 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Geometry and Attribute Upsampling of Point Clouds Using Frequency-Selective Models with Overlapped Support
Jan 27, 2023With the increasing demand of capturing our environment in three-dimensions for AR/ VR applications and autonomous driving among others, the importance of high-resolution point clouds rises. As the capturing process is a complex task, point cloud upsampling is often desired. We propose Frequency-Selective Upsampling (FSU), an upsampling scheme that upsamples geometry and attribute information of point clouds jointly in a sequential manner with overlapped support areas. The point cloud is partitioned into blocks with overlapping support area first. Then, a continuous frequency model is generated that estimates the point cloud's surface locally. The model is sampled at new positions for upsampling. In a subsequent step, another frequency model is created that models the attribute signal. Here, knowledge from the geometry upsampling is exploited for a simplified projection of the points in two dimensions. The attribute model is evaluated for the upsampled geometry positions. In our extensive evaluation, we evaluate geometry and attribute upsampling independently and show joint results. The geometry results show best performances for our proposed FSU in terms of point-to-plane error and plane-to-plane angular similarity. Moreover, FSU outperforms other color upsampling schemes by 1.9 dB in terms of color PSNR. In addition, the visual appearance of the point clouds clearly increases with FSU.
Jointly Resampling and Reconstructing Corrupted Images for Image Classification
Oct 31, 2022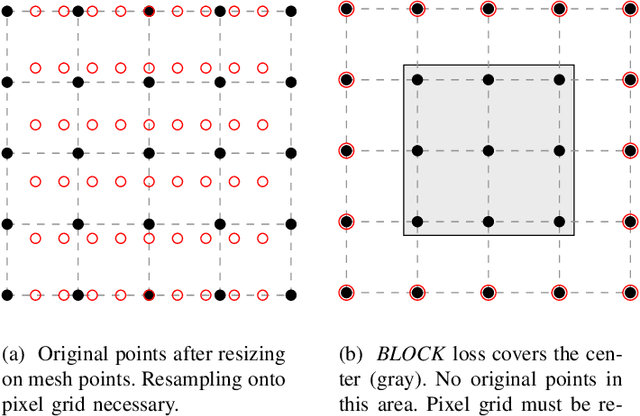
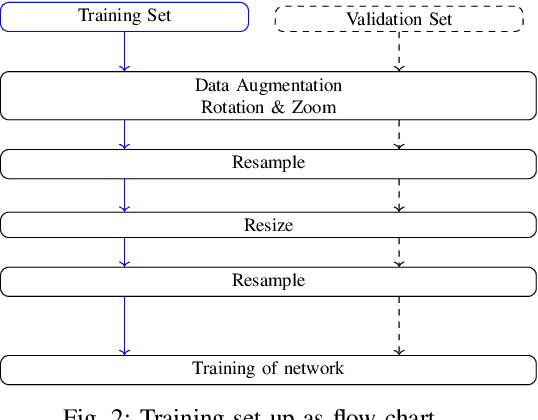
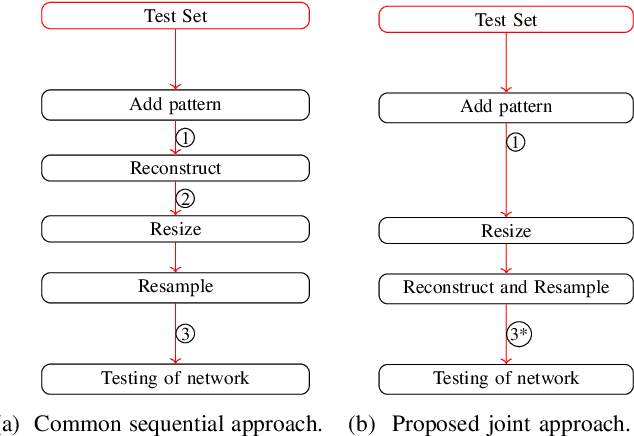
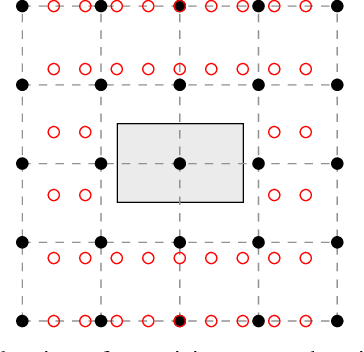
Neural networks became the standard technique for image classification throughout the last years. They are extracting image features from a large number of images in a training phase. In a following test phase, the network is applied to the problem it was trained for and its performance is measured. In this paper, we focus on image classification. The amount of visual data that is interpreted by neural networks grows with the increasing usage of neural networks. Mostly, the visual data is transmitted from the application side to a central server where the interpretation is conducted. If the transmission is disturbed, losses occur in the transmitted images. These losses have to be reconstructed using postprocessing. In this paper, we incorporate the widely applied bilinear and bicubic interpolation and the high-quality reconstruction Frequency-Selective Reconstruction (FSR) for the reconstruction of corrupted images. However, we propose to use Frequency-Selective Mesh-to-Grid Resampling (FSMR) for the joint reconstruction and resizing of corrupted images. The performance in terms of classification accuracy of EfficientNetB0, DenseNet121, DenseNet201, ResNet50 and ResNet152 is examined. Results show that the reconstruction with FSMR leads to the highest classification accuracy for most networks. Average improvements of up to 6.7 percentage points are possible for DenseNet121.
