 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFluxNet: Learning Capacity-Constrained Local Transport Operators for Conservative and Bounded PDE Surrogates
Feb 02, 2026Autoregressive learning of time-stepping operators offers an effective approach to data-driven PDE simulation on grids. For conservation laws, however, long-horizon rollouts are often destabilized when learned updates violate global conservation and, in many applications, additional state bounds such as nonnegative mass and densities or concentrations constrained to [0,1]. Enforcing these coupled constraints via direct next-state regression remains difficult. We introduce a framework for learning conservative transport operators on regular grids, inspired by lattice Boltzmann-style discrete-velocity transport representations. Instead of predicting the next state, the model outputs local transport operators that update cells through neighborhood exchanges, guaranteeing discrete conservation by construction. For bounded quantities, we parameterize transport within a capacity-constrained feasible set, enforcing bounds structurally rather than by post-hoc clipping. We validate FluxNet on 1D convection-diffusion, 2D shallow water equations, 1D traffic flow, and 2D spinodal decomposition. Experiments on shallow-water equations and traffic flow show improved rollout stability and physical consistency over strong baselines. On phase-field spinodal decomposition, the method enables large time-steps with long-range transport, accelerating simulation while preserving microstructure evolution in both pointwise and statistical measures.
SanD-Planner: Sample-Efficient Diffusion Planner in B-Spline Space for Robust Local Navigation
Jan 31, 2026The challenge of generating reliable local plans has long hindered practical applications in highly cluttered and dynamic environments. Key fundamental bottlenecks include acquiring large-scale expert demonstrations across diverse scenes and improving learning efficiency with limited data. This paper proposes SanD-Planner, a sample-efficient diffusion-based local planner that conducts depth image-based imitation learning within the clamped B-spline space. By operating within this compact space, the proposed algorithm inherently yields smooth outputs with bounded prediction errors over local supports, naturally aligning with receding-horizon execution. Integration of an ESDF-based safety checker with explicit clearance and time-to-completion metrics further reduces the training burden associated with value-function learning for feasibility assessment. Experiments show that training with $500$ episodes (merely $0.25\%$ of the demonstration scale used by the baseline), SanD-Planner achieves state-of-the-art performance on the evaluated open benchmark, attaining success rates of $90.1\%$ in simulated cluttered environments and $72.0\%$ in indoor simulations. The performance is further proven by demonstrating zero-shot transferability to realistic experimentation in both 2D and 3D scenes. The dataset and pre-trained models will also be open-sourced.
Study of Brain Connectivity by Multichannel EEG Quaternion Principal Component Analysis for Alzheimer Disease Classification
May 21, 2025The early detection of Alzheimer's disease (AD) through widespread screening has emerged as a primary strategy to mitigate the significant global impact of AD. EEG measurements offer a promising solution for extensive AD detection. However, the intricate and nonlinear dynamics of multichannel EEG signals pose a considerable challenge for real-time AD diagnosis. This paper introduces a novel algorithm, which is based on Quaternion Principal Component Analysis (QPCA) of multichannel EEG signals, for AD classification. The algorithm extracts high dimensional correlations among different channels to generate features that are maximally representative with minimal information redundancy. This provides a multidimensional and precise measure of brain connectivity in disease assessment. Simulations have been conducted to evaluate the performance and to identify the most critical EEG channels or brain regions for AD classification. The results reveal a significant drop of connectivity measure in the alpha bands. The average AD classification accuracy for all 4-channel combinations reached 95%, while some particular permutations of channels achieved 100% accuracy rate. Furthermore, the temporal lobe emerges as one of the most important regions in AD classification given that the EEG signals are recorded during the presentation of an auditory stimulant. The selection of key parameters of the QPCA algorithm have been evaluated and some recommendations are proposed for further performance enhancement. This paper marks the first application of the QPCA algorithm for AD classification and brain connectivity analysis using multichannel EEG signals.
AcoustoBots: A swarm of robots for acoustophoretic multimodal interactions
May 12, 2025Acoustophoresis has enabled novel interaction capabilities, such as levitation, volumetric displays, mid-air haptic feedback, and directional sound generation, to open new forms of multimodal interactions. However, its traditional implementation as a singular static unit limits its dynamic range and application versatility. This paper introduces AcoustoBots - a novel convergence of acoustophoresis with a movable and reconfigurable phased array of transducers for enhanced application versatility. We mount a phased array of transducers on a swarm of robots to harness the benefits of multiple mobile acoustophoretic units. This offers a more flexible and interactive platform that enables a swarm of acoustophoretic multimodal interactions. Our novel AcoustoBots design includes a hinge actuation system that controls the orientation of the mounted phased array of transducers to achieve high flexibility in a swarm of acoustophoretic multimodal interactions. In addition, we designed a BeadDispenserBot that can deliver particles to trapping locations, which automates the acoustic levitation interaction. These attributes allow AcoustoBots to independently work for a common cause and interchange between modalities, allowing for novel augmentations (e.g., a swarm of haptics, audio, and levitation) and bilateral interactions with users in an expanded interaction area. We detail our design considerations, challenges, and methodological approach to extend acoustophoretic central control in distributed settings. This work demonstrates a scalable acoustic control framework with two mobile robots, laying the groundwork for future deployment in larger robotic swarms. Finally, we characterize the performance of our AcoustoBots and explore the potential interactive scenarios they can enable.
Efficient Jailbreaking of Large Models by Freeze Training: Lower Layers Exhibit Greater Sensitivity to Harmful Content
Feb 28, 2025



