 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformer with Convolutions Architecture Search
Mar 20, 2022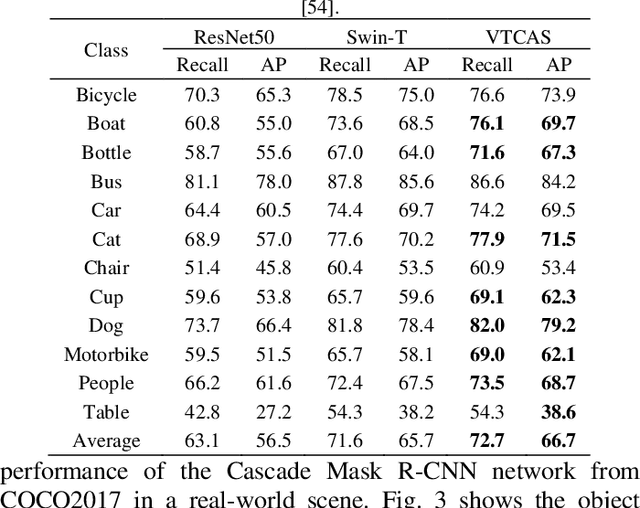

Transformers exhibit great advantages in handling computer vision tasks. They model image classification tasks by utilizing a multi-head attention mechanism to process a series of patches consisting of split images. However, for complex tasks, Transformer in computer vision not only requires inheriting a bit of dynamic attention and global context, but also needs to introduce features concerning noise reduction, shifting, and scaling invariance of objects. Therefore, here we take a step forward to study the structural characteristics of Transformer and convolution and propose an architecture search method-Vision Transformer with Convolutions Architecture Search (VTCAS). The high-performance backbone network searched by VTCAS introduces the desirable features of convolutional neural networks into the Transformer architecture while maintaining the benefits of the multi-head attention mechanism. The searched block-based backbone network can extract feature maps at different scales. These features are compatible with a wider range of visual tasks, such as image classification (32 M parameters, 82.0% Top-1 accuracy on ImageNet-1K) and object detection (50.4% mAP on COCO2017). The proposed topology based on the multi-head attention mechanism and CNN adaptively associates relational features of pixels with multi-scale features of objects. It enhances the robustness of the neural network for object recognition, especially in the low illumination indoor scene.
Enhanced Gradient for Differentiable Architecture Search
Mar 23, 2021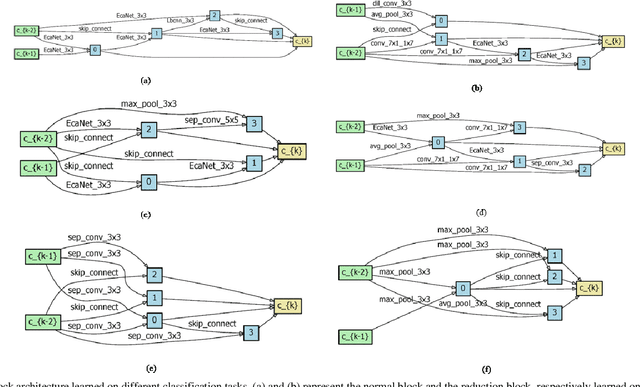
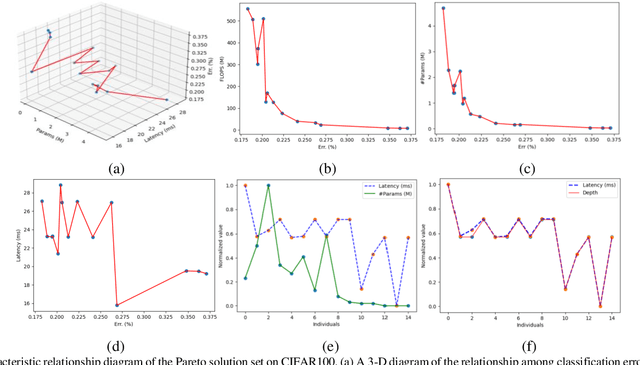
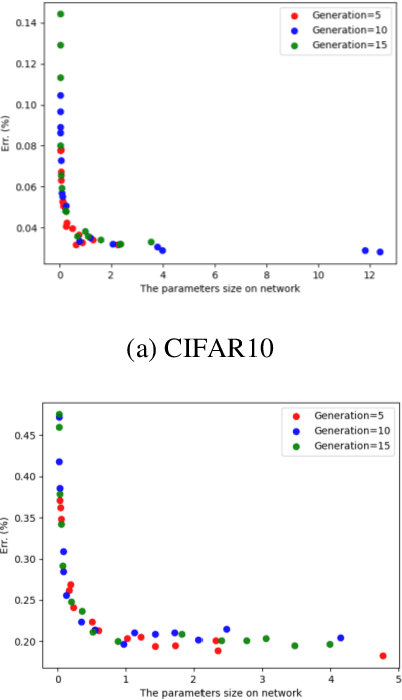
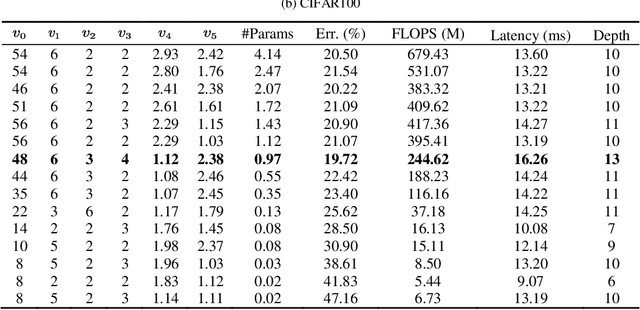
In recent years, neural architecture search (NAS) methods have been proposed for the automatic generation of task-oriented network architecture in image classification. However, the architectures obtained by existing NAS approaches are optimized only for classification performance and do not adapt to devices with limited computational resources. To address this challenge, we propose a neural network architecture search algorithm aiming to simultaneously improve network performance (e.g., classification accuracy) and reduce network complexity. The proposed framework automatically builds the network