 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation-Based Attention Entropy: Detecting and Mitigating Object Hallucinations in Large Vision-Language Models
Mar 17, 2026Large Vision-Language Models (LVLMs) achieve strong performance on many multimodal tasks, but object hallucinations severely undermine their reliability. Most existing studies focus on the text modality, attributing hallucinations to overly strong language priors and insufficient visual grounding. In contrast, we observe that abnormal attention patterns within the visual modality can also give rise to hallucinated objects. Building on this observation, we propose Segmentation-based Attention Entropy (SAE), which leverages semantic segmentation to quantify visual attention uncertainty in an object-level semantic space. Based on SAE, we further design a reliability score for hallucination detection and an SAE-guided attention adjustment method that modifies visual attention at inference time to mitigate hallucinations. We evaluate our approach on public benchmarks and in real embodied multimodal scenarios with quadruped robots. Experimental results show that SAE substantially reduces object hallucinations without any additional training cost, thereby enabling more trustworthy LVLM-driven perception and decision-making.
Self-motion as a structural prior for coherent and robust formation of cognitive maps
Dec 23, 2025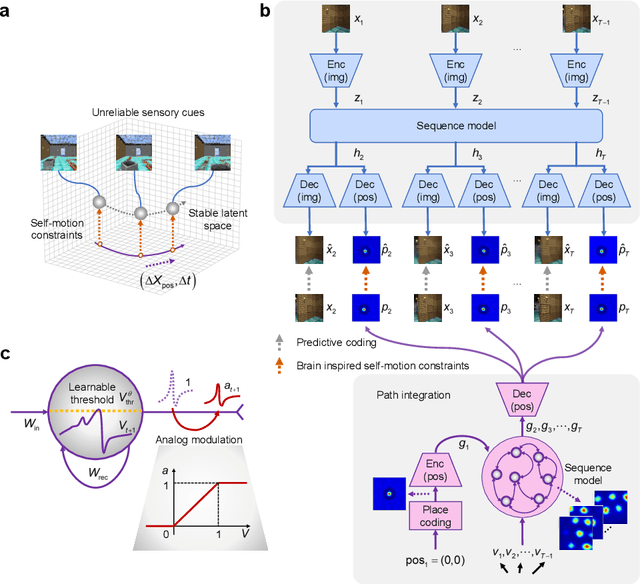
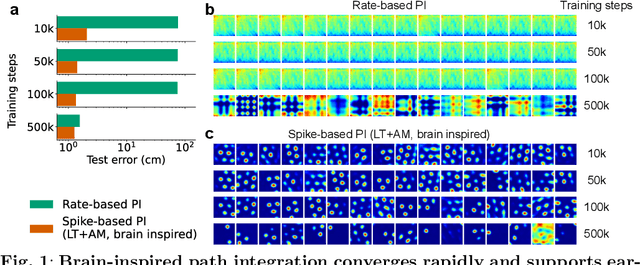
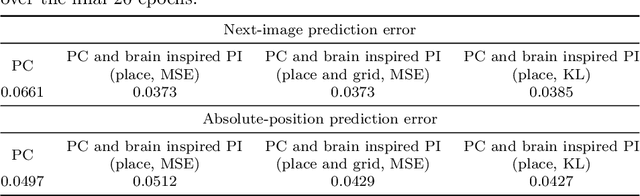
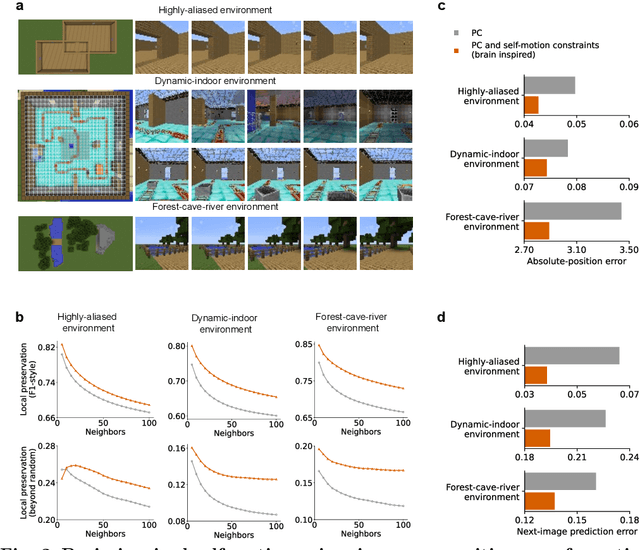
Most computational accounts of cognitive maps assume that stability is achieved primarily through sensory anchoring, with self-motion contributing to incremental positional updates only. However, biological spatial representations often remain coherent even when sensory cues degrade or conflict, suggesting that self-motion may play a deeper organizational role. Here, we show that self-motion can act as a structural prior that actively organizes the geometry of learned cognitive maps. We embed a path-integration-based motion prior in a predictive-coding framework, implemented using a capacity-efficient, brain-inspired recurrent mechanism combining spiking dynamics, analog modulation and adaptive thresholds. Across highly aliased, dynamically changing and naturalistic environments, this structural prior consistently stabilizes map formation, improving local topological fidelity, global positional accuracy and next-step prediction under sensory ambiguity. Mechanistic analyses reveal that the motion prior itself encodes geometrically precise trajectories under tight constraints of internal states and generalizes zero-shot to unseen environments, outperforming simpler motion-based constraints. Finally, deployment on a quadrupedal robot demonstrates that motion-derived structural priors enhance online landmark-based navigation under real-world sensory variability. Together, these results reframe self-motion as an organizing scaffold for coherent spatial representations, showing how brain-inspired principles can systematically strengthen spatial intelligence in embodied artificial agents.