Frame Rate Up-Conversion Using Key Point Agnostic Frequency-Selective Mesh-to-Grid Resampling
Oct 19, 2022


High frame rates are desired in many fields of application. As in many cases the frame repetition rate of an already captured video has to be increased, frame rate up-conversion (FRUC) is of high interest. We conduct a motion compensated approach. From two neighboring frames, the motion is estimated and the neighboring pixels are shifted along the motion vector into the frame to be reconstructed. For displaying, these irregularly distributed mesh pixels have to be resampled onto regularly spaced grid positions. We use the model-based key point agnostic frequency-selective mesh-to-grid resampling (AFSMR) for this task and show that AFSMR works best for applications that contain irregular meshes with varying densities. AFSMR gains up to 3.2 dB in contrast to the already high performing frequency-selective mesh-to-grid resampling (FSMR). Additionally, AFSMR increases the run time by a factor of 11 relative to FSMR.
Synthesizing Annotated Image and Video Data Using a Rendering-Based Pipeline for Improved License Plate Recognition
Sep 28, 2022


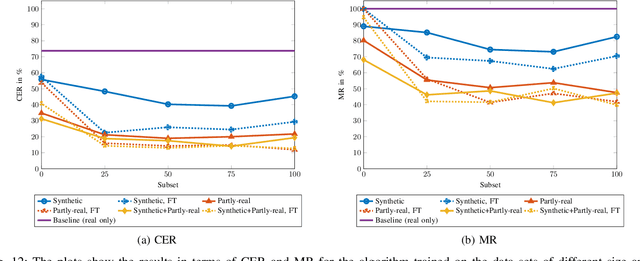
An insufficient number of training samples is a common problem in neural network applications. While data augmentation methods require at least a minimum number of samples, we propose a novel, rendering-based pipeline for synthesizing annotated data sets. Our method does not modify existing samples but synthesizes entirely new samples. The proposed rendering-based pipeline is capable of generating and annotating synthetic and partly-real image and video data in a fully automatic procedure. Moreover, the pipeline can aid the acquisition of real data. The proposed pipeline is based on a rendering process. This process generates synthetic data. Partly-real data bring the synthetic sequences closer to reality by incorporating real cameras during the acquisition process. The benefits of the proposed data generation pipeline, especially for machine learning scenarios with limited available training data, are demonstrated by an extensive experimental validation in the context of automatic license plate recognition. The experiments demonstrate a significant reduction of the character error rate and miss rate from 73.74% and 100% to 14.11% and 41.27% respectively, compared to an OCR algorithm trained on a real data set solely. These improvements are achieved by training the algorithm on synthesized data solely. When additionally incorporating real data, the error rates can be decreased further. Thereby, the character error rate and miss rate can be reduced to 11.90% and 39.88% respectively. All data used during the experiments as well as the proposed rendering-based pipeline for the automated data generation is made publicly available under (URL will be revealed upon publication).
