 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOLAR: SVD-Optimized Lifelong Attention for Recommendation
Mar 03, 2026Attention mechanism remains the defining operator in Transformers since it provides expressive global credit assignment, yet its $O(N^2 d)$ time and memory cost in sequence length $N$ makes long-context modeling expensive and often forces truncation or other heuristics. Linear attention reduces complexity to $O(N d^2)$ by reordering computation through kernel feature maps, but this reformulation drops the softmax mechanism and shifts the attention score distribution. In recommender systems, low-rank structure in matrices is not a rare case, but rather the default inductive bias in its representation learning, particularly explicit in the user behavior sequence modeling. Leveraging this structure, we introduce SVD-Attention, which is theoretically lossless on low-rank matrices and preserves softmax while reducing attention complexity from $O(N^2 d)$ to $O(Ndr)$. With SVD-Attention, we propose SOLAR, SVD-Optimized Lifelong Attention for Recommendation, a sequence modeling framework that supports behavior sequences of ten-thousand scale and candidate sets of several thousand items in cascading process without any filtering. In Kuaishou's online recommendation scenario, SOLAR delivers a 0.68\% Video Views gain together with additional business metrics improvements.
Towards Robust Recommendation via Decision Boundary-aware Graph Contrastive Learning
Jul 14, 2024



In recent years, graph contrastive learning (GCL) has received increasing attention in recommender systems due to its effectiveness in reducing bias caused by data sparsity. However, most existing GCL models rely on heuristic approaches and usually assume entity independence when constructing contrastive views. We argue that these methods struggle to strike a balance between semantic invariance and view hardness across the dynamic training process, both of which are critical factors in graph contrastive learning. To address the above issues, we propose a novel GCL-based recommendation framework RGCL, which effectively maintains the semantic invariance of contrastive pairs and dynamically adapts as the model capability evolves through the training process. Specifically, RGCL first introduces decision boundary-aware adversarial perturbations to constrain the exploration space of contrastive augmented views, avoiding the decrease of task-specific information. Furthermore, to incorporate global user-user and item-item collaboration relationships for guiding on the generation of hard contrastive views, we propose an adversarial-contrastive learning objective to construct a relation-aware view-generator. Besides, considering that unsupervised GCL could potentially narrower margins between data points and the decision boundary, resulting in decreased model robustness, we introduce the adversarial examples based on maximum perturbations to achieve margin maximization. We also provide theoretical analyses on the effectiveness of our designs. Through extensive experiments on five public datasets, we demonstrate the superiority of RGCL compared against twelve baseline models.
IFA: Interaction Fidelity Attention for Entire Lifelong Behaviour Sequence Modeling
Jun 14, 2024The lifelong user behavior sequence provides abundant information of user preference and gains impressive improvement in the recommendation task, however increases computational consumption significantly. To meet the severe latency requirement in online service, a short sub-sequence is sampled based on similarity to the target item. Unfortunately, items not in the sub-sequence are abandoned, leading to serious information loss. In this paper, we propose a new efficient paradigm to model the full lifelong sequence, which is named as \textbf{I}nteraction \textbf{F}idelity \textbf{A}ttention (\textbf{IFA}). In IFA, we input all target items in the candidate set into the model at once, and leverage linear transformer to reduce the time complexity of the cross attention between the candidate set and the sequence without any interaction information loss. We also additionally model the relationship of all target items for optimal set generation, and design loss function for better consistency of training and inference. We demonstrate the effectiveness and efficiency of our model by off-line and online experiments in the recommender system of Kuaishou.
RecGPT: Generative Personalized Prompts for Sequential Recommendation via ChatGPT Training Paradigm
Apr 06, 2024ChatGPT has achieved remarkable success in natural language understanding. Considering that recommendation is indeed a conversation between users and the system with items as words, which has similar underlying pattern with ChatGPT, we design a new chat framework in item index level for the recommendation task. Our novelty mainly contains three parts: model, training and inference. For the model part, we adopt Generative Pre-training Transformer (GPT) as the sequential recommendation model and design a user modular to capture personalized information. For the training part, we adopt the two-stage paradigm of ChatGPT, including pre-training and fine-tuning. In the pre-training stage, we train GPT model by auto-regression. In the fine-tuning stage, we train the model with prompts, which include both the newly-generated results from the model and the user's feedback. For the inference part, we predict several user interests as user representations in an autoregressive manner. For each interest vector, we recall several items with the highest similarity and merge the items recalled by all interest vectors into the final result. We conduct experiments with both offline public datasets and online A/B test to demonstrate the effectiveness of our proposed method.
