 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Probabilistic Deep Learning Methods for License Plate Recognition
Feb 02, 2023



Learning-based algorithms for automated license plate recognition implicitly assume that the training and test data are well aligned. However, this may not be the case under extreme environmental conditions, or in forensic applications where the system cannot be trained for a specific acquisition device. Predictions on such out-of-distribution images have an increased chance of failing. But this failure case is oftentimes hard to recognize for a human operator or an automated system. Hence, in this work we propose to model the prediction uncertainty for license plate recognition explicitly. Such an uncertainty measure allows to detect false predictions, indicating an analyst when not to trust the result of the automated license plate recognition. In this paper, we compare three methods for uncertainty quantification on two architectures. The experiments on synthetic noisy or blurred low-resolution images show that the predictive uncertainty reliably finds wrong predictions. We also show that a multi-task combination of classification and super-resolution improves the recognition performance by 109\% and the detection of wrong predictions by 29 %.
Deep learning architectural designs for super-resolution of noisy images
Feb 09, 2021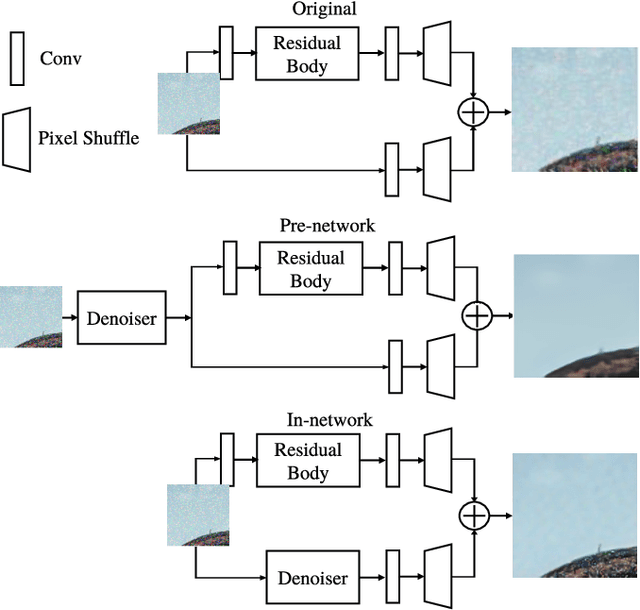

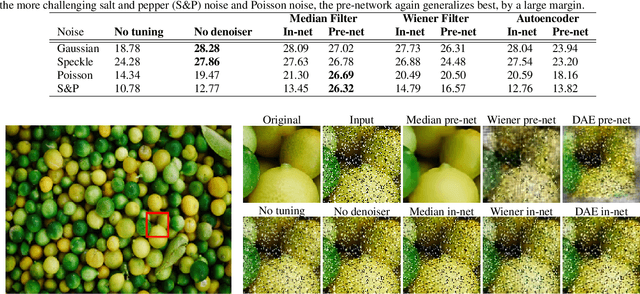

Recent advances in deep learning have led to significant improvements in single image super-resolution (SR) research. However, due to the amplification of noise during the upsampling steps, state-of-the-art methods often fail at reconstructing high-resolution images from noisy versions of their low-resolution counterparts. However, this is especially important for images from unknown cameras with unseen types of image degradation. In this work, we propose to jointly perform denoising and super-resolution. To this end, we investigate two architectural designs: "in-network" combines both tasks at feature level, while "pre-network" first performs denoising and then super-resolution. Our experiments show that both variants have specific advantages: The in-network design obtains the strongest results when the type of image corruption is aligned in the training and testing dataset, for any choice of denoiser. The pre-network design exhibits superior performance on unseen types of image corruption, which is a pathological failure case of existing super-resolution models. We hope that these findings help to enable super-resolution also in less constrained scenarios where source camera or imaging conditions are not well controlled. Source code and pretrained models are available at https://github.com/ angelvillar96/super-resolution-noisy-images.
