 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-centric AI Model for Unruptured Intracranial Aneurysm Detection and Volumetric Segmentation in 3D TOF-MRI
Aug 30, 2024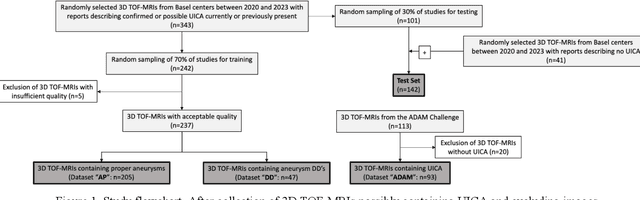
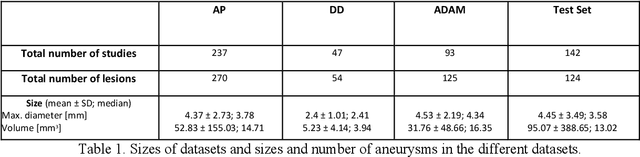
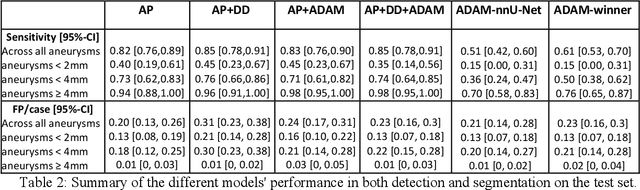
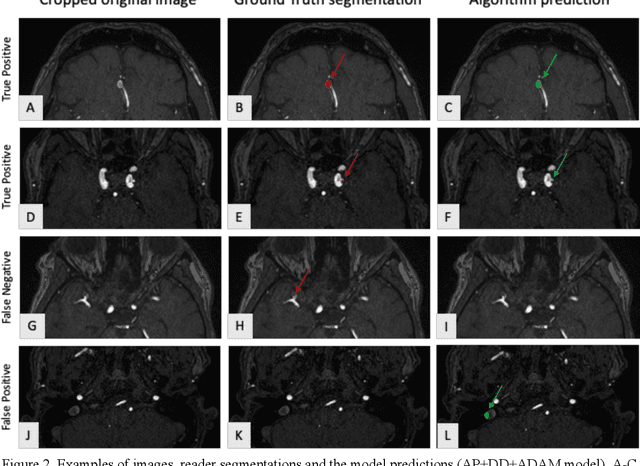
Purpose: To develop an open-source nnU-Net-based AI model for combined detection and segmentation of unruptured intracranial aneurysms (UICA) in 3D TOF-MRI, and compare models trained on datasets with aneurysm-like differential diagnoses. Methods: This retrospective study (2020-2023) included 385 anonymized 3D TOF-MRI images from 364 patients (mean age 59 years, 60% female) at multiple centers plus 113 subjects from the ADAM challenge. Images featured untreated or possible UICAs and differential diagnoses. Four distinct training datasets were created, and the nnU-Net framework was used for model development. Performance was assessed on a separate test set using sensitivity and False Positive (FP)/case rate for detection, and DICE score and NSD (Normalized Surface Distance) with a 0.5mm threshold for segmentation. Statistical analysis included chi-square, Mann-Whitney-U, and Kruskal-Wallis tests, with significance set at p < 0.05. Results: Models achieved overall sensitivity between 82% and 85% and a FP/case rate of 0.20 to 0.31, with no significant differences (p = 0.90 and p = 0.16). The primary model showed 85% sensitivity and 0.23 FP/case rate, outperforming the ADAM-challenge winner (61%) and a nnU-Net trained on ADAM data (51%) in sensitivity (p < 0.05). It achieved a mean DICE score of 0.73 and an NSD of 0.84 for correctly detected UICA. Conclusions: Our open-source, nnU-Net-based AI model (available at 10.5281/zenodo.13386859) demonstrates high sensitivity, low false positive rates, and consistent segmentation accuracy for UICA detection and segmentation in 3D TOF-MRI, suggesting its potential to improve clinical diagnosis and for monitoring of UICA.
