 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Probabilistic Deep Learning Methods for License Plate Recognition
Feb 02, 2023



Learning-based algorithms for automated license plate recognition implicitly assume that the training and test data are well aligned. However, this may not be the case under extreme environmental conditions, or in forensic applications where the system cannot be trained for a specific acquisition device. Predictions on such out-of-distribution images have an increased chance of failing. But this failure case is oftentimes hard to recognize for a human operator or an automated system. Hence, in this work we propose to model the prediction uncertainty for license plate recognition explicitly. Such an uncertainty measure allows to detect false predictions, indicating an analyst when not to trust the result of the automated license plate recognition. In this paper, we compare three methods for uncertainty quantification on two architectures. The experiments on synthetic noisy or blurred low-resolution images show that the predictive uncertainty reliably finds wrong predictions. We also show that a multi-task combination of classification and super-resolution improves the recognition performance by 109\% and the detection of wrong predictions by 29 %.
Synthesizing Annotated Image and Video Data Using a Rendering-Based Pipeline for Improved License Plate Recognition
Sep 28, 2022


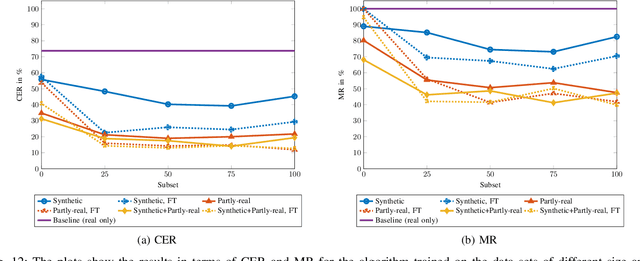
An insufficient number of training samples is a common problem in neural network applications. While data augmentation methods require at least a minimum number of samples, we propose a novel, rendering-based pipeline for synthesizing annotated data sets. Our method does not modify existing samples but synthesizes entirely new samples. The proposed rendering-based pipeline is capable of generating and annotating synthetic and partly-real image and video data in a fully automatic procedure. Moreover, the pipeline can aid the acquisition of real data. The proposed pipeline is based on a rendering process. This process generates synthetic data. Partly-real data bring the synthetic sequences closer to reality by incorporating real cameras during the acquisition process. The benefits of the proposed data generation pipeline, especially for machine learning scenarios with limited available training data, are demonstrated by an extensive experimental validation in the context of automatic license plate recognition. The experiments demonstrate a significant reduction of the character error rate and miss rate from 73.74% and 100% to 14.11% and 41.27% respectively, compared to an OCR algorithm trained on a real data set solely. These improvements are achieved by training the algorithm on synthesized data solely. When additionally incorporating real data, the error rates can be decreased further. Thereby, the character error rate and miss rate can be reduced to 11.90% and 39.88% respectively. All data used during the experiments as well as the proposed rendering-based pipeline for the automated data generation is made publicly available under (URL will be revealed upon publication).
