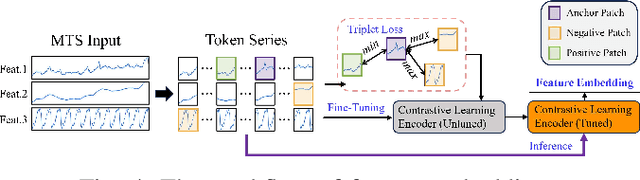
When applying pre-trained large language models (LLMs) to address anomaly detection tasks, the multivariate time series (MTS) modality of anomaly detection does not align with the text modality of LLMs. Existing methods simply transform the MTS data into multiple univariate time series sequences, which can cause many problems. This paper introduces MADLLM, a novel multivariate anomaly detection method via pre-trained LLMs. We design a new triple encoding technique to align the MTS modality with the text modality of LLMs. Specifically, this technique integrates the traditional patch embedding method with two novel embedding approaches: Skip Embedding, which alters the order of patch processing in traditional methods to help LLMs retain knowledge of previous features, and Feature Embedding, which leverages contrastive learning to allow the model to better understand the correlations between different features. Experimental results demonstrate that our method outperforms state-of-the-art methods in various public anomaly detection datasets.