Local Data Quantity-Aware Weighted Averaging for Federated Learning with Dishonest Clients
Apr 17, 2025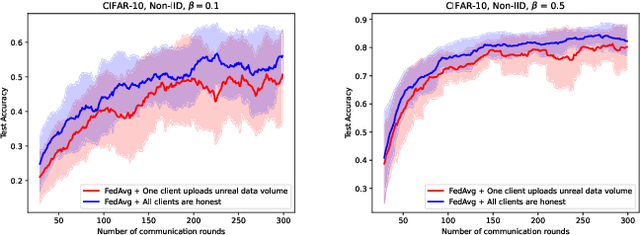
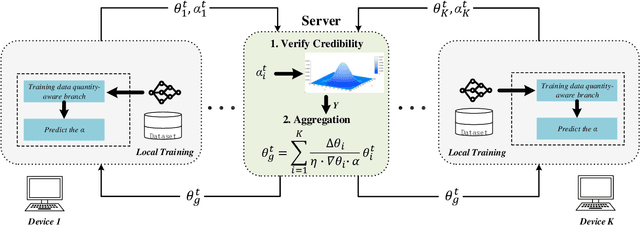
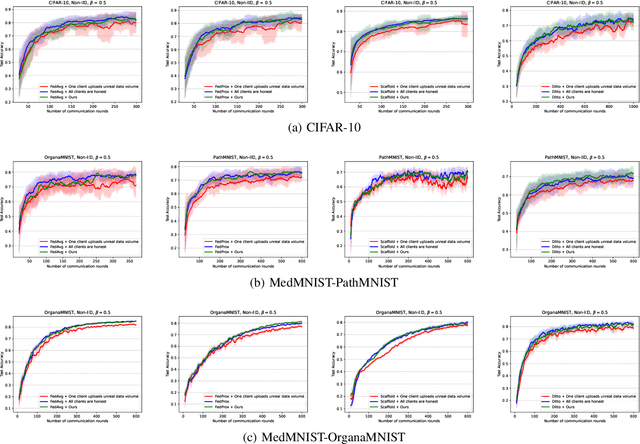
Federated learning (FL) enables collaborative training of deep learning models without requiring data to leave local clients, thereby preserving client privacy. The aggregation process on the server plays a critical role in the performance of the resulting FL model. The most commonly used aggregation method is weighted averaging based on the amount of data from each client, which is thought to reflect each client's contribution. However, this method is prone to model bias, as dishonest clients might report inaccurate training data volumes to the server, which is hard to verify. To address this issue, we propose a novel secure \underline{Fed}erated \underline{D}ata q\underline{u}antity-\underline{a}ware weighted averaging method (FedDua). It enables FL servers to accurately predict the amount of training data from each client based on their local model gradients uploaded. Furthermore, it can be seamlessly integrated into any FL algorithms that involve server-side model aggregation. Extensive experiments on three benchmarking datasets demonstrate that FedDua improves the global model performance by an average of 3.17% compared to four popular FL aggregation methods in the presence of inaccurate client data volume declarations.