With the widespread application of Large Language Models across various domains, their security issues have increasingly garnered significant attention from both academic and industrial communities. This study conducts sampling and normalization of the parameters of the LLM to generate visual representations and heatmaps of parameter distributions, revealing notable discrepancies in parameter distributions among certain layers within the hidden layers. Further analysis involves calculating statistical metrics for each layer, followed by the computation of a Comprehensive Sensitivity Score based on these metrics, which identifies the lower layers as being particularly sensitive to the generation of harmful content. Based on this finding, we employ a Freeze training strategy, selectively performing Supervised Fine-Tuning only on the lower layers. Experimental results demonstrate that this method significantly reduces training duration and GPU memory consumption while maintaining a high jailbreak success rate and a high harm score, outperforming the results achieved by applying the LoRA method for SFT across all layers. Additionally, the method has been successfully extended to other open-source large models, validating its generality and effectiveness across different model architectures. Furthermore, we compare our method with ohter jailbreak method, demonstrating the superior performance of our approach. By innovatively proposing a method to statistically analyze and compare large model parameters layer by layer, this study provides new insights into the interpretability of large models. These discoveries emphasize the necessity of continuous research and the implementation of adaptive security measures in the rapidly evolving field of LLMs to prevent potential jailbreak attack risks, thereby promoting the development of more robust and secure LLMs.
AbdomenAtlas: A Large-Scale, Detailed-Annotated, & Multi-Center Dataset for Efficient Transfer Learning and Open Algorithmic Benchmarking
Jul 23, 2024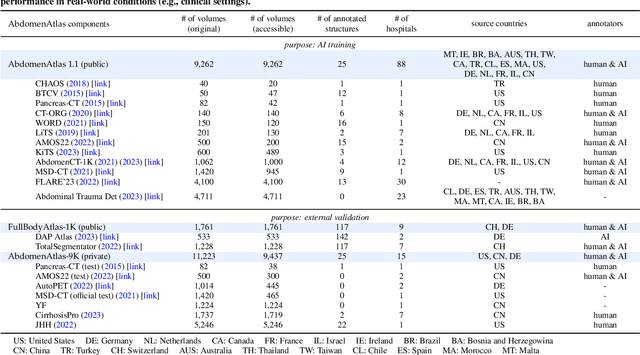


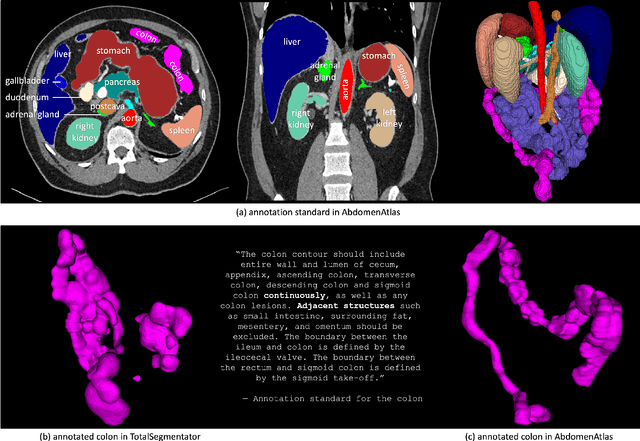
We introduce the largest abdominal CT dataset (termed AbdomenAtlas) of 20,460 three-dimensional CT volumes sourced from 112 hospitals across diverse populations, geographies, and facilities. AbdomenAtlas provides 673K high-quality masks of anatomical structures in the abdominal region annotated by a team of 10 radiologists with the help of AI algorithms. We start by having expert radiologists manually annotate 22 anatomical structures in 5,246 CT volumes. Following this, a semi-automatic annotation procedure is performed for the remaining CT volumes, where radiologists revise the annotations predicted by AI, and in turn, AI improves its predictions by learning from revised annotations. Such a large-scale, detailed-annotated, and multi-center dataset is needed for two reasons. Firstly, AbdomenAtlas provides important resources for AI development at scale, branded as large pre-trained models, which can alleviate the annotation workload of expert radiologists to transfer to broader clinical applications. Secondly, AbdomenAtlas establishes a large-scale benchmark for evaluating AI algorithms -- the more data we use to test the algorithms, the better we can guarantee reliable performance in complex clinical scenarios. An ISBI & MICCAI challenge named BodyMaps: Towards 3D Atlas of Human Body was launched using a subset of our AbdomenAtlas, aiming to stimulate AI innovation and to benchmark segmentation accuracy, inference efficiency, and domain generalizability. We hope our AbdomenAtlas can set the stage for larger-scale clinical trials and offer exceptional opportunities to practitioners in the medical imaging community. Codes, models, and datasets are available at https://www.zongweiz.com/dataset
Generalized Mixture Model for Extreme Events Forecasting in Time Series Data
Oct 11, 2023



Time Series Forecasting (TSF) is a widely researched topic with broad applications in weather forecasting, traffic control, and stock price prediction. Extreme values in time series often significantly impact human and natural systems, but predicting them is challenging due to their rare occurrence. Statistical methods based on Extreme Value Theory (EVT) provide a systematic approach to modeling the distribution of extremes, particularly the Generalized Pareto (GP) distribution for modeling the distribution of exceedances beyond a threshold. To overcome the subpar performance of deep learning in dealing with heavy-tailed data, we propose a novel framework to enhance the focus on extreme events. Specifically, we propose a Deep Extreme Mixture Model with Autoencoder (DEMMA) for time series prediction. The model comprises two main modules: 1) a generalized mixture distribution based on the Hurdle model and a reparameterized GP distribution form independent of the extreme threshold, 2) an Autoencoder-based LSTM feature extractor and a quantile prediction module with a temporal attention mechanism. We demonstrate the effectiveness of our approach on multiple real-world rainfall datasets.