Multi-modal Deep Guided Filtering for Comprehensible Medical Image Processing
Nov 18, 2019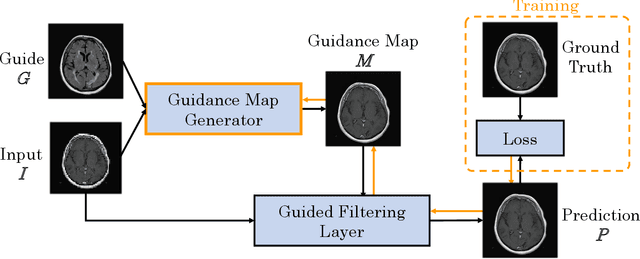
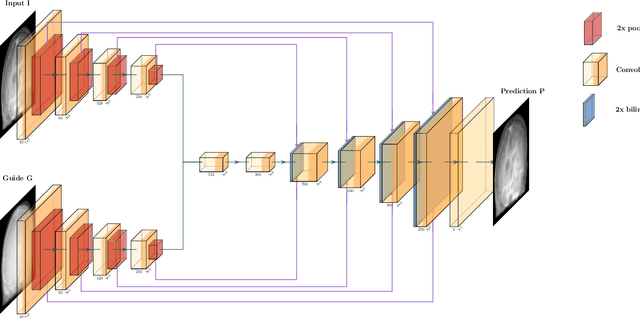
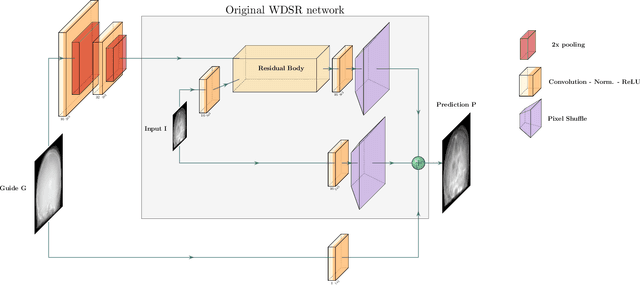
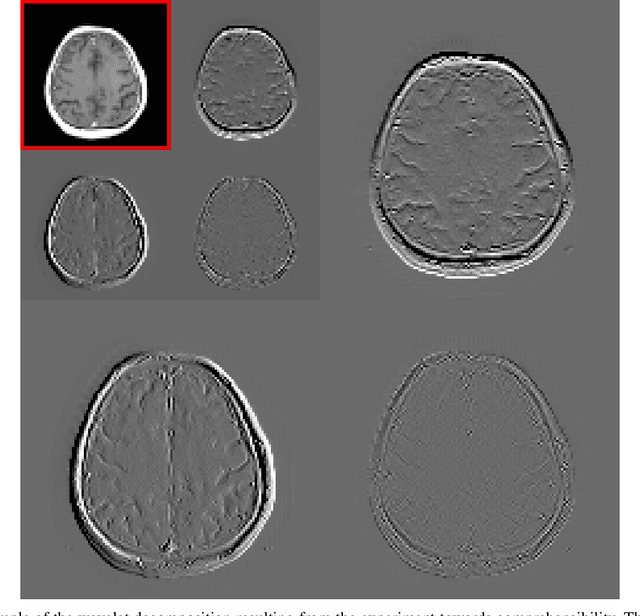
Deep learning-based image processing is capable of creating highly appealing results. However, it is still widely considered as a "blackbox" transformation. In medical imaging, this lack of comprehensibility of the results is a sensitive issue. The integration of known operators into the deep learning environment has proven to be advantageous for the comprehensibility and reliability of the computations. Consequently, we propose the use of the locally linear guided filter in combination with a learned guidance map for general purpose medical image processing. The output images are only processed by the guided filter while the guidance map can be trained to be task-optimal in an end-to-end fashion. We investigate the performance based on two popular tasks: image super resolution and denoising. The evaluation is conducted based on pairs of multi-modal magnetic resonance imaging and cross-modal computed tomography and magnetic resonance imaging datasets. For both tasks, the proposed approach is on par with state-of-the-art approaches. Additionally, we can show that the input image's content is almost unchanged after the processing which is not the case for conventional deep learning approaches. On top, the proposed pipeline offers increased robustness against degraded input as well as adversarial attacks.