Increasing the Accuracy of a Neural Network Using Frequency Selective Mesh-to-Grid Resampling
Sep 28, 2022

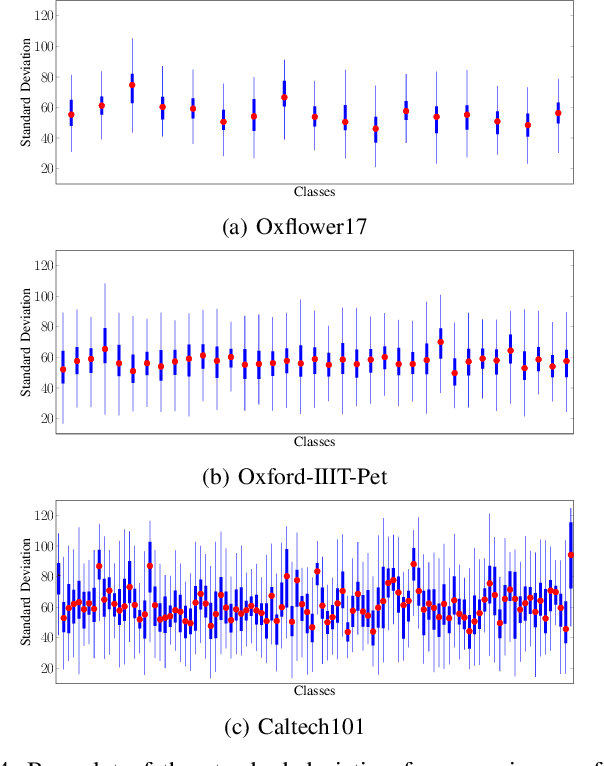
Neural networks are widely used for almost any task of recognizing image content. Even though much effort has been put into investigating efficient network architectures, optimizers, and training strategies, the influence of image interpolation on the performance of neural networks is not well studied. Furthermore, research has shown that neural networks are often sensitive to minor changes in the input image leading to drastic drops of their performance. Therefore, we propose the use of keypoint agnostic frequency selective mesh-to-grid resampling (FSMR) for the processing of input data for neural networks in this paper. This model-based interpolation method already showed that it is capable of outperforming common interpolation methods in terms of PSNR. Using an extensive experimental evaluation we show that depending on the network architecture and classification task the application of FSMR during training aids the learning process. Furthermore, we show that the usage of FSMR in the application phase is beneficial. The classification accuracy can be increased by up to 4.31 percentage points for ResNet50 and the Oxflower17 dataset.
3D Rendering Framework for Data Augmentation in Optical Character Recognition
Sep 27, 2022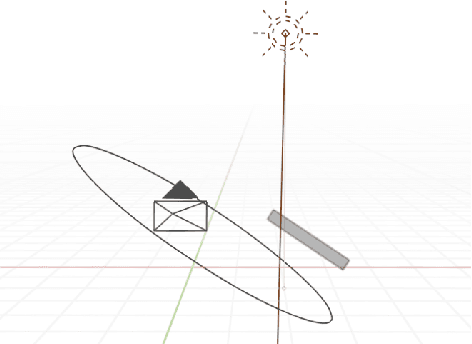
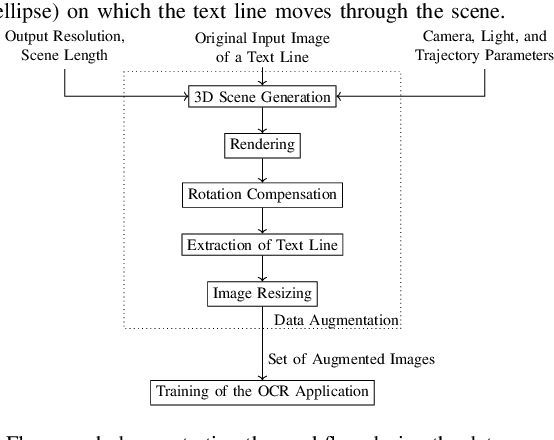

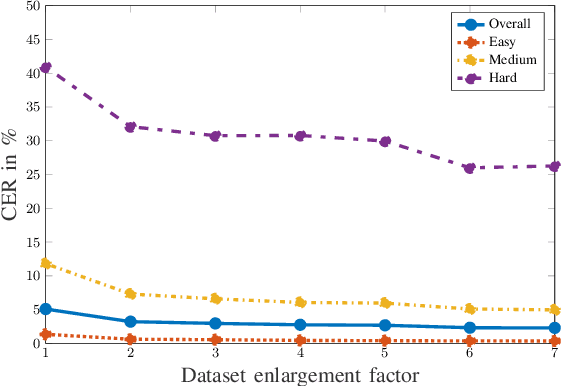
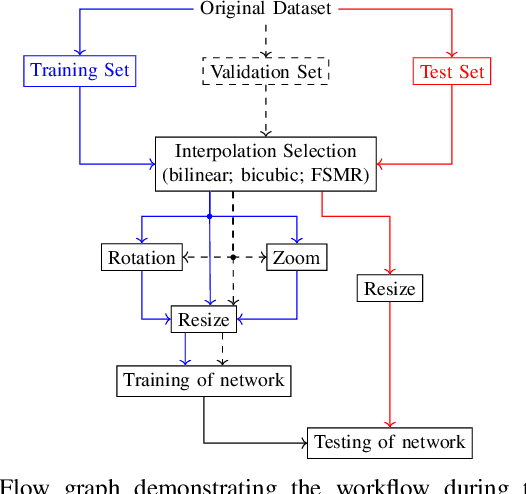
In this paper, we propose a data augmentation framework for Optical Character Recognition (OCR). The proposed framework is able to synthesize new viewing angles and illumination scenarios, effectively enriching any available OCR dataset. Its modular structure allows to be modified to match individual user requirements. The framework enables to comfortably scale the enlargement factor of the available dataset. Furthermore, the proposed method is not restricted to single frame OCR but can also be applied to video OCR. We demonstrate the performance of our framework by augmenting a 15% subset of the common Brno Mobile OCR dataset. Our proposed framework is capable of leveraging the performance of OCR