Sampler Design for Implicit Feedback Data by Noisy-label Robust Learning
Jun 28, 2020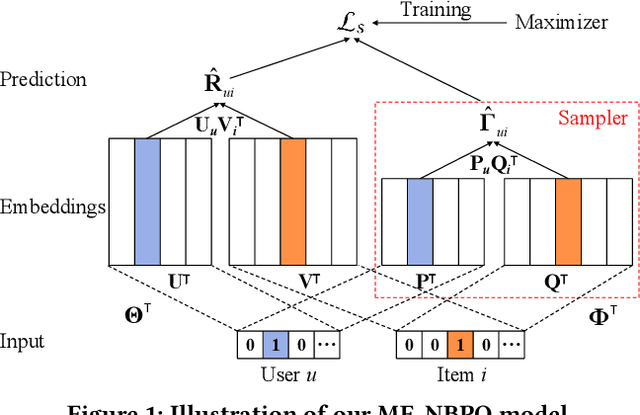
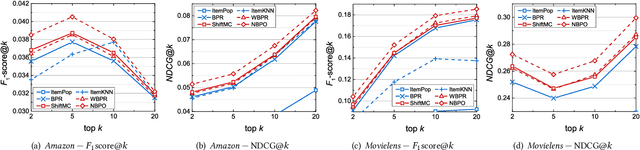
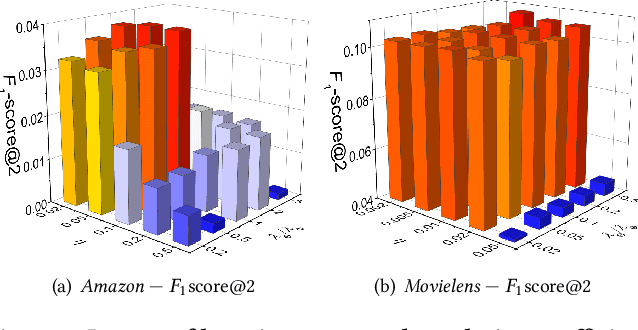
Implicit feedback data is extensively explored in recommendation as it is easy to collect and generally applicable. However, predicting users' preference on implicit feedback data is a challenging task since we can only observe positive (voted) samples and unvoted samples. It is difficult to distinguish between the negative samples and unlabeled positive samples from the unvoted ones. Existing works, such as Bayesian Personalized Ranking (BPR), sample unvoted items as negative samples uniformly, therefore suffer from a critical noisy-label issue. To address this gap, we design an adaptive sampler based on noisy-label robust learning for implicit feedback data. To formulate the issue, we first introduce Bayesian Point-wise Optimization (BPO) to learn a model, e.g., Matrix Factorization (MF), by maximum likelihood estimation. We predict users' preferences with the model and learn it by maximizing likelihood of observed data labels, i.e., a user prefers her positive samples and has no interests in her unvoted samples. However, in reality, a user may have interests in some of her unvoted samples, which are indeed positive samples mislabeled as negative ones. We then consider the risk of these noisy labels, and propose a Noisy-label Robust BPO (NBPO). NBPO also maximizes the observation likelihood while connects users' preference and observed labels by the likelihood of label flipping based on the Bayes' theorem. In NBPO, a user prefers her true positive samples and shows no interests in her true negative samples, hence the optimization quality is dramatically improved. Extensive experiments on two public real-world datasets show the significant improvement of our proposed optimization methods.