Merging-ISP: Multi-Exposure High Dynamic Range Image Signal Processing
Nov 12, 2019
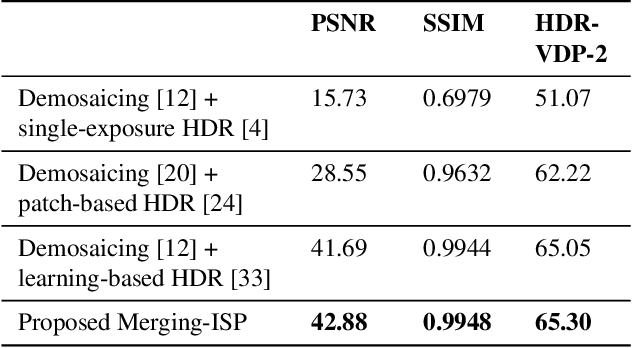

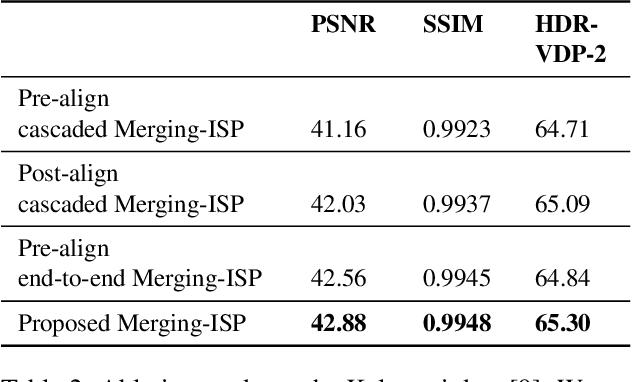
The image signal processing pipeline (ISP) is a core element of digital cameras to capture high-quality displayable images from raw data. In high dynamic range (HDR) imaging, ISPs include steps like demosaicing of raw color filter array (CFA) data at different exposure times, alignment of the exposures, conversion to HDR domain, and exposure merging into an HDR image. Traditionally, such pipelines are built by cascading algorithms addressing the individual subtasks. However, cascaded designs suffer from error propagations since simply combining multiple processing steps is not necessarily optimal for the entire imaging task. This paper proposes a multi-exposure high dynamic range image signal processing pipeline (Merging-ISP) to jointly solve all subtasks for HDR imaging. Our pipeline is modeled by a deep neural network architecture. As such, it is end-to-end trainable, circumvents the use of complex, hand-crafted algorithms in its core, and mitigates error propagation. Merging-ISP enables direct reconstructions of HDR images from multiple differently exposed raw CFA images captured from dynamic scenes. We compared Merging-ISP against different alternative cascaded pipelines. End-to-end learning leads to HDR reconstructions of high perceptual quality and quantitatively outperforms competing ISPs by more than 1 dB in terms of PSNR.
Magnetic Resonance Fingerprinting Reconstruction Using Recurrent Neural Networks
Sep 13, 2019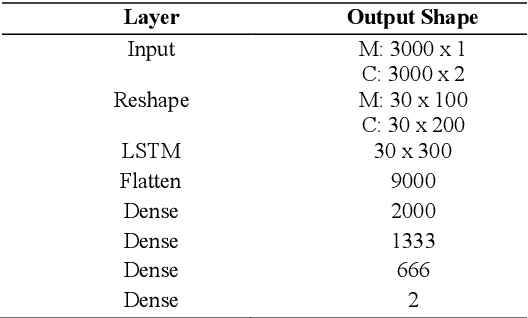
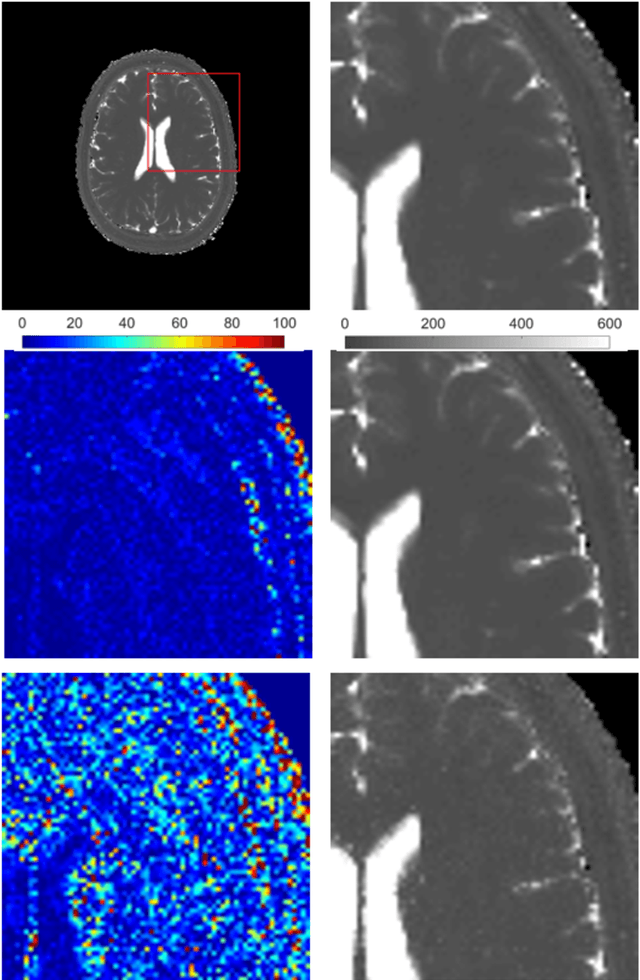
Magnetic Resonance Fingerprinting (MRF) is an imaging technique acquiring unique time signals for different tissues. Although the acquisition is highly accelerated, the reconstruction time remains a problem, as the state-of-the-art template matching compares every signal with a set of possible signals. To overcome this limitation, deep learning based approaches, e.g. Convolutional Neural Networks (CNNs) have been proposed. In this work, we investigate the applicability of Recurrent Neural Networks (RNNs) for this reconstruction problem, as the signals are correlated in time. Compared to previous methods based on CNNs, RNN models yield significantly improved results using in-vivo data.