applications especially for small datasets. Applying the proposed method, improvements of up to 2.79 percentage points in terms of Character Error Rate (CER), and up to 7.88 percentage points in terms of Word Error Rate (WER) are achieved on the subset. Especially the recognition of challenging text lines can be improved. The CER may be decreased by up to 14.92 percentage points and the WER by up to 18.19 percentage points for this class. Moreover, we are able to achieve smaller error rates when training on the 15% subset augmented with the proposed method than on the original non-augmented full dataset.
Quality Assurance of Weld Seams Using Laser Triangulation Imaging and Deep Neural Networks
Sep 27, 2022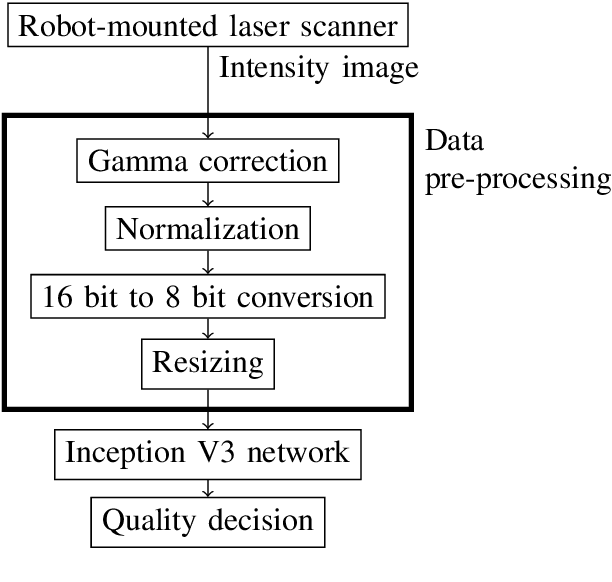


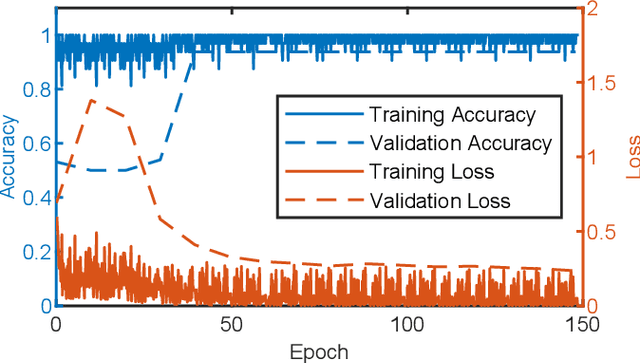
In this paper, a novel optical inspection system is presented that is directly suitable for Industry 4.0 and the implementation on IoT-devices controlling the manufacturing process. The proposed system is capable of distinguishing between erroneous and faultless weld seams, without explicitly defining measurement criteria . The developed system uses a deep neural network based classifier for the class prediction. A weld seam dataset was acquired and labelled by an expert committee. Thereby, the visual impression and assessment of the experts is learnt accurately. In the scope of this paper laser triangulation images are used. Due to their special characteristics, the images must be pre-processed to enable the use of a deep neural network. Furthermore, two different approaches are investigated to enable an inspection of differently sized weld seams. Both approaches yield very high classification accuracies of up to 96.88\%, which is competitive to current state of the art optical inspection systems. Moreover, the proposed system enables a higher flexibility and an increased robustness towards systematic errors and environmental conditions due to its ability to generalize. A further benefit of the proposed system is the fast decision process enabling the usage directly within the manufacturing line. Furthermore, standard hardware is used throughout the whole presented work, keeping the roll-out costs for the proposed system as low as possible.
