 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theoretical Analysis of Analogy-Based Evolutionary Transfer Optimization
Mar 27, 2025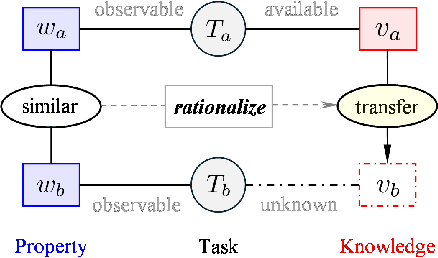

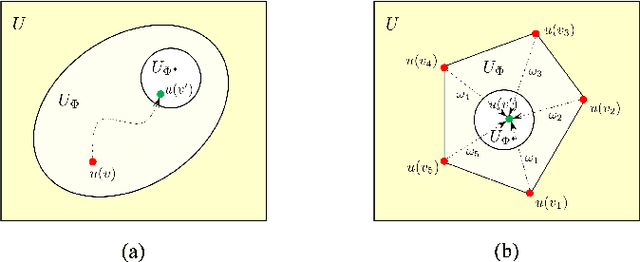
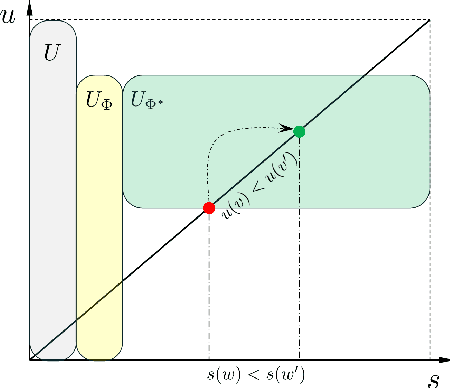
Evolutionary transfer optimization (ETO) has been gaining popularity in research over the years due to its outstanding knowledge transfer ability to address various challenges in optimization. However, a pressing issue in this field is that the invention of new ETO algorithms has far outpaced the development of fundamental theories needed to clearly understand the key factors contributing to the success of these algorithms for effective generalization. In response to this challenge, this study aims to establish theoretical foundations for analogy-based ETO, specifically to support various algorithms that frequently reference a key concept known as similarity. First, we introduce analogical reasoning and link its subprocesses to three key issues in ETO. Then, we develop theories for analogy-based knowledge transfer, rooted in the principles that underlie the subprocesses. Afterwards, we present two theorems related to the performance gain of analogy-based knowledge transfer, namely unconditionally nonnegative performance gain and conditionally positive performance gain, to theoretically demonstrate the effectiveness of various analogy-based ETO methods. Last but not least, we offer a novel insight into analogy-based ETO that interprets its conditional superiority over traditional evolutionary optimization through the lens of the no free lunch theorem for optimization.
Surrogate-Assisted Search with Competitive Knowledge Transfer for Expensive Optimization
Aug 13, 2024
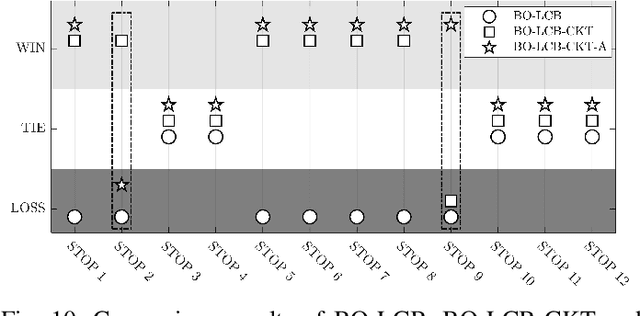

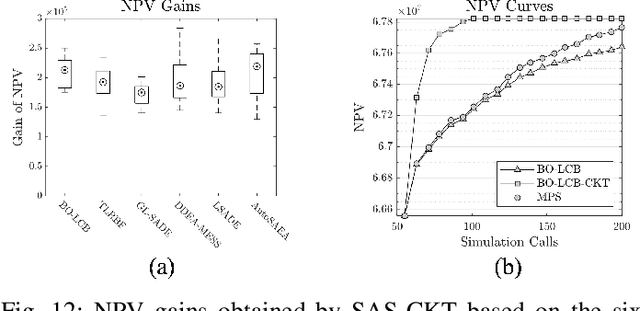
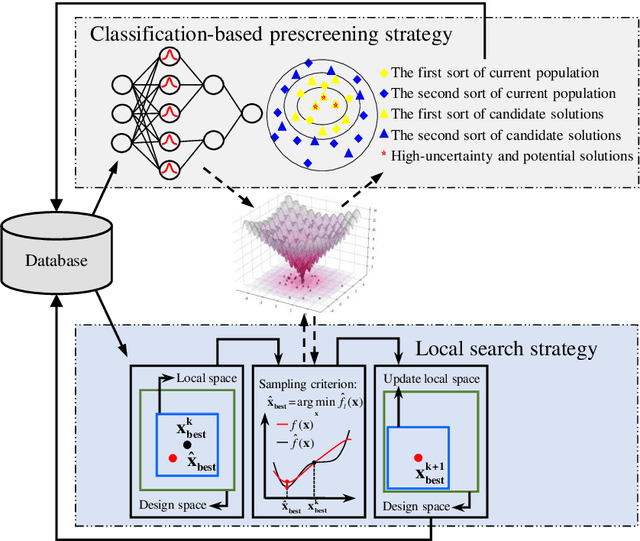
Expensive optimization problems (EOPs) have attracted increasing research attention over the decades due to their ubiquity in a variety of practical applications. Despite many sophisticated surrogate-assisted evolutionary algorithms (SAEAs) that have been developed for solving such problems, most of them lack the ability to transfer knowledge from previously-solved tasks and always start their search from scratch, making them troubled by the notorious cold-start issue. A few preliminary studies that integrate transfer learning into SAEAs still face some issues, such as defective similarity quantification that is prone to underestimate promising knowledge, surrogate-dependency that makes the transfer methods not coherent with the state-of-the-art in SAEAs, etc. In light of the above, a plug and play competitive knowledge transfer method is proposed to boost various SAEAs in this paper. Specifically, both the