Appearance Learning for Image-based Motion Estimation in Tomography
Jun 18, 2020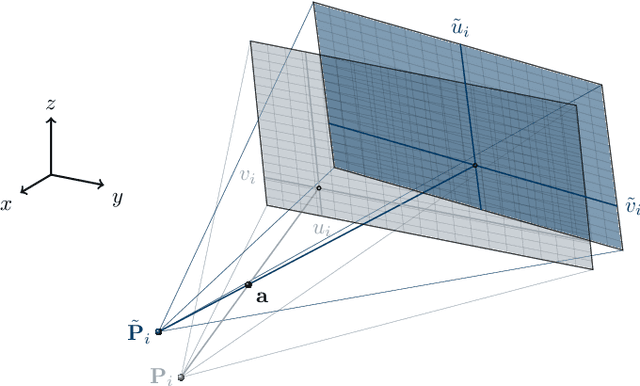
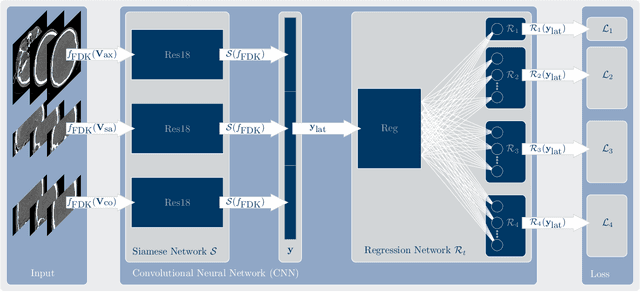
In tomographic imaging, anatomical structures are reconstructed by applying a pseudo-inverse forward model to acquired signals. Geometric information within this process is usually depending on the system setting only, i. e., the scanner position or readout direction. Patient motion therefore corrupts the geometry alignment in the reconstruction process resulting in motion artifacts. We propose an appearance learning approach recognizing the structures of rigid motion independently from the scanned object. To this end, we train a siamese triplet network to predict the reprojection error (RPE) for the complete acquisition as well as an approximate distribution of the RPE along the single views from the reconstructed volume in a multi-task learning approach. The RPE measures the motioninduced geometric deviations independent of the object based on virtual marker positions, which are available during training. We train our network using 27 patients and deploy a 21-4-2 split for training, validation and testing. In average, we achieve a residual mean RPE of 0.013mm with an inter-patient standard deviation of 0.022 mm. This is twice the accuracy compared to previously published results. In a motion estimation benchmark the proposed approach achieves superior results in comparison with two state-of-the-art measures in nine out of twelve experiments. The clinical applicability of the proposed method is demonstrated on a motion-affected clinical dataset.
Deep autofocus with cone-beam CT consistency constraint
Dec 04, 2019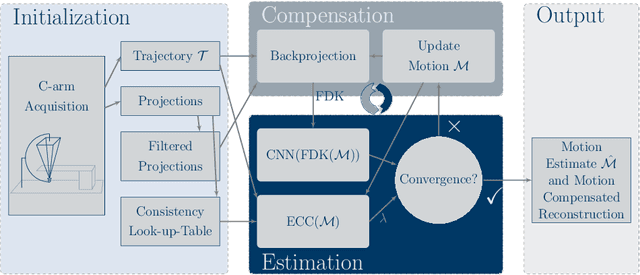
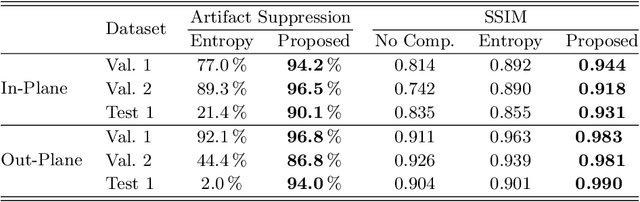
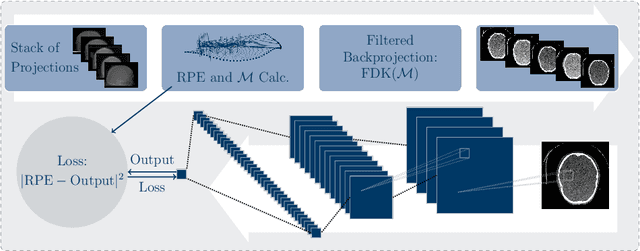
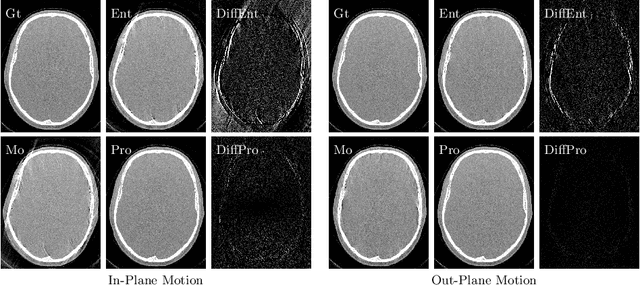
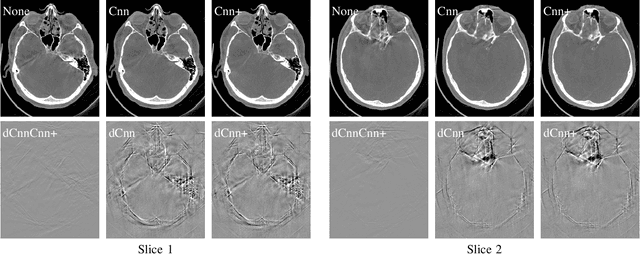