Motion-Adapted Three-Dimensional Frequency Selective Extrapolation
Sep 15, 2022
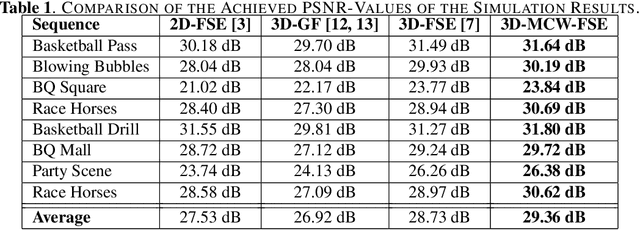
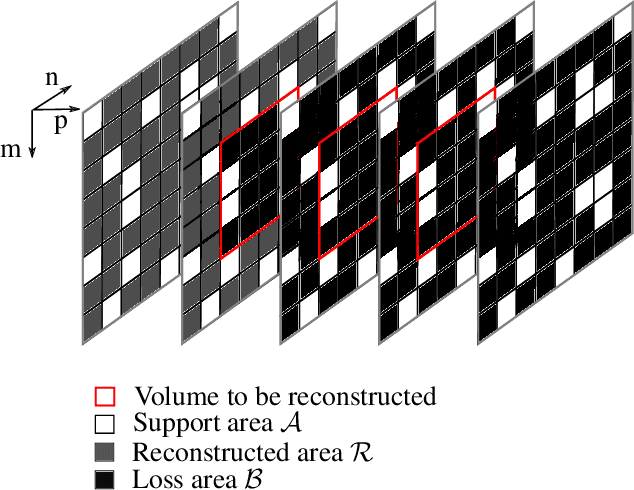
It has been shown, that high resolution images can be acquired using a low resolution sensor with non-regular sampling. Therefore, post-processing is necessary. In terms of video data, not only the spatial neighborhood can be used to assist the reconstruction, but also the temporal neighborhood. A popular and well performing algorithm for this kind of problem is the three-dimensional frequency selective extrapolation (3D-FSE) for which a motion adapted version is introduced in this paper. This proposed extension solves the problem of changing content within the area considered by the 3D-FSE, which is caused by motion within the sequence. Because of this motion, it may happen that regions are emphasized during the reconstruction that are not present in the original signal within the considered area. By that, false content is introduced into the extrapolated sequence, which affects the resulting image quality negatively. The novel extension, presented in the following, incorporates motion data of the sequence in order to adapt the algorithm accordingly, and compensates changing content, resulting in gains of up to 1.75 dB compared to the existing 3D-FSE.