* Accepted and presented at the German Medical Data Sciences (GMDS) conference 2019 (Dortmund, Germany)
RinQ Fingerprinting: Recurrence-informed Quantile Networks for Magnetic Resonance Fingerprinting
Jul 21, 2019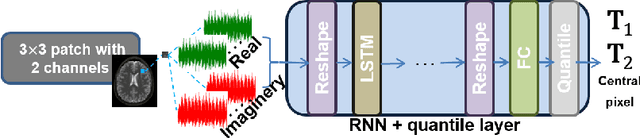
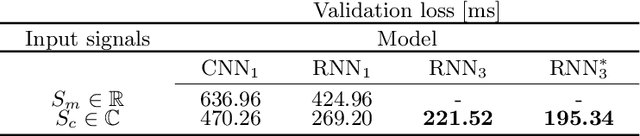
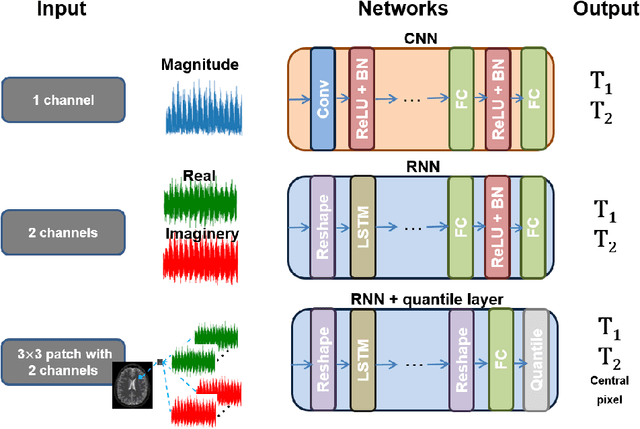
Recently, Magnetic Resonance Fingerprinting (MRF) was proposed as a quantitative imaging technique for the simultaneous acquisition of tissue parameters such as relaxation times $T_1$ and $T_2$. Although the acquisition is highly accelerated, the state-of-the-art reconstruction suffers from long computation times: Template matching methods are used to find the most similar signal to the measured one by comparing it to pre-simulated signals of possible parameter combinations in a discretized dictionary. Deep learning approaches can overcome this limitation, by providing the direct mapping from the measured signal to the underlying parameters by one forward pass through a network. In this work, we propose a Recurrent Neural Network (RNN) architecture in combination with a novel quantile layer. RNNs are well suited for the processing of time-dependent signals and the quantile layer helps to overcome the noisy outliers by considering the spatial neighbors of the signal. We evaluate our approach using in-vivo data from multiple brain slices and several volunteers, running various experiments. We show that the RNN approach with small patches of complex-valued input signals in combination with a quantile layer outperforms other architectures, e.g. previously proposed CNNs for the MRF reconstruction reducing the error in $T_1$ and $T_2$ by more than 80%.
