 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Video Contextual Knowledge Exploration and Exploitation for Ambiguity Reduction in Weakly Supervised Temporal Action Localization
Paper and Code
Aug 24, 2023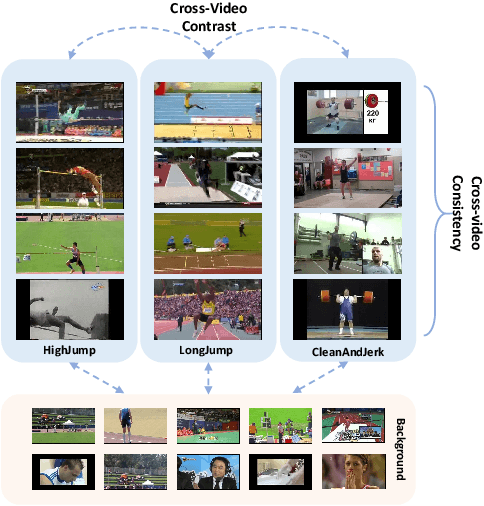
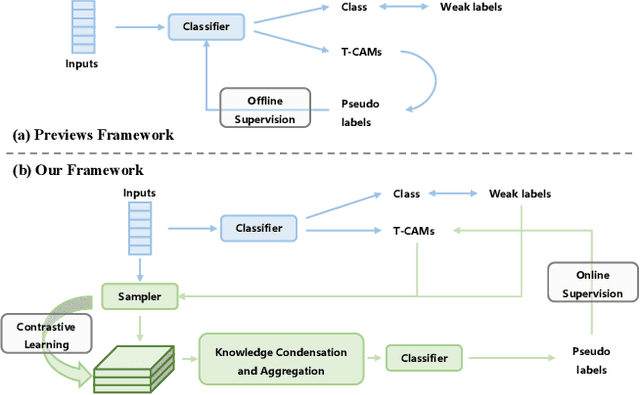
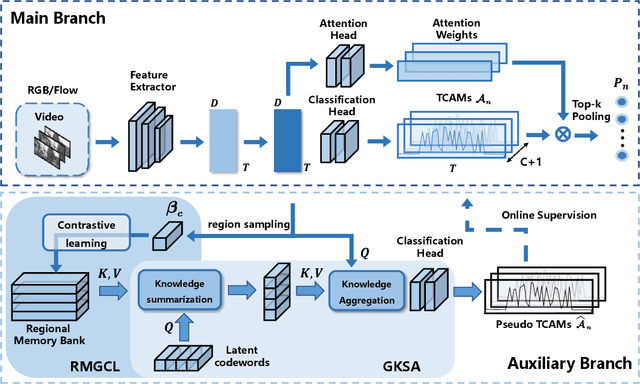
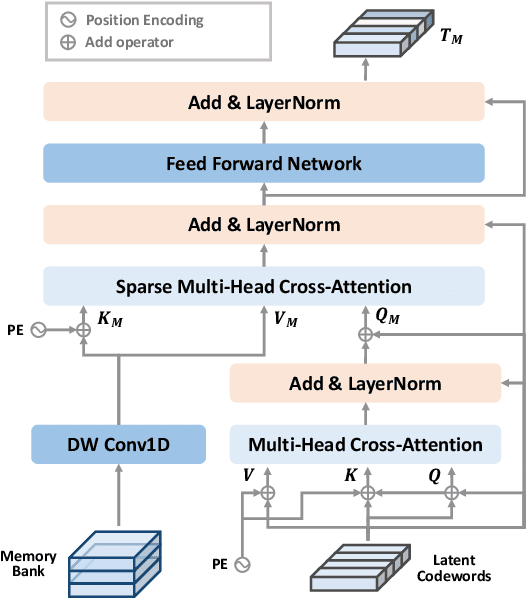
Weakly supervised temporal action localization (WSTAL) aims to localize actions in untrimmed videos using video-level labels. Despite recent advances, existing approaches mainly follow a localization-by-classification pipeline, generally processing each segment individually, thereby exploiting only limited contextual information. As a result, the model will lack a comprehensive understanding (e.g. appearance and temporal structure) of various action patterns, leading to ambiguity in classification learning and temporal localization. Our work addresses this from a novel perspective, by exploring and exploiting the cross-video contextual knowledge within the dataset to recover the dataset-level semantic structure of action instances via weak labels only, thereby indirectly improving the holistic understanding of fine-grained action patterns and alleviating the aforementioned ambiguities. Specifically, an end-to-end framework is proposed, including a Robust Memory-Guided Contrastive Learning (RMGCL) module and a Global Knowledge Summarization and Aggregation (GKSA) module. First, the RMGCL module explores the contrast and consistency of cross-video action features, assisting in learning more structured and compact embedding space, thus reducing ambiguity in classification learning. Further, the GKSA module is used to efficiently summarize and propagate the cross-video representative action knowledge in a learnable manner to promote holistic action patterns understanding, which in turn allows the generation of high-confidence pseudo-labels for self-learning, thus alleviating ambiguity in temporal localization. Extensive experiments on THUMOS14, ActivityNet1.3, and FineAction demonstrate that our method outperforms the state-of-the-art methods, and can be easily plugged into other WSTAL methods.