 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEL: Context-Aware Dynamic Exit Layer for Efficient Self-Speculative Decoding
Paper and Code
Apr 08, 2025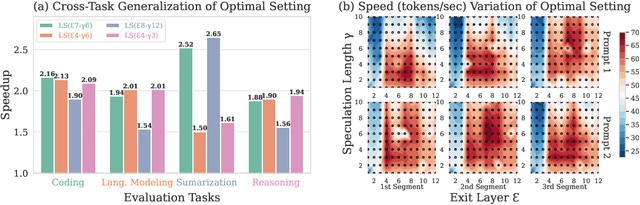
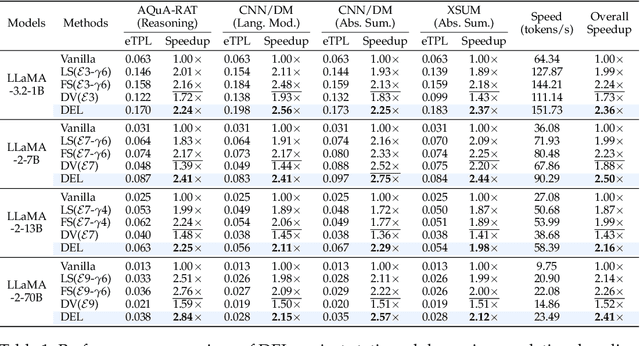
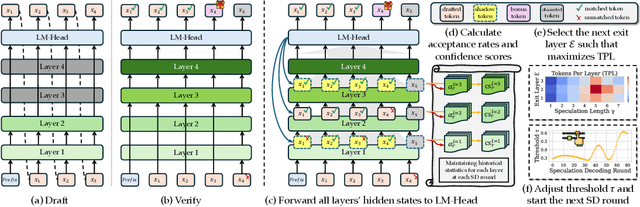

Speculative Decoding (SD) is a widely used approach to accelerate the inference of large language models (LLMs) without reducing generation quality. It operates by first using a compact model to draft multiple tokens efficiently, followed by parallel verification using the target LLM. This approach leads to faster inference compared to auto-regressive decoding. While there are multiple approaches to create a draft model, one promising approach is to use early-exit methods. These methods draft candidate tokens by using a subset of layers of the primary model and applying the remaining layers for verification, allowing a single model to handle both drafting and verification. While this technique reduces memory usage and computational cost, its performance relies on the choice of the exit layer for drafting and the number of tokens drafted (speculation length) in each SD round. Prior works use hyperparameter exploration to statically select these values. However, our evaluations show that these hyperparameter values are task-specific, and even within a task they are dependent on the current sequence context. We introduce DEL, a plug-and-play method that adaptively selects the exit layer and speculation length during inference. DEL dynamically tracks the token acceptance rate if the tokens are drafted at each layer of an LLM and uses that knowledge to heuristically select the optimal exit layer and speculation length. Our experiments across a broad range of models and downstream tasks show that DEL achieves overall speedups of $2.16\times$$\sim$$2.50\times$ over vanilla auto-regressive decoding and improves upon the state-of-the-art SD methods by up to $0.27\times$.