Semi-supervised Collaborative Filtering by Text-enhanced Domain Adaptation
Jun 28, 2020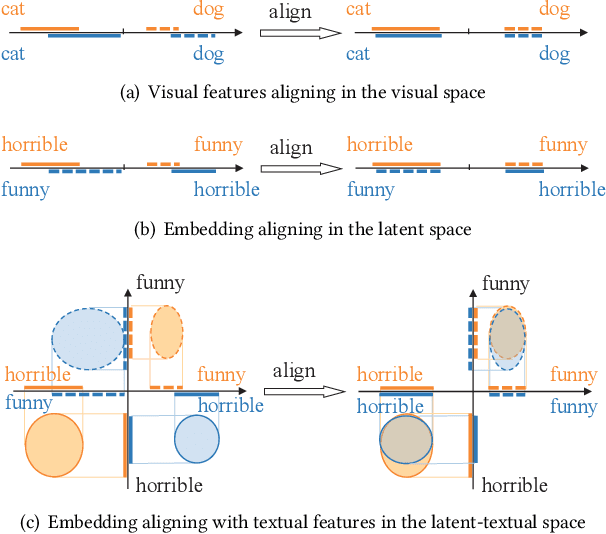
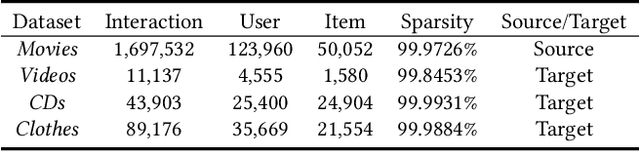
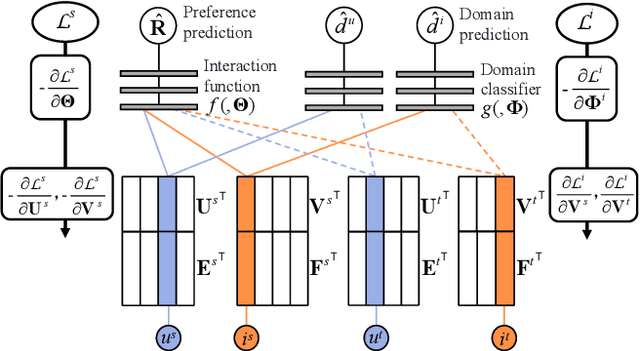
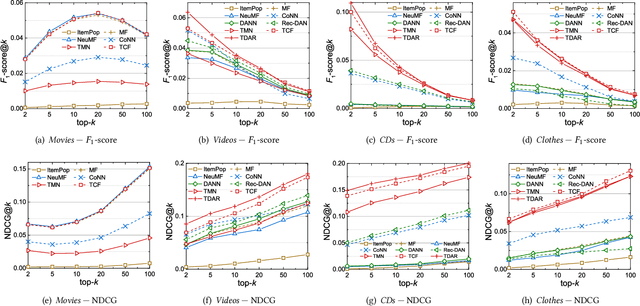
Data sparsity is an inherent challenge in the recommender systems, where most of the data is collected from the implicit feedbacks of users. This causes two difficulties in designing effective algorithms: first, the majority of users only have a few interactions with the system and there is no enough data for learning; second, there are no negative samples in the implicit feedbacks and it is a common practice to perform negative sampling to generate negative samples. However, this leads to a consequence that many potential positive samples are mislabeled as negative ones and data sparsity would exacerbate the mislabeling problem. To solve these difficulties, we regard the problem of recommendation on sparse implicit feedbacks as a semi-supervised learning task, and explore domain adaption to solve it. We transfer the knowledge learned from dense data to sparse data and we focus on the most challenging case -- there is no user or item overlap. In this extreme case, aligning embeddings of two datasets directly is rather sub-optimal since the two latent spaces encode very different information. As such, we adopt domain-invariant textual features as the anchor points to align the latent spaces. To align the embeddings, we extract the textual features for each user and item and feed them into a domain classifier with the embeddings of users and items. The embeddings are trained to puzzle the classifier and textual features are fixed as anchor points. By domain adaptation, the distribution pattern in the source domain is transferred to the target domain. As the target part can be supervised by domain adaptation, we abandon negative sampling in target dataset to avoid label noise. We adopt three pairs of real-world datasets to validate the effectiveness of our transfer strategy. Results show that our models outperform existing models significantly.