architecture at two stages: block-level search and network-level search. At the stage of block-level search, a relaxation method based on the gradient is proposed, using an enhanced gradient to design high-performance and low-complexity blocks. At the stage of network-level search, we apply an evolutionary multi-objective algorithm to complete the automatic design from blocks to the target network. The experiment results demonstrate that our method outperforms all evaluated hand-crafted networks in image classification, with an error rate of on CIFAR10 and an error rate of on CIFAR100, both at network parameter size less than one megabit. Moreover, compared with other neural architecture search methods, our method offers a tremendous reduction in designed network architecture parameters.
Optimizing Deep Neural Networks through Neuroevolution with Stochastic Gradient Descent
Dec 21, 2020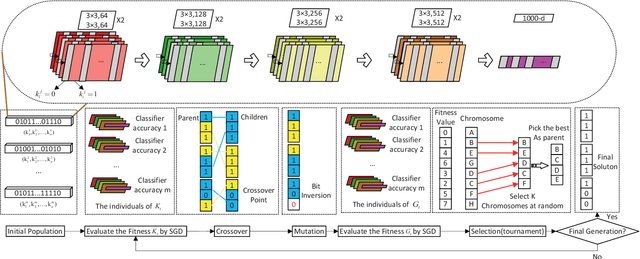

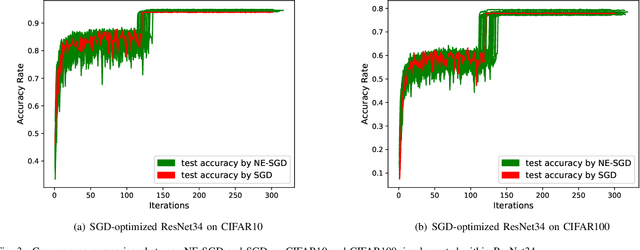
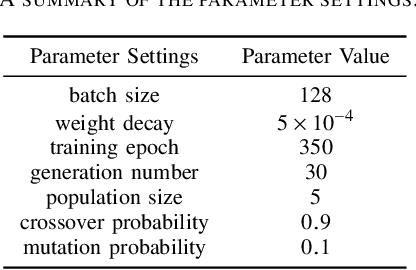
Deep neural networks (DNNs) have achieved remarkable success in computer vision; however, training DNNs for satisfactory performance remains challenging and suffers from sensitivity to empirical selections of an optimization algorithm for training. Stochastic gradient descent (SGD) is dominant in training a DNN by adjusting neural network weights to minimize the DNNs loss function. As an alternative approach, neuroevolution is more in line with an evolutionary process and provides some key capabilities that are often unavailable in SGD, such as the heuristic black-box search strategy based on individual collaboration in neuroevolution. This paper proposes a novel approach that combines the merits of both neuroevolution and SGD, enabling evolutionary search, parallel exploration, and an effective probe for optimal DNNs. A hierarchical cluster-based suppression algorithm is also developed to overcome similar weight updates among individuals for improving population diversity. We implement the proposed approach in four representative DNNs based on four publicly-available datasets. Experiment results demonstrate that the four DNNs optimized by the proposed approach all outperform corresponding ones optimized by only SGD on all datasets. The performance of DNNs optimized by the proposed approach also outperforms state-of-the-art deep networks. This work also presents a meaningful attempt for pursuing artificial general intelligence.