 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCocktail: Chunk-Adaptive Mixed-Precision Quantization for Long-Context LLM Inference
Paper and Code
Mar 30, 2025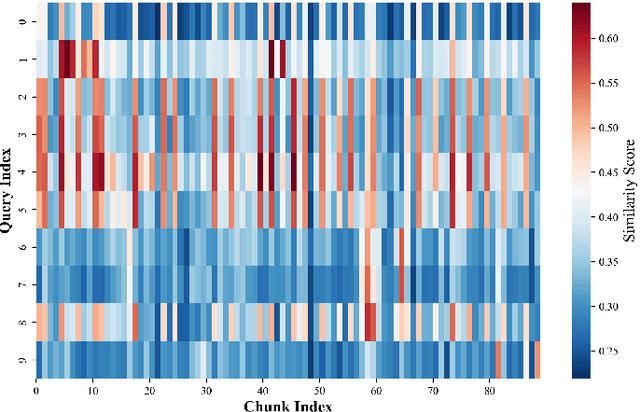
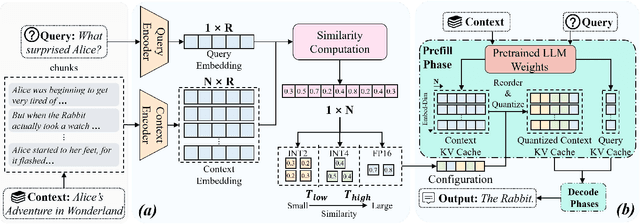
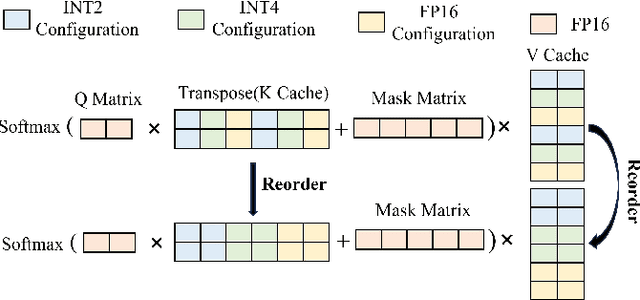
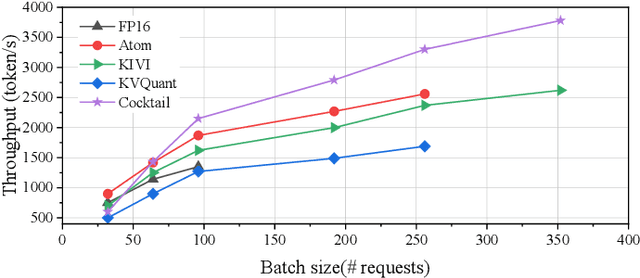
Recently, large language models (LLMs) have been able to handle longer and longer contexts. However, a context that is too long may cause intolerant inference latency and GPU memory usage. Existing methods propose mixed-precision quantization to the key-value (KV) cache in LLMs based on token granularity, which is time-consuming in the search process and hardware inefficient during computation. This paper introduces a novel approach called Cocktail, which employs chunk-adaptive mixed-precision quantization to optimize the KV cache. Cocktail consists of two modules: chunk-level quantization search and chunk-level KV cache computation. Chunk-level quantization search determines the optimal bitwidth configuration of the KV cache chunks quickly based on the similarity scores between the corresponding context chunks and the query, maintaining the model accuracy. Furthermore, chunk-level KV cache computation reorders the KV cache chunks before quantization, avoiding the hardware inefficiency caused by mixed-precision quantization in inference computation. Extensive experiments demonstrate that Cocktail outperforms state-of-the-art KV cache quantization methods on various models and datasets.