High quality reconstruction with interventional C-arm cone-beam computed tomography (CBCT) requires exact geometry information. If the geometry information is corrupted, e. g., by unexpected patient or system movement, the measured signal is misplaced in the backprojection operation. With prolonged acquisition times of interventional C-arm CBCT the likelihood of rigid patient motion increases. To adapt the backprojection operation accordingly, a motion estimation strategy is necessary. Recently, a novel learning-based approach was proposed, capable of compensating motions within the acquisition plane. We extend this method by a CBCT consistency constraint, which was proven to be efficient for motions perpendicular to the acquisition plane. By the synergistic combination of these two measures, in and out-plane motion is well detectable, achieving an average artifact suppression of 93 [percent]. This outperforms the entropy-based state-of-the-art autofocus measure which achieves on average an artifact suppression of 54 [percent].
Image Quality Assessment for Rigid Motion Compensation
Oct 09, 2019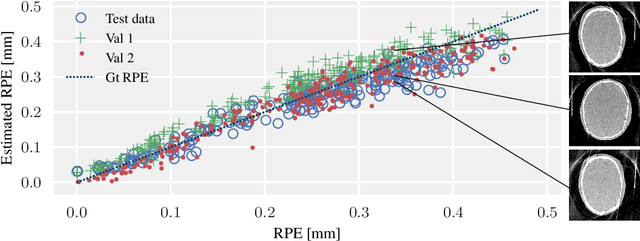
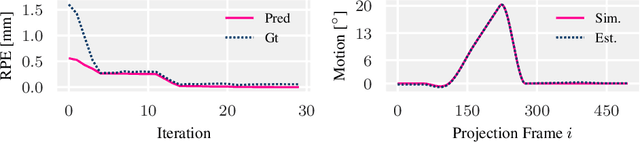
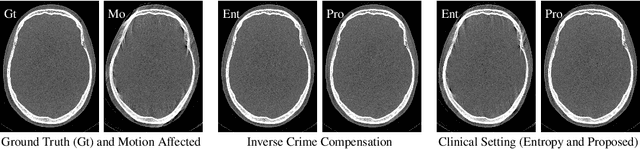
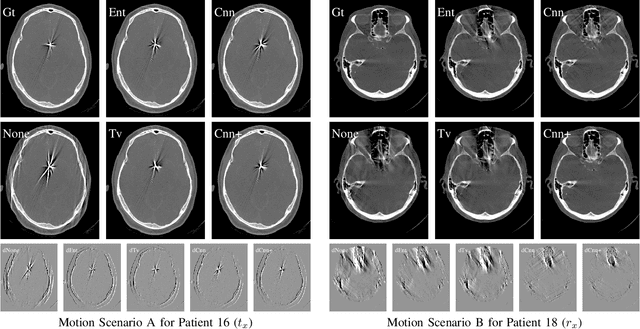
Diagnostic stroke imaging with C-arm cone-beam computed tomography (CBCT) enables reduction of time-to-therapy for endovascular procedures. However, the prolonged acquisition time compared to helical CT increases the likelihood of rigid patient motion. Rigid motion corrupts the geometry alignment assumed during reconstruction, resulting in image blurring or streaking artifacts. To reestablish the geometry, we estimate the motion trajectory by an autofocus method guided by a neural network, which was trained to regress the reprojection error, based on the image information of a reconstructed slice. The network was trained with CBCT scans from 19 patients and evaluated using an additional test patient. It adapts well to unseen motion amplitudes and achieves superior results in a motion estimation benchmark compared to the commonly used entropy-based method.