3D Rendering Framework for Data Augmentation in Optical Character Recognition
Sep 27, 2022
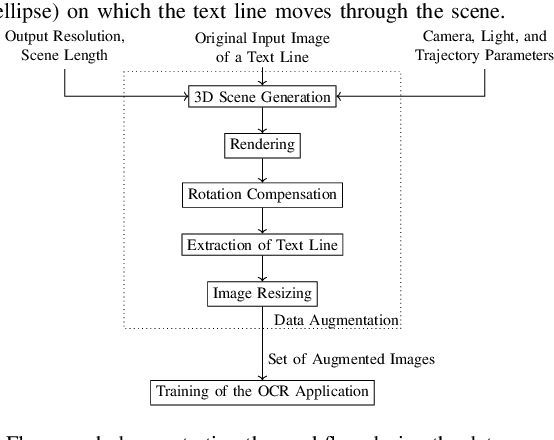

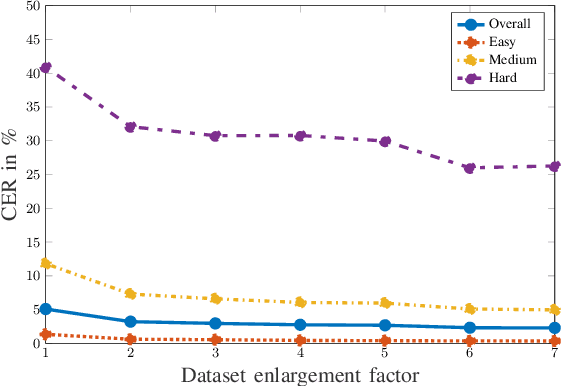
In this paper, we propose a data augmentation framework for Optical Character Recognition (OCR). The proposed framework is able to synthesize new viewing angles and illumination scenarios, effectively enriching any available OCR dataset. Its modular structure allows to be modified to match individual user requirements. The framework enables to comfortably scale the enlargement factor of the available dataset. Furthermore, the proposed method is not restricted to single frame OCR but can also be applied to video OCR. We demonstrate the performance of our framework by augmenting a 15% subset of the common Brno Mobile OCR dataset. Our proposed framework is capable of leveraging the performance of OCR applications especially for small datasets. Applying the proposed method, improvements of up to 2.79 percentage points in terms of Character Error Rate (CER), and up to 7.88 percentage points in terms of Word Error Rate (WER) are achieved on the subset. Especially the recognition of challenging text lines can be improved. The CER may be decreased by up to 14.92 percentage points and the WER by up to 18.19 percentage points for this class. Moreover, we are able to achieve smaller error rates when training on the 15% subset augmented with the proposed method than on the original non-augmented full dataset.
Forensic License Plate Recognition with Compression-Informed Transformers
Jul 29, 2022
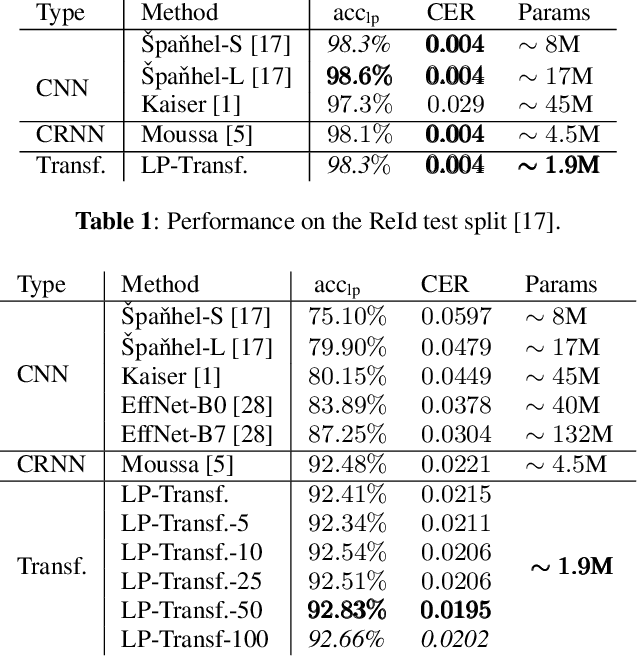

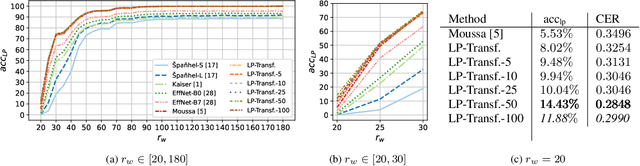
Forensic license plate recognition (FLPR) remains an open challenge in legal contexts such as criminal investigations, where unreadable license plates (LPs) need to be deciphered from highly compressed and/or low resolution footage, e.g., from surveillance cameras. In this work, we propose a side-informed Transformer architecture that embeds knowledge on the input compression level to improve recognition under strong compression. We show the effectiveness of Transformers for license plate recognition (LPR) on a low-quality real-world dataset. We also provide a synthetic dataset that includes strongly degraded, illegible LP images and analyze the impact of knowledge embedding on it. The network outperforms existing FLPR methods and standard state-of-the art image recognition models while requiring less parameters. For the severest degraded images, we can improve recognition by up to 8.9 percent points.