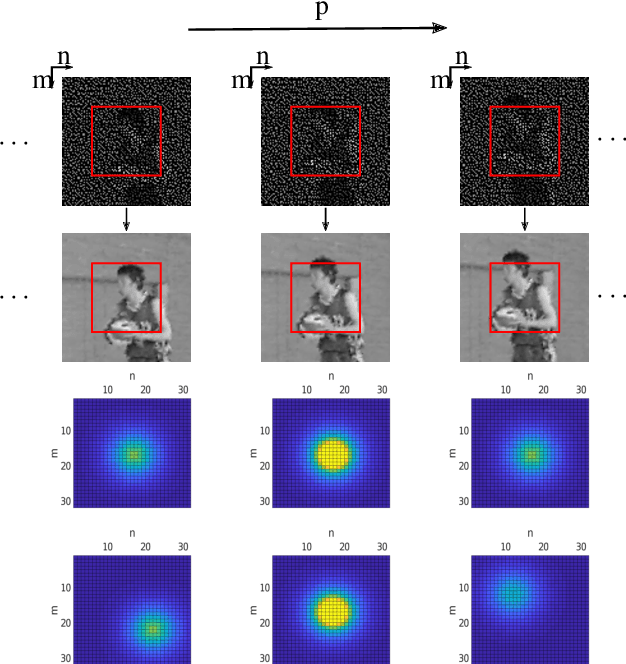
Forensic License Plate Recognition with Compression-Informed Transformers
Jul 29, 2022
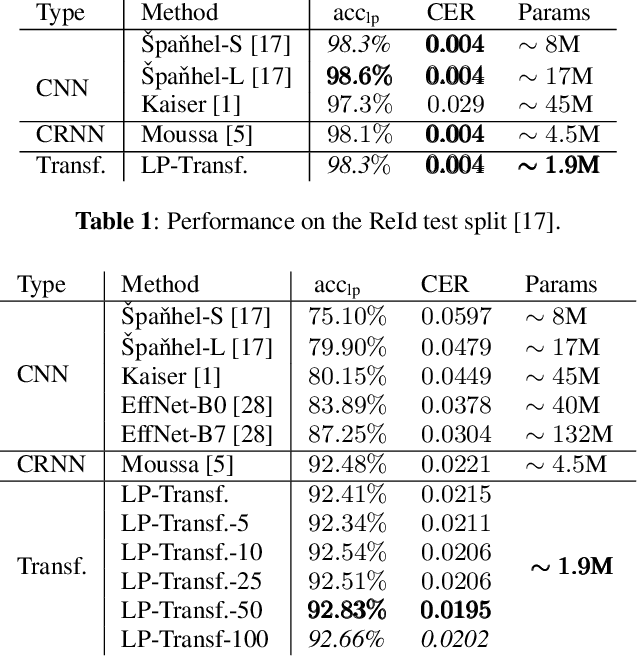

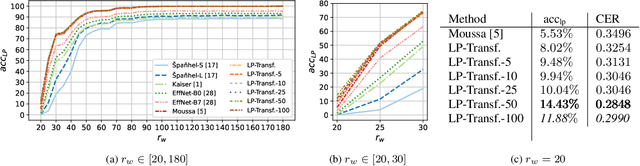
Forensic license plate recognition (FLPR) remains an open challenge in legal contexts such as criminal investigations, where unreadable license plates (LPs) need to be deciphered from highly compressed and/or low resolution footage, e.g., from surveillance cameras. In this work, we propose a side-informed Transformer architecture that embeds knowledge on the input compression level to improve recognition under strong compression. We show the effectiveness of Transformers for license plate recognition (LPR) on a low-quality real-world dataset. We also provide a synthetic dataset that includes strongly degraded, illegible LP images and analyze the impact of knowledge embedding on it. The network outperforms existing FLPR methods and standard state-of-the art image recognition models while requiring less parameters. For the severest degraded images, we can improve recognition by up to 8.9 percent points.