Multi-Target Federated Backdoor Attack Based on Feature Aggregation
Feb 23, 2025



Current federated backdoor attacks focus on collaboratively training backdoor triggers, where multiple compromised clients train their local trigger patches and then merge them into a global trigger during the inference phase. However, these methods require careful design of the shape and position of trigger patches and lack the feature interactions between trigger patches during training, resulting in poor backdoor attack success rates. Moreover, the pixels of the patches remain untruncated, thereby making abrupt areas in backdoor examples easily detectable by the detection algorithm. To this end, we propose a novel benchmark for the federated backdoor attack based on feature aggregation. Specifically, we align the dimensions of triggers with images, delimit the trigger's pixel boundaries, and facilitate feature interaction among local triggers trained by each compromised client. Furthermore, leveraging the intra-class attack strategy, we propose the simultaneous generation of backdoor triggers for all target classes, significantly reducing the overall production time for triggers across all target classes and increasing the risk of the federated model being attacked. Experiments demonstrate that our method can not only bypass the detection of defense methods while patch-based methods fail, but also achieve a zero-shot backdoor attack with a success rate of 77.39%. To the best of our knowledge, our work is the first to implement such a zero-shot attack in federated learning. Finally, we evaluate attack performance by varying the trigger's training factors, including poison location, ratio, pixel bound, and trigger training duration (local epochs and communication rounds).
Multi-Objective Evolutionary for Object Detection Mobile Architectures Search
Nov 05, 2022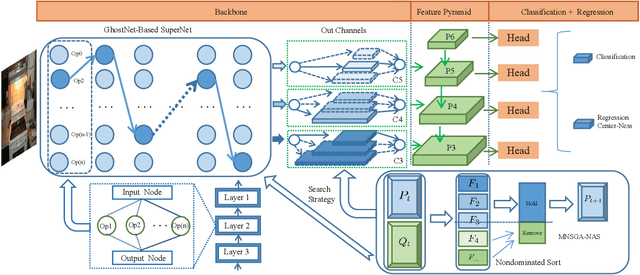

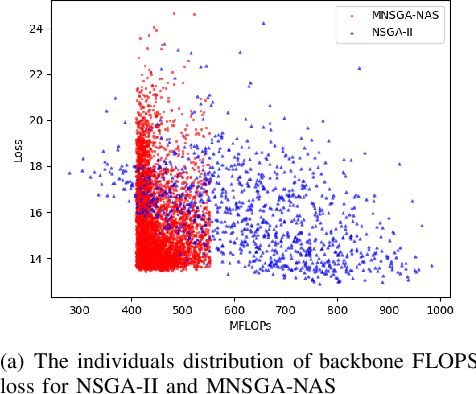

Recently, Neural architecture search has achieved great success on classification tasks for mobile devices. The backbone network for object detection is usually obtained on the image classification task. However, the architecture which is searched through the classification task is sub-optimal because of the gap between the task of image and object detection. As while work focuses on backbone network architecture search for mobile device object detection is limited, mainly because the backbone always requires expensive ImageNet pre-training. Accordingly, it is necessary to study the approach of network architecture search for mobile device object detection without expensive pre-training. In this work, we propose a mobile object detection backbone network architecture search algorithm which is a kind of evolutionary optimized method based on non-dominated sorting for NAS scenarios. It can quickly search to obtain the backbone network architecture within certain constraints. It better solves the problem of suboptimal linear combination accuracy and computational cost. The proposed approach can search the backbone networks with different depths, widths, or expansion sizes via a technique of weight mapping, making it possible to use NAS for mobile devices detection tasks a lot more efficiently. In our experiments, we verify the effectiveness of the proposed approach on YoloX-Lite, a lightweight version of the target detection framework. Under similar computational complexity, the accuracy of the backbone network architecture we search for is 2.0% mAP higher than MobileDet. Our improved backbone network can reduce the computational effort while improving the accuracy of the object detection network. To prove its effectiveness, a series of ablation studies have been carried out and the working mechanism has been analyzed in detail.