Toward Reliable Models for Authenticating Multimedia Content: Detecting Resampling Artifacts With Bayesian Neural Networks
Jul 28, 2020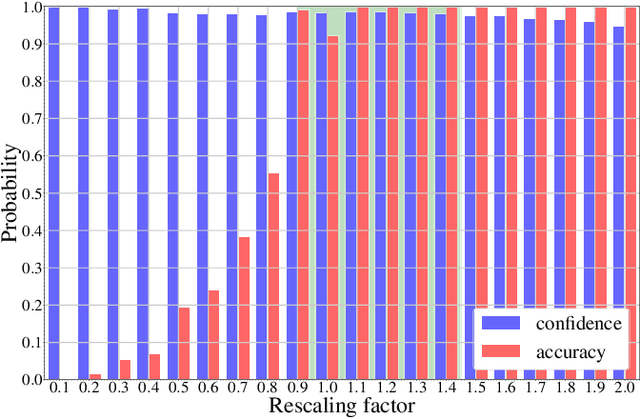
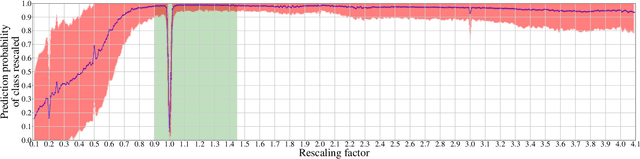
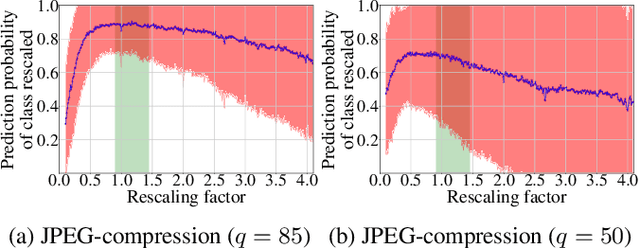
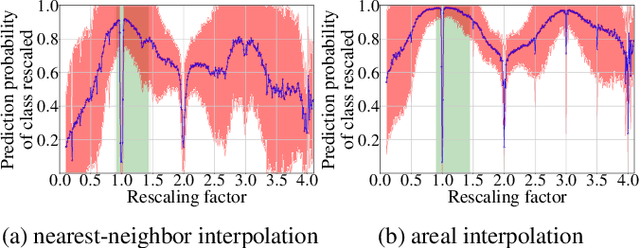
In multimedia forensics, learning-based methods provide state-of-the-art performance in determining origin and authenticity of images and videos. However, most existing methods are challenged by out-of-distribution data, i.e., with characteristics that are not covered in the training set. This makes it difficult to know when to trust a model, particularly for practitioners with limited technical background. In this work, we make a first step toward redesigning forensic algorithms with a strong focus on reliability. To this end, we propose to use Bayesian neural networks (BNN), which combine the power of deep neural networks with the rigorous probabilistic formulation of a Bayesian framework. Instead of providing a point estimate like standard neural networks, BNNs provide distributions that express both the estimate and also an uncertainty range. We demonstrate the usefulness of this framework on a classical forensic task: resampling detection. The BNN yields state-of-the-art detection performance, plus excellent capabilities for detecting out-of-distribution samples. This is demonstrated for three pathologic issues in resampling detection, namely unseen resampling factors, unseen JPEG compression, and unseen resampling algorithms. We hope that this proposal spurs further research toward reliability in multimedia forensics.