Frequency-Selective Geometry Upsampling of Point Clouds
May 03, 2022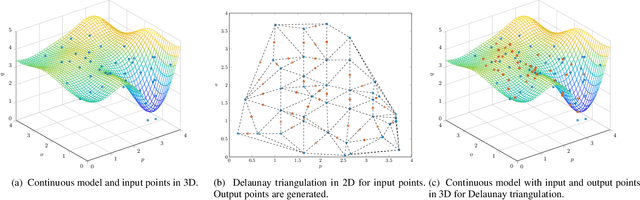

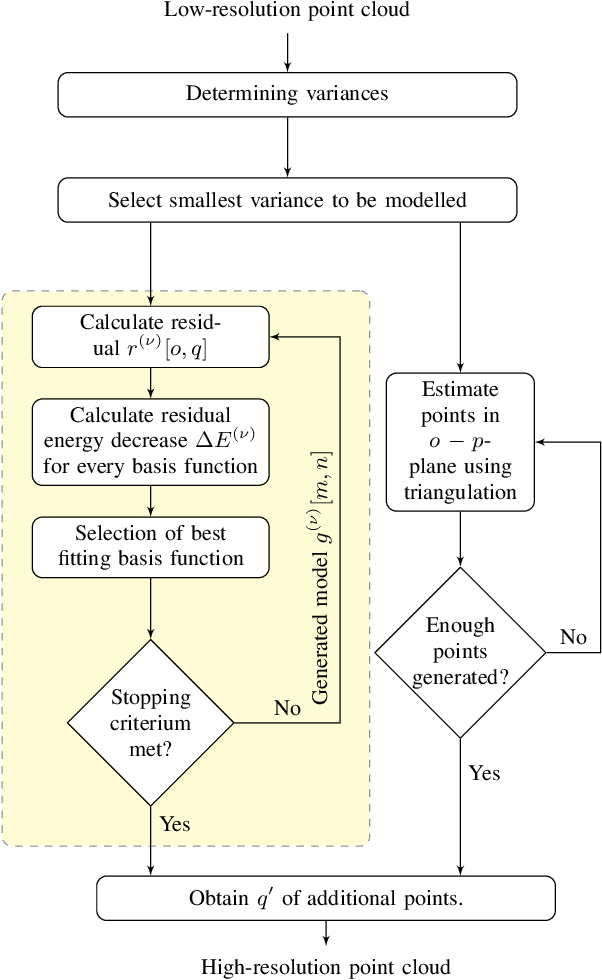
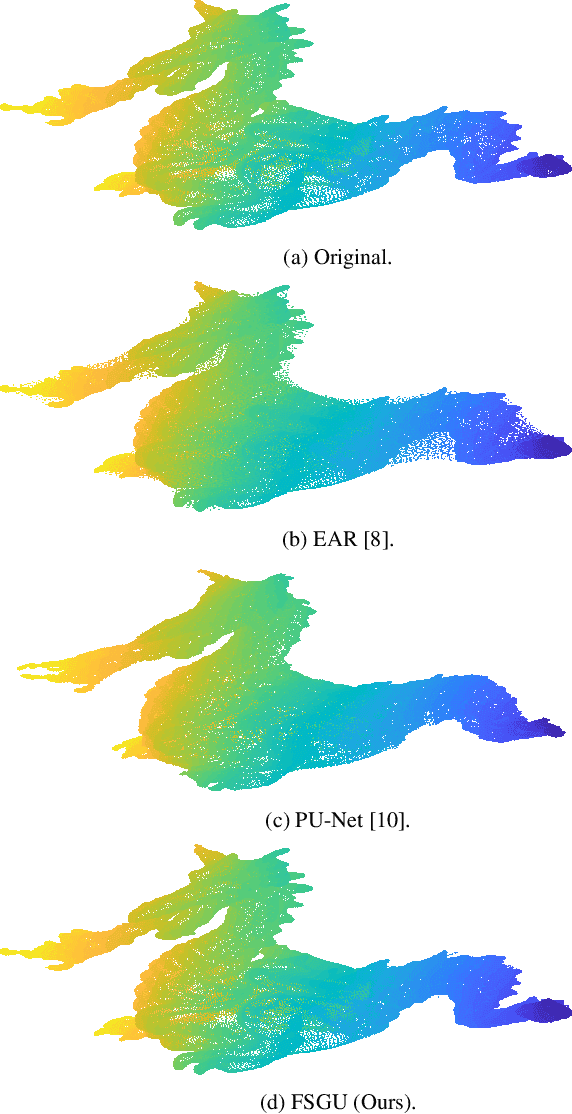
The demand for high-resolution point clouds has increased throughout the last years. However, capturing high-resolution point clouds is expensive and thus, frequently replaced by upsampling of low-resolution data. Most state-of-the-art methods are either restricted to a rastered grid, incorporate normal vectors, or are trained for a single use case. We propose to use the frequency selectivity principle, where a frequency model is estimated locally that approximates the surface of the point cloud. Then, additional points are inserted into the approximated surface. Our novel frequency-selective geometry upsampling shows superior results in terms of subjective as well as objective quality compared to state-of-the-art methods for scaling factors of 2 and 4. On average, our proposed method shows a 4.4 times smaller point-to-point error than the second best state-of-the-art PU-Net for a scale factor of 4.