Graph Convolutional Network for Recommendation with Low-pass Collaborative Filters
Jun 28, 2020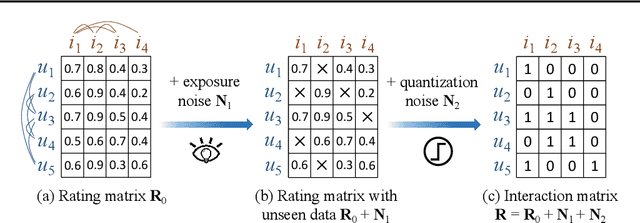
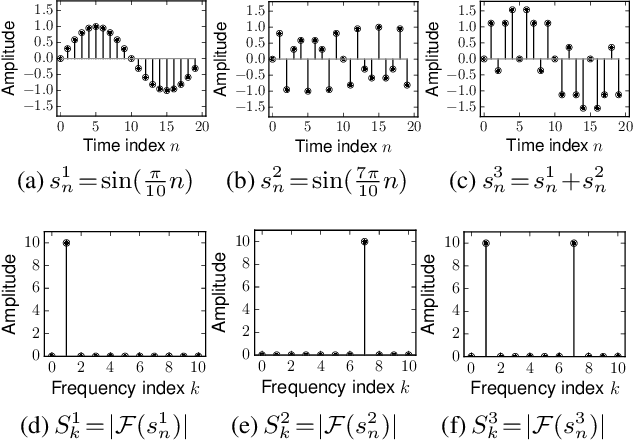
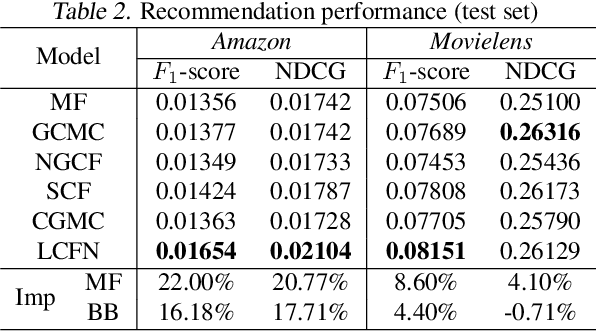
\textbf{G}raph \textbf{C}onvolutional \textbf{N}etwork (\textbf{GCN}) is widely used in graph data learning tasks such as recommendation. However, when facing a large graph, the graph convolution is very computationally expensive thus is simplified in all existing GCNs, yet is seriously impaired due to the oversimplification. To address this gap, we leverage the \textit{original graph convolution} in GCN and propose a \textbf{L}ow-pass \textbf{C}ollaborative \textbf{F}ilter (\textbf{LCF}) to make it applicable to the large graph. LCF is designed to remove the noise caused by exposure and quantization in the observed data, and it also reduces the complexity of graph convolution in an unscathed way. Experiments show that LCF improves the effectiveness and efficiency of graph convolution and our GCN outperforms existing GCNs significantly. Codes are available on \url{https://github.com/Wenhui-Yu/LCFN}.