Temporal and Volumetric Denoising via Quantile Sparse Image (QuaSI) Prior in Optical Coherence Tomography and Beyond
Jul 05, 2018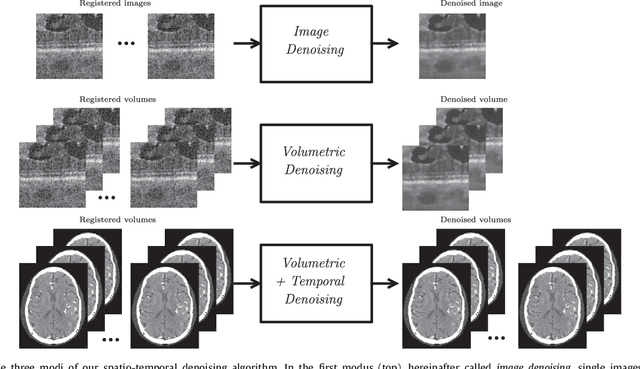


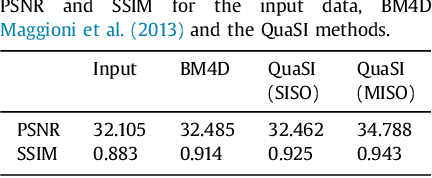
This paper introduces an universal and structure-preserving regularization term, called quantile sparse image (QuaSI) prior. The prior is suitable for denoising images from various medical imaging modalities. We demonstrate its effectiveness on volumetric optical coherence tomography (OCT) and computed tomography (CT) data, which show different noise and image characteristics. OCT offers high-resolution scans of the human retina but is inherently impaired by speckle noise. CT on the other hand has a lower resolution and shows high-frequency noise. For the purpose of denoising, we propose a variational framework based on the QuaSI prior and a Huber data fidelity model that can handle 3-D and 3-D+t data. Efficient optimization is facilitated through the use of an alternating direction method of multipliers (ADMM) scheme and the linearization of the quantile filter. Experiments on multiple datasets emphasize the excellent performance of the proposed method.
Adaptive Quantile Sparse Image (AQuaSI) Prior for Inverse Imaging Problems
Apr 06, 2018



Inverse problems play a central role for many classical computer vision and image processing tasks. A key challenge in solving an inverse problem is to find an appropriate prior to convert an ill-posed problem into a well-posed task. Many of the existing priors, like total variation, are based on ad-hoc assumptions that have difficulties to represent the actual distribution of natural images. In this work, we propose the Adaptive Quantile Sparse Image (AQuaSI) prior. It is based on a quantile filter, can be used as a joint filter on guidance data, and be readily plugged into a wide range of numerical optimization algorithms. We demonstrate the efficacy of the proposed prior in joint RGB/depth upsampling, on RGB/NIR image restoration, and in a comparison with related regularization by denoising approaches.
QuaSI: Quantile Sparse Image Prior for Spatio-Temporal Denoising of Retinal OCT Data
Mar 08, 2017
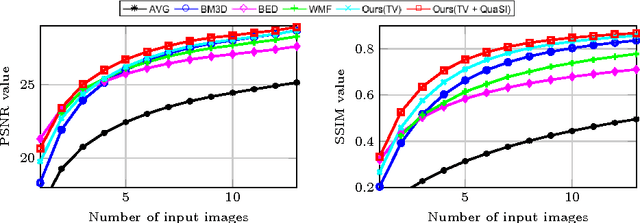

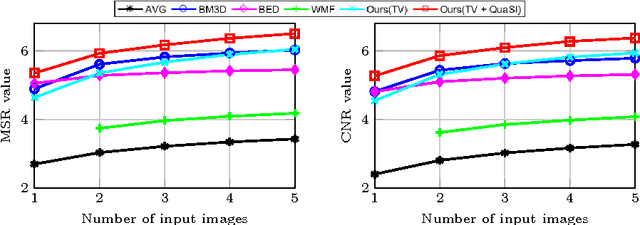
Optical coherence tomography (OCT) enables high-resolution and non-invasive 3D imaging of the human retina but is inherently impaired by speckle noise. This paper introduces a spatio-temporal denoising algorithm for OCT data on a B-scan level using a novel quantile sparse image (QuaSI) prior. To remove speckle noise while preserving image structures of diagnostic relevance, we implement our QuaSI prior via median filter regularization coupled with a Huber data fidelity model in a variational approach. For efficient energy minimization, we develop an alternating direction method of multipliers (ADMM) scheme using a linearization of median filtering. Our spatio-temporal method can handle both, denoising of single B-scans and temporally consecutive B-scans, to gain volumetric OCT data with enhanced signal-to-noise ratio. Our algorithm based on 4 B-scans only achieved comparable performance to averaging 13 B-scans and outperformed other current denoising methods.