optimized solutions from the source tasks and the promising solutions acquired by the target surrogate are treated as task-solving knowledge, enabling them to compete with each other to elect the winner for expensive evaluation, thus boosting the search speed on the target task. Moreover, the lower bound of the convergence gain brought by the knowledge competition is mathematically analyzed, which is expected to strengthen the theoretical foundation of sequential transfer optimization. Experimental studies conducted on a series of benchmark problems and a practical application from the petroleum industry verify the efficacy of the proposed method. The source code of the competitive knowledge transfer is available at https://github.com/XmingHsueh/SAS-CKT.
Rank-Based Learning and Local Model Based Evolutionary Algorithm for High-Dimensional Expensive Multi-Objective Problems
Apr 19, 2023



Surrogate-assisted evolutionary algorithms have been widely developed to solve complex and computationally expensive multi-objective optimization problems in recent years. However, when dealing with high-dimensional optimization problems, the performance of these surrogate-assisted multi-objective evolutionary algorithms deteriorate drastically. In this work, a novel Classifier-assisted rank-based learning and Local Model based multi-objective Evolutionary Algorithm (CLMEA) is proposed for high-dimensional expensive multi-objective optimization problems. The proposed algorithm consists of three parts: classifier-assisted rank-based learning, hypervolume-based non-dominated search, and local search in the relatively sparse objective space. Specifically, a probabilistic neural network is built as classifier to divide the offspring into a number of ranks. The offspring in different ranks uses rank-based learning strategy to generate more promising and informative candidates for real function evaluations. Then, radial basis function networks are built as surrogates to approximate the objective functions. After searching non-dominated solutions assisted by the surrogate model, the candidates with higher hypervolume improvement are selected for real evaluations. Subsequently, in order to maintain the diversity of solutions, the most uncertain sample point from the non-dominated solutions measured by the crowding distance is selected as the guided parent to further infill in the uncertain region of the front. The experimental results of benchmark problems and a real-world application on geothermal reservoir heat extraction optimization demonstrate that the proposed algorithm shows superior performance compared with the state-of-the-art surrogate-assisted multi-objective evolutionary algorithms. The source code for this work is available at https://github.com/JellyChen7/CLMEA.