Distribution Learning Based on Evolutionary Algorithm Assisted Deep Neural Networks for Imbalanced Image Classification
Jul 26, 2022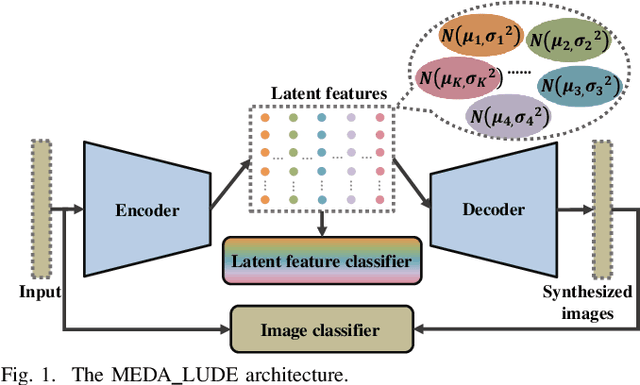
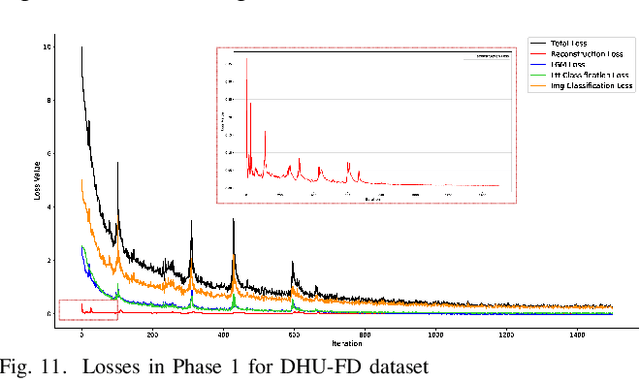

To address the trade-off problem of quality-diversity for the generated images in imbalanced classification tasks, we research on over-sampling based methods at the feature level instead of the data level and focus on searching the latent feature space for optimal distributions. On this basis, we propose an iMproved Estimation Distribution Algorithm based Latent featUre Distribution Evolution (MEDA_LUDE) algorithm, where a joint learning procedure is programmed to make the latent features both optimized and evolved by the deep neural networks and the evolutionary algorithm, respectively. We explore the effect of the Large-margin Gaussian Mixture (L-GM) loss function on distribution learning and design a specialized fitness function based on the similarities among samples to increase diversity. Extensive experiments on benchmark based imbalanced datasets validate the effectiveness of our proposed algorithm, which can generate images with both quality and diversity. Furthermore, the MEDA_LUDE algorithm is also applied to the industrial field and successfully alleviates the imbalanced issue in fabric defect classification.
Vision Transformer with Convolutions Architecture Search
Mar 20, 2022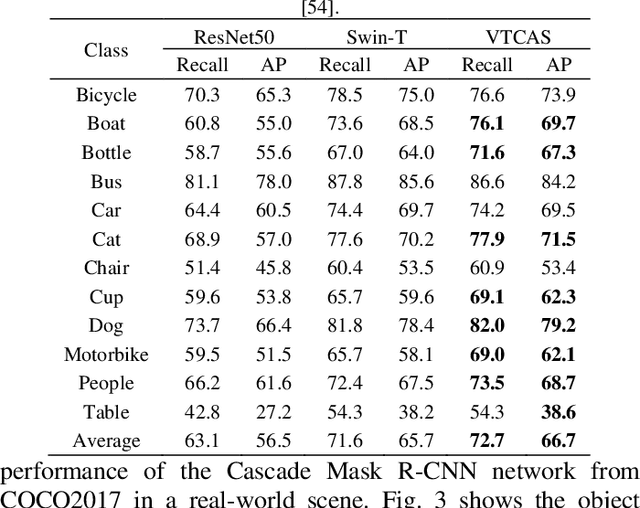

Transformers exhibit great advantages in handling computer vision tasks. They model image classification tasks by utilizing a multi-head attention mechanism to process a series of patches consisting of split images. However, for complex tasks, Transformer in computer vision not only requires inheriting a bit of dynamic attention and global context, but also needs to introduce features concerning noise reduction, shifting, and scaling invariance of objects. Therefore, here we take a step forward to study the structural characteristics of Transformer and convolution and propose an architecture search method-Vision Transformer with Convolutions Architecture Search (VTCAS). The high-performance backbone network searched by VTCAS introduces the desirable features of convolutional neural networks into the Transformer architecture while maintaining the benefits of the multi-head attention mechanism. The searched block-based backbone network can extract feature maps at different scales. These features are compatible with a wider range of visual tasks, such as image classification (32 M parameters, 82.0% Top-1 accuracy on ImageNet-1K) and object detection (50.4% mAP on COCO2017). The proposed topology based on the multi-head attention mechanism and CNN adaptively associates relational features of pixels with multi-scale features of objects. It enhances the robustness of the neural network for object recognition, especially in the low illumination indoor scene.