Spectrum-enhanced Pairwise Learning to Rank
May 02, 2019
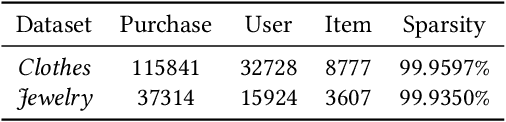
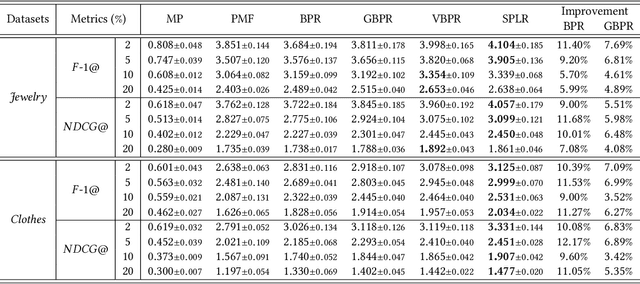
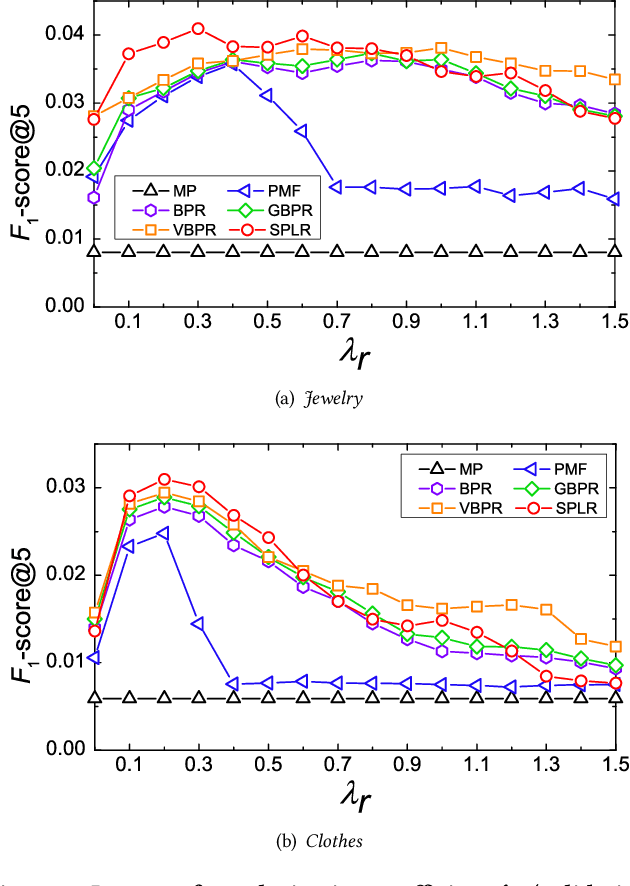
To enhance the performance of the recommender system, side information is extensively explored with various features (e.g., visual features and textual features). However, there are some demerits of side information: (1) the extra data is not always available in all recommendation tasks; (2) it is only for items, there is seldom high-level feature describing users. To address these gaps, we introduce the spectral features extracted from two hypergraph structures of the purchase records. Spectral features describe the \textit{similarity} of users/items in the graph space, which is critical for recommendation. We leverage spectral features to model the users' preference and items' properties by incorporating them into a Matrix Factorization (MF) model. In addition to modeling, we also use spectral features to optimize. Bayesian Personalized Ranking (BPR) is extensively leveraged to optimize models in implicit feedback data. However, in BPR, all missing values are regarded as negative samples equally while many of them are indeed unseen positive ones. We enrich the positive samples by calculating the similarity among users/items by the spectral features. The key ideas are: (1) similar users shall have similar preference on the same item; (2) a user shall have similar perception on similar items. Extensive experiments on two real-world datasets demonstrate the usefulness of the spectral features and the effectiveness of our spectrum-enhanced pairwise optimization. Our models outperform several state-of-the-art models significantly.