A Scalable Test Problem Generator for Sequential Transfer Optimization
Apr 17, 2023Sequential transfer optimization (STO), which aims to improve optimization performance by exploiting knowledge captured from previously-solved optimization tasks stored in a database, has been gaining increasing research attention in recent years. However, despite significant advancements in algorithm design, the test problems in STO are not well designed. Oftentimes, they are either randomly assembled by other benchmark functions that have identical optima or are generated from practical problems that exhibit limited variations. The relationships between the optimal solutions of source and target tasks in these problems are manually configured and thus monotonous, limiting their ability to represent the diverse relationships of real-world problems. Consequently, the promising results achieved by many algorithms on these problems are highly biased and difficult to be generalized to other problems. In light of this, we first introduce a few rudimentary concepts for characterizing STO problems (STOPs) and present an important problem feature overlooked in previous studies, namely similarity distribution, which quantitatively delineates the relationship between the optima of source and target tasks. Then, we propose general design guidelines and a problem generator with superior extendibility. Specifically, the similarity distribution of a problem can be systematically customized by modifying a parameterized density function, enabling a broad spectrum of representation for the diverse similarity relationships of real-world problems. Lastly, a benchmark suite with 12 individual STOPs is developed using the proposed generator, which can serve as an arena for comparing different STO algorithms. The source code of the benchmark suite is available at https://github.com/XmingHsueh/STOP.
Data-driven evolutionary algorithm for oil reservoir well-placement and control optimization
Jun 07, 2022

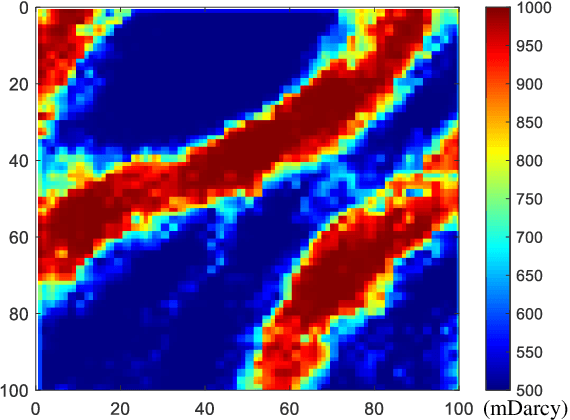
Optimal well placement and well injection-production are crucial for the reservoir development to maximize the financial profits during the project lifetime. Meta-heuristic algorithms have showed good performance in solving complex, nonlinear and non-continuous optimization problems. However, a large number of numerical simulation runs are involved during the optimization process. In this work, a novel and efficient data-driven evolutionary algorithm, called generalized data-driven differential evolutionary algorithm (GDDE), is proposed to reduce the number of simulation runs on well-placement and control optimization problems. Probabilistic neural network (PNN) is adopted as the classifier to select informative and promising candidates, and the most uncertain candidate based on Euclidean distance is prescreened and evaluated with a numerical simulator. Subsequently, local surrogate model is built by radial basis function (RBF) and the optimum of the surrogate, found by optimizer, is evaluated by the numerical simulator to accelerate the convergence. It is worth noting that the shape factors of RBF model and PNN are optimized via solving hyper-parameter sub-expensive optimization problem. The results show the optimization algorithm proposed in this study is very promising for a well-placement optimization problem of two-dimensional reservoir and joint optimization of Egg model.