Visual Sensation and Perception Computational Models for Deep Learning: State of the art, Challenges and Prospects
Sep 08, 2021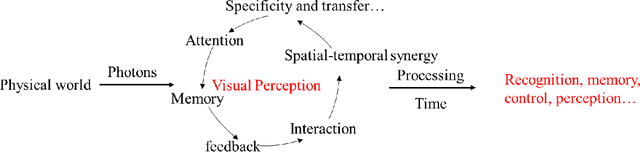
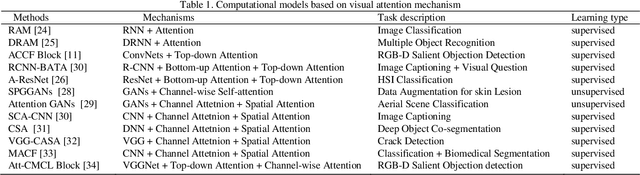


Visual sensation and perception refers to the process of sensing, organizing, identifying, and interpreting visual information in environmental awareness and understanding. Computational models inspired by visual perception have the characteristics of complexity and diversity, as they come from many subjects such as cognition science, information science, and artificial intelligence. In this paper, visual perception computational models oriented deep learning are investigated from the biological visual mechanism and computational vision theory systematically. Then, some points of view about the prospects of the visual perception computational models are presented. Finally, this paper also summarizes the current challenges of visual perception and predicts its future development trends. Through this survey, it will provide a comprehensive reference for research in this direction.
Enhanced Gradient for Differentiable Architecture Search
Mar 23, 2021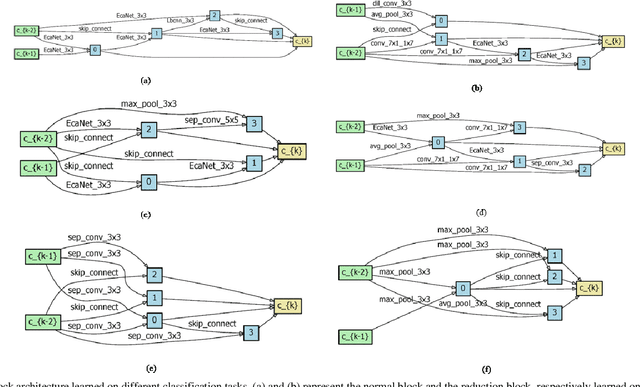
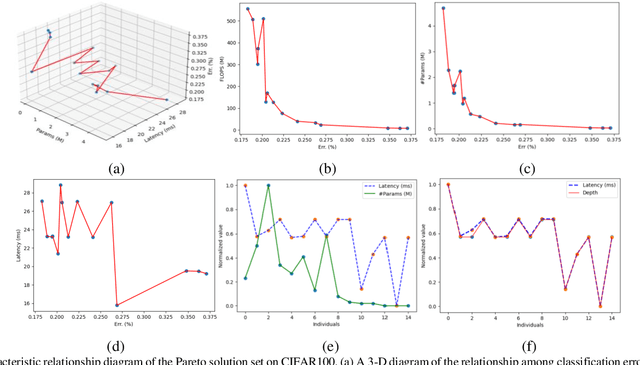
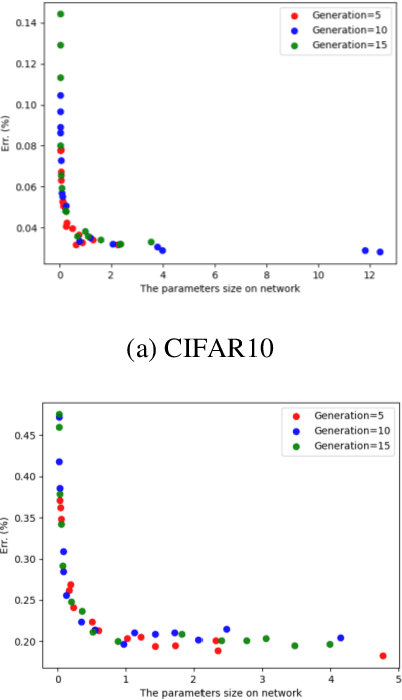
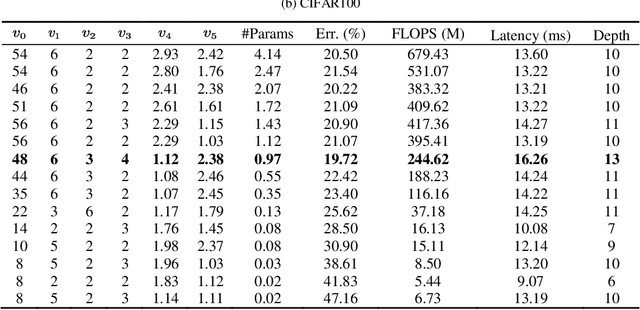
In recent years, neural architecture search (NAS) methods have been proposed for the automatic generation of task-oriented network architecture in image classification. However, the architectures obtained by existing NAS approaches are optimized only for classification performance and do not adapt to devices with limited computational resources. To address this challenge, we propose a neural network architecture search algorithm aiming to simultaneously improve network performance (e.g., classification accuracy) and reduce network complexity. The proposed framework automatically builds the network architecture at two stages: block-level search and