 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandscape More Secure Than Portrait? Zooming Into the Directionality of Digital Images With Security Implications
Jun 21, 2024The orientation in which a source image is captured can affect the resulting security in downstream applications. One reason for this is that many state-of-the-art methods in media security assume that image statistics are similar in the horizontal and vertical directions, allowing them to reduce the number of features (or trainable weights) by merging coefficients. We show that this artificial symmetrization tends to suppress important properties of natural images and common processing operations, causing a loss of performance. We also observe the opposite problem, where unaddressed directionality causes learning-based methods to overfit to a single orientation. These are vulnerable to manipulation if an adversary chooses inputs with the less common orientation. This paper takes a comprehensive approach, identifies and systematizes causes of directionality at several stages of a typical acquisition pipeline, measures their effect, and demonstrates for three selected security applications (steganalysis, forensic source identification, and the detection of synthetic images) how the performance of state-of-the-art methods can be improved by properly accounting for directionality.
Off-By-One Implementation Error in J-UNIWARD
May 31, 2023



J-UNIWARD is a popular steganography method for hiding secret messages in JPEG cover images. As a content-adaptive method, J-UNIWARD aims to embed into textured image regions where changes are difficult to detect. To this end, J-UNIWARD first assigns to each DCT coefficient an embedding cost calculated based on the image's Wavelet residual, and then uses a coding method that minimizes the cost while embedding the desired payload. Changing one DCT coefficient affects a 23x23 window of Wavelet coefficients. To speed up the costmap computation, the original implementation pre-computes the Wavelet residual and then considers per changed DCT coefficient a 23x23 window of the Wavelet residual. However, the implementation accesses a window accidentally shifted by one pixel to the bottom right. In this report, we evaluate the effect of this off-by-one error on the resulting costmaps. Some image blocks are over-priced while other image blocks are under-priced, but the difference is relatively small. The off-by-one error seems to make little difference for learning-based steganalysis.
Benchmarking Probabilistic Deep Learning Methods for License Plate Recognition
Feb 02, 2023



Learning-based algorithms for automated license plate recognition implicitly assume that the training and test data are well aligned. However, this may not be the case under extreme environmental conditions, or in forensic applications where the system cannot be trained for a specific acquisition device. Predictions on such out-of-distribution images have an increased chance of failing. But this failure case is oftentimes hard to recognize for a human operator or an automated system. Hence, in this work we propose to model the prediction uncertainty for license plate recognition explicitly. Such an uncertainty measure allows to detect false predictions, indicating an analyst when not to trust the result of the automated license plate recognition. In this paper, we compare three methods for uncertainty quantification on two architectures. The experiments on synthetic noisy or blurred low-resolