 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStriking the Right Balance between Compute and Copy: Improving LLM Inferencing Under Speculative Decoding
Nov 15, 2025With the skyrocketing costs of GPUs and their virtual instances in the cloud, there is a significant desire to use CPUs for large language model (LLM) inference. KV cache update, often implemented as allocation, copying, and in-place strided update for each generated token, incurs significant overhead. As the sequence length increases, the allocation and copy overheads dominate the performance. Alternate approaches may allocate large KV tensors upfront to enable in-place updates, but these matrices (with zero-padded rows) cause redundant computations. In this work, we propose a new KV cache allocation mechanism called Balancing Memory and Compute (BMC). BMC allocates, once every r iterations, KV tensors with r redundant rows, allowing in-place update without copy overhead for those iterations, but at the expense of a small amount of redundant computation. Second, we make an interesting observation that the extra rows allocated in the KV tensors and the resulting redundant computation can be repurposed for Speculative Decoding (SD) that improves token generation efficiency. Last, BMC represents a spectrum of design points with different values of r. To identify the best-performing design point(s), we derive a simple analytical model for BMC. The proposed BMC method achieves an average throughput acceleration of up to 3.2x over baseline HuggingFace (without SD). Importantly when we apply BMC with SD, it results in an additional speedup of up to 1.39x, over and above the speedup offered by SD. Further, BMC achieves a throughput acceleration of up to 1.36x and 2.29x over state-of-the-art inference servers vLLM and DeepSpeed, respectively. Although the BMC technique is evaluated extensively across different classes of CPUs (desktop and server class), we also evaluate the scheme with GPUs and demonstrate that it works well for GPUs.
DuetServe: Harmonizing Prefill and Decode for LLM Serving via Adaptive GPU Multiplexing
Nov 06, 2025Modern LLM serving systems must sustain high throughput while meeting strict latency SLOs across two distinct inference phases: compute-intensive prefill and memory-bound decode phases. Existing approaches either (1) aggregate both phases on shared GPUs, leading to interference between prefill and decode phases, which degrades time-between-tokens (TBT); or (2) disaggregate the two phases across GPUs, improving latency but wasting resources through duplicated models and KV cache transfers. We present DuetServe, a unified LLM serving framework that achieves disaggregation-level isolation within a single GPU. DuetServe operates in aggregated mode by default and dynamically activates SM-level GPU spatial multiplexing when TBT degradation is predicted. Its key idea is to decouple prefill and decode execution only when needed through fine-grained, adaptive SM partitioning that provides phase isolation only when contention threatens latency service level objectives (SLOs). DuetServe integrates (1) an attention-aware roofline model to forecast iteration latency, (2) a partitioning optimizer that selects the optimal SM split to maximize throughput under TBT constraints, and (3) an interruption-free execution engine that eliminates CPU-GPU synchronization overhead. Evaluations show that DuetServe improves total throughput by up to 1.3x while maintaining low generation latency compared to state-of-the-art frameworks.
DEL: Context-Aware Dynamic Exit Layer for Efficient Self-Speculative Decoding
Apr 08, 2025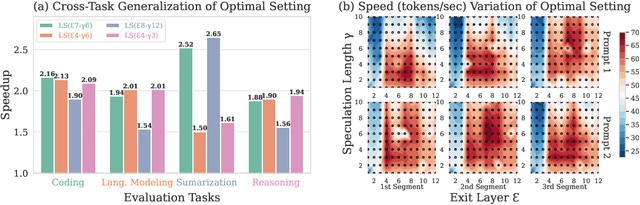
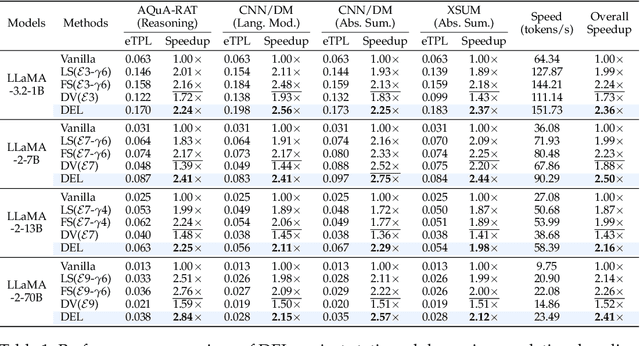
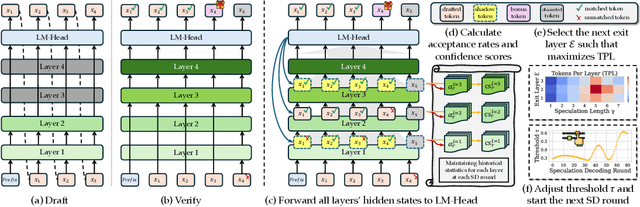

Speculative Decoding (SD) is a widely used approach to accelerate the inference of large language models (LLMs) without reducing generation quality. It operates by first using a compact model to draft multiple tokens efficiently, followed by parallel verification using the target LLM. This approach leads to faster inference compared to auto-regressive decoding. While there are multiple approaches to create a draft model, one promising approach is to use early-exit methods. These methods draft candidate tokens by using a subset of layers of the primary model and applying the remaining layers for verification, allowing a single model to handle both drafting and verification. While this technique reduces memory usage and computational cost, its performance relies on the choice of the exit layer for drafting and the number of tokens drafted (speculation length) in each SD round. Prior works use hyperparameter exploration to statically select these values. However, our evaluations show that these hyperparameter values are task-specific, and even within a task they are dependent on the current sequence context. We introduce DEL, a plug-and-play method that adaptively selects the exit layer and speculation length during inference. DEL dynamically tracks the token acceptance rate if the tokens are drafted at each layer of an LLM and uses that knowledge to heuristically select the optimal exit layer and speculation length. Our experiments across a broad range of models and downstream tasks show that DEL achieves overall speedups of $2.16\times$$\sim$$2.50\times$ over vanilla auto-regressive decoding and improves upon the state-of-the-art SD methods by up to $0.27\times$.
Efficient LLM Inference with I/O-Aware Partial KV Cache Recomputation
Nov 26, 2024Inference for Large Language Models (LLMs) is computationally demanding. To reduce the cost of auto-regressive decoding, Key-Value (KV) caching is used to store intermediate activations, enabling GPUs to perform only the incremental computation required for each new token. This approach significantly lowers the computational overhead for token generation. However, the memory required for KV caching grows rapidly, often exceeding the capacity of GPU memory. A cost-effective alternative is to offload KV cache to CPU memory, which alleviates GPU memory pressure but shifts the bottleneck to the limited bandwidth of the PCIe connection between the CPU and GPU. Existing methods attempt to address these issues by overlapping GPU computation with I/O or employing CPU-GPU heterogeneous execution, but they are hindered by excessive data movement and dependence on CPU capabilities. In this paper, we introduce an efficient CPU-GPU I/O-aware LLM inference method that avoids transferring the entire KV cache from CPU to GPU by recomputing partial KV cache from activations while concurrently transferring the remaining KV cache via PCIe bus. This approach overlaps GPU recomputation with data transfer to minimize idle GPU time and maximize inference performance. Our method is fully automated by integrating a profiler module that utilizes input characteristics and system hardware information, a scheduler module to optimize the distribution of computation and communication workloads, and a runtime module to efficiently execute the derived execution plan. Experimental results show that our method achieves up to 35.8% lower latency and 46.2% higher throughput during decoding compared to state-of-the-art approaches.
CADC: Encoding User-Item Interactions for Compressing Recommendation Model Training Data
Jul 11, 2024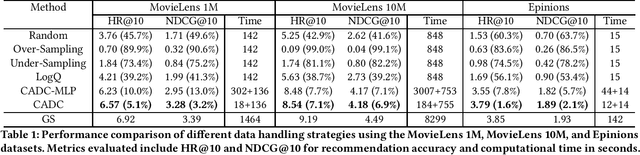
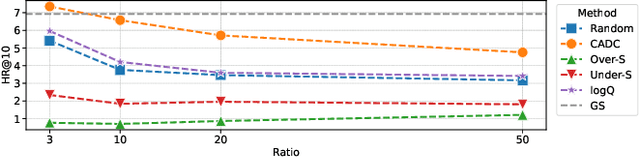
Deep learning recommendation models (DLRMs) are at the heart of the current e-commerce industry. However, the amount of training data used to train these large models is growing exponentially, leading to substantial training hurdles. The training dataset contains two primary types of information: content-based information (features of users and items) and collaborative information (interactions between users and items). One approach to reduce the training dataset is to remove user-item interactions. But that significantly diminishes collaborative information, which is crucial for maintaining accuracy due to its inclusion of interaction histories. This loss profoundly impacts DLRM performance. This paper makes an important observation that if one can capture the user-item interaction history to enrich the user and item embeddings, then the interaction history can be compressed without losing model accuracy. Thus, this work, Collaborative Aware Data Compression (CADC), takes a two-step approach to training dataset compression. In the first step, we use matrix factorization of the user-item interaction matrix to create a novel embedding representation for both the users and items. Once the user and item embeddings are enriched by the interaction history information the approach then applies uniform random sampling of the training dataset to drastically reduce the training dataset size while minimizing model accuracy drop. The source code of CADC is available at \href{https://anonymous.4open.science/r/DSS-RM-8C1D/README.md}{https://anonymous.4open.science/r/DSS-RM-8C1D/README.md}.