network-level search. At the stage of block-level search, a relaxation method based on the gradient is proposed, using an enhanced gradient to design high-performance and low-complexity blocks. At the stage of network-level search, we apply an evolutionary multi-objective algorithm to complete the automatic design from blocks to the target network. The experiment results demonstrate that our method outperforms all evaluated hand-crafted networks in image classification, with an error rate of on CIFAR10 and an error rate of on CIFAR100, both at network parameter size less than one megabit. Moreover, compared with other neural architecture search methods, our method offers a tremendous reduction in designed network architecture parameters.
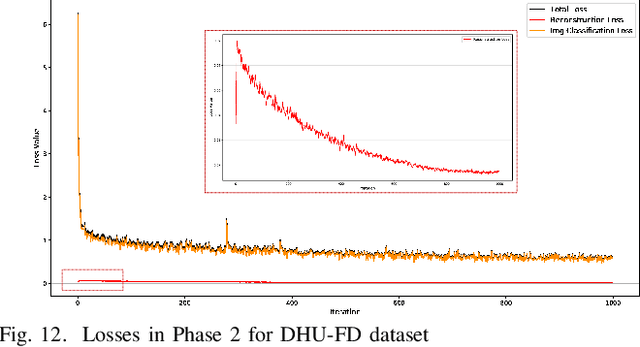
MLMA-Net: multi-level multi-attentional learning for multi-label object detection in textile defect images
Jan 31, 2021

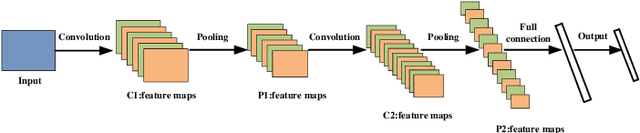
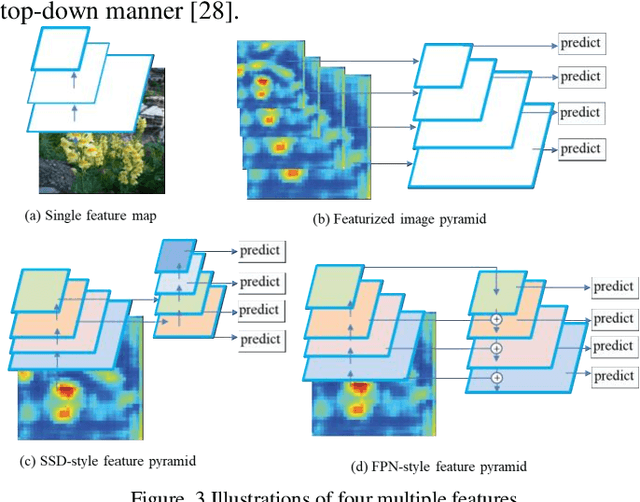
For the sake of recognizing and classifying textile defects, deep learning-based methods have been proposed and achieved remarkable success in single-label textile images. However, detecting multi-label defects in a textile image remains challenging due to the coexistence of multiple defects and small-size defects. To address these challenges, a multi-level, multi-attentional deep learning network (MLMA-Net) is proposed and built to 1) increase the feature representation ability to detect small-size defects; 2) generate a discriminative representation that maximizes the capability of attending the defect status, which leverages higher-resolution feature maps for multiple defects. Moreover, a multi-label object detection dataset (DHU-ML1000) in textile defect images is built to verify the performance of the proposed model. The results demonstrate that the network extracts more distinctive features and has better performance than the state-of-the-art approaches on the real-world industrial dataset.