 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Test Problem Generator for Sequential Transfer Optimization
Apr 17, 2023Sequential transfer optimization (STO), which aims to improve optimization performance by exploiting knowledge captured from previously-solved optimization tasks stored in a database, has been gaining increasing research attention in recent years. However, despite significant advancements in algorithm design, the test problems in STO are not well designed. Oftentimes, they are either randomly assembled by other benchmark functions that have identical optima or are generated from practical problems that exhibit limited variations. The relationships between the optimal solutions of source and target tasks in these problems are manually configured and thus monotonous, limiting their ability to represent the diverse relationships of real-world problems. Consequently, the promising results achieved by many algorithms on these problems are highly biased and difficult to be generalized to other problems. In light of this, we first introduce a few rudimentary concepts for characterizing STO problems (STOPs) and present an important problem feature overlooked in previous studies, namely similarity distribution, which quantitatively delineates the relationship between the optima of source and target tasks. Then, we propose general design guidelines and a problem generator with superior extendibility. Specifically, the similarity distribution of a problem can be systematically customized by modifying a parameterized density function, enabling a broad spectrum of representation for the diverse similarity relationships of real-world problems. Lastly, a benchmark suite with 12 individual STOPs is developed using the proposed generator, which can serve as an arena for comparing different STO algorithms. The source code of the benchmark suite is available at https://github.com/XmingHsueh/STOP.
Incremental Data-driven Optimization of Complex Systems in Nonstationary Environments
Dec 25, 2020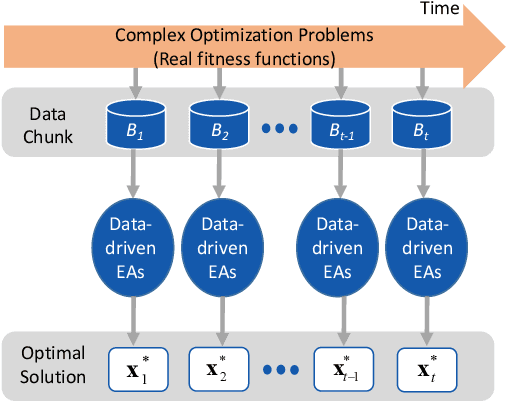
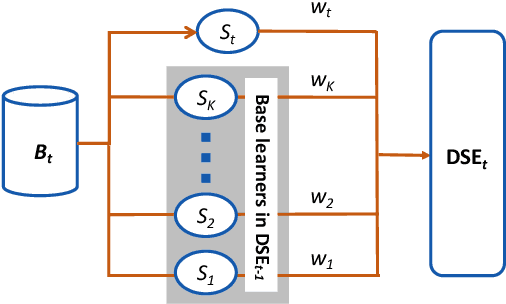
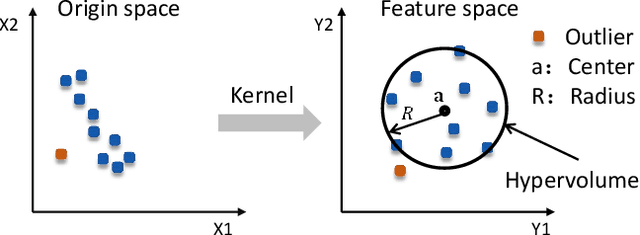
Existing work on data-driven optimization focuses on problems in static environments, but little attention has been paid to problems in dynamic environments. This paper proposes a data-driven optimization algorithm to deal with the challenges presented by the dynamic environments. First, a data stream ensemble learning method is adopted to train the surrogates so that each base learner of the ensemble learns the time-varying objective function in the previous environments. After that, a multi-task evolutionary algorithm is employed to simultaneously optimize the problems in the past environments assisted by the ensemble surrogate. This way, the optimization tasks in the previous environments can be used to accelerate the tracking of the optimum in the current environment. Since the real fitness function is not available for verifying the surrogates in offline data-driven optimization, a support vector domain description that was designed for outlier detection is introduced to select a reliable solution. Empirical results on six dynamic optimization benchmark problems demonstrate the effectiveness of the proposed algorithm compared with four state-of-the-art data-driven optimization algorithms.