Aesthetic-based Clothing Recommendation
Sep 16, 2018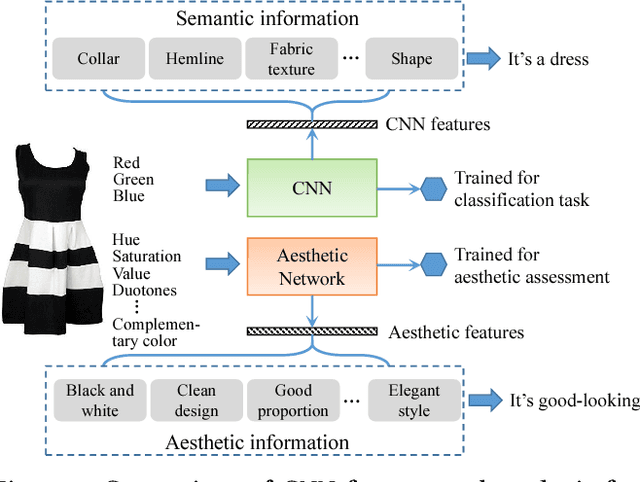
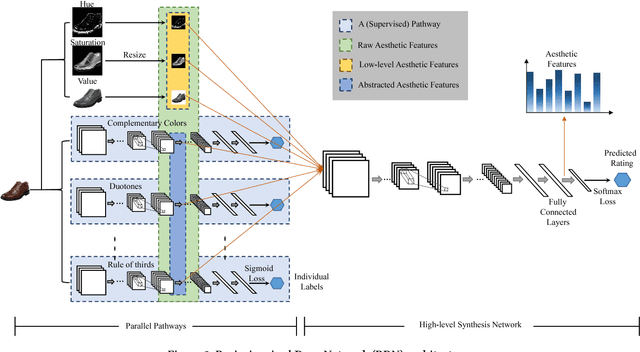
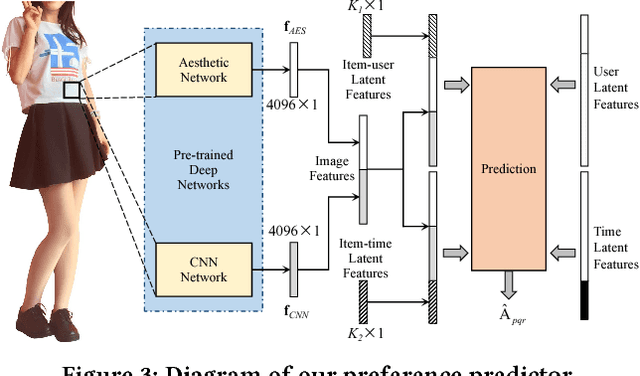
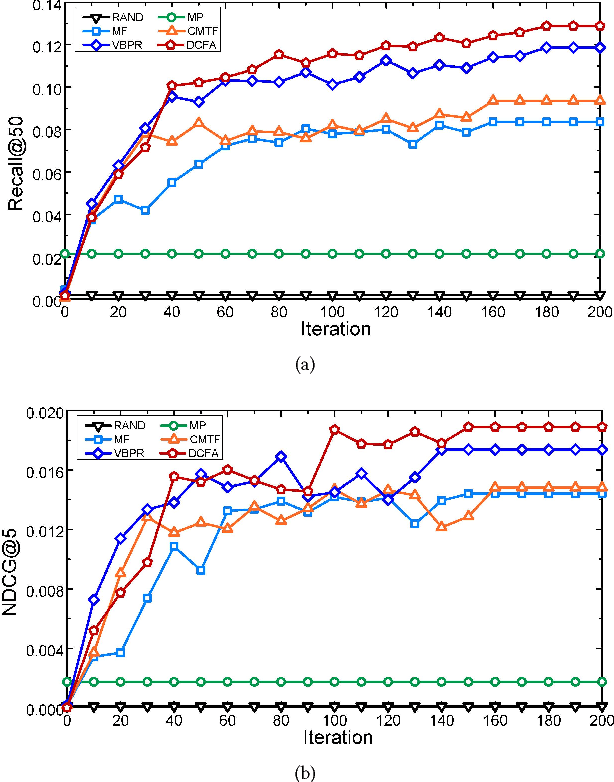
Recently, product images have gained increasing attention in clothing recommendation since the visual appearance of clothing products has a significant impact on consumers' decision. Most existing methods rely on conventional features to represent an image, such as the visual features extracted by convolutional neural networks (CNN features) and the scale-invariant feature transform algorithm (SIFT features), color histograms, and so on. Nevertheless, one important type of features, the \emph{aesthetic features}, is seldom considered. It plays a vital role in clothing recommendation since a users' decision depends largely on whether the clothing is in line with her aesthetics, however the conventional image features cannot portray this directly. To bridge this gap, we propose to introduce the aesthetic information, which is highly relevant with user preference, into clothing recommender systems. To achieve this, we first present the aesthetic features extracted by a pre-trained neural network, which is a brain-inspired deep structure trained for the aesthetic assessment task. Considering that the aesthetic preference varies significantly from user to user and by time, we then propose a new tensor factorization model to incorporate the aesthetic features in a personalized manner. We conduct extensive experiments on real-world datasets, which demonstrate that our approach can capture the aesthetic preference of users and significantly outperform several state-of-the-art recommendation methods.