Deep interval prediction model with gradient descend optimization method for short-term wind power prediction
Nov 19, 2019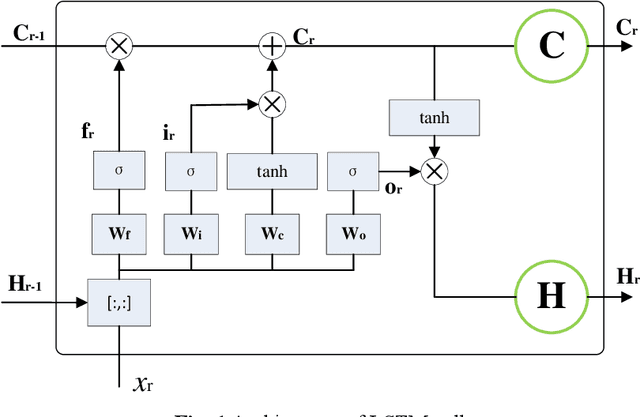
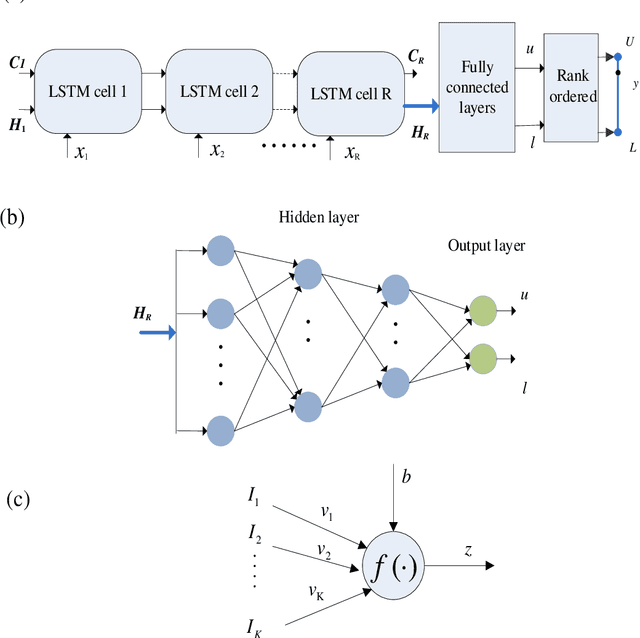
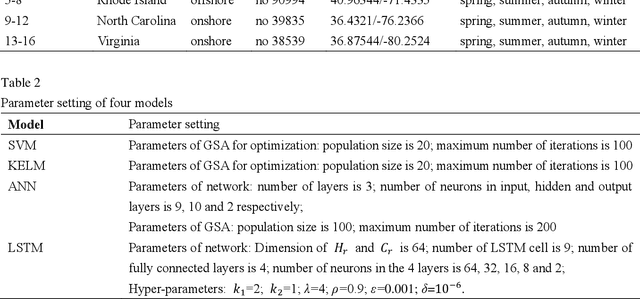
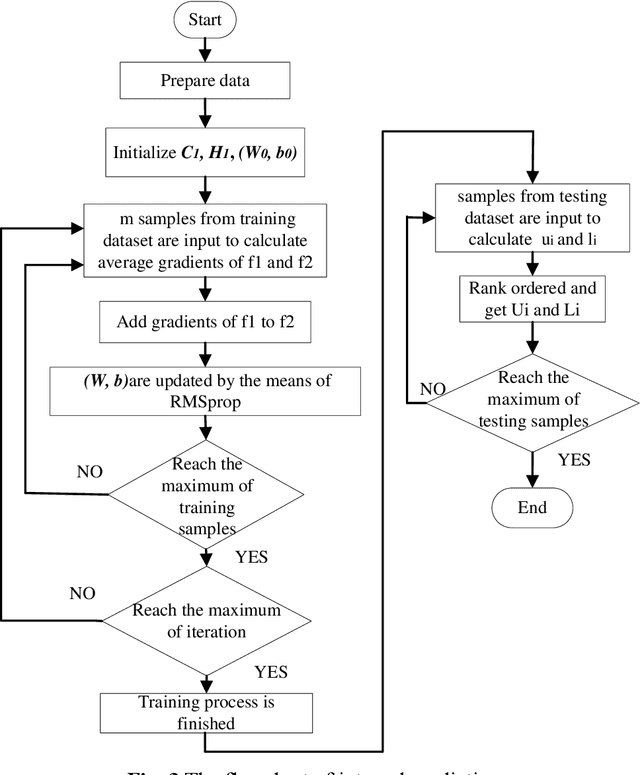
The application of wind power interval prediction for power systems attempts to give more comprehensive support to dispatchers and operators of the grid. Lower upper bound estimation (LUBE) method is widely applied in interval prediction. However, the existing LUBE approaches are trained by meta-heuristic optimization, which is either time-consuming or show poor effect when the LUBE model is complex. In this paper, a deep interval prediction method is designed in the framework of LUBE and an efficient gradient descend (GD) training approach is proposed to train the LUBE model. In this method, the long short-term memory is selected as a representative to show the modelling approach. The architecture of the proposed model consists of three parts, namely the long short-term memory module, the fully connected layers and the rank ordered module. Two loss functions are specially designed for implementing the GD training method based on the root mean square back propagation algorithm. To verify the performance of the proposed model, conventional LUBE models, as well as popular statistic interval prediction models are compared in numerical experiments. The results show that the proposed approach performs best in terms of effectiveness and efficiency with average 45% promotion in quality of prediction interval and 66% reduction of time consumptions compared to traditional LUBE models.