 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Rendering Framework for Data Augmentation in Optical Character Recognition
Paper and Code
Sep 27, 2022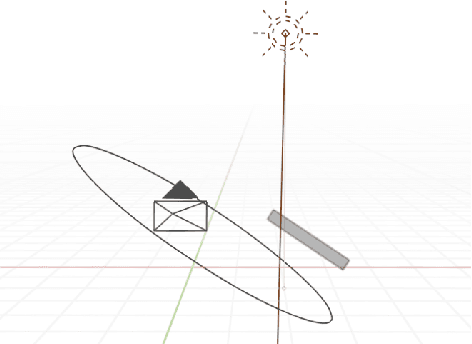
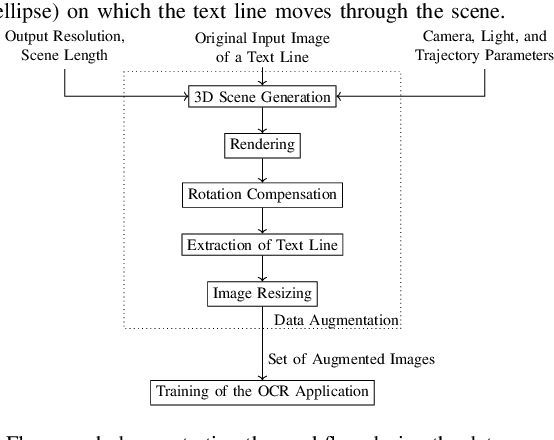

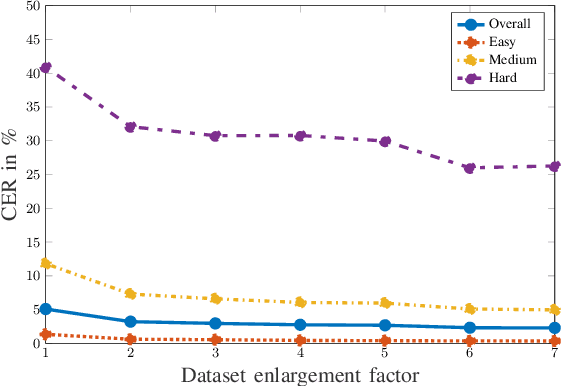
In this paper, we propose a data augmentation framework for Optical Character Recognition (OCR). The proposed framework is able to synthesize new viewing angles and illumination scenarios, effectively enriching any available OCR dataset. Its modular structure allows to be modified to match individual user requirements. The framework enables to comfortably scale the enlargement factor of the available dataset. Furthermore, the proposed method is not restricted to single frame OCR but can also be applied to video OCR. We demonstrate the performance of our framework by augmenting a 15% subset of the common Brno Mobile OCR dataset. Our proposed framework is capable of leveraging the performance of OCR applications especially for small datasets. Applying the proposed method, improvements of up to 2.79 percentage points in terms of Character Error Rate (CER), and up to 7.88 percentage points in terms of Word Error Rate (WER) are achieved on the subset. Especially the recognition of challenging text lines can be improved. The CER may be decreased by up to 14.92 percentage points and the WER by up to 18.19 percentage points for this class. Moreover, we are able to achieve smaller error rates when training on the 15% subset augmented with the proposed method than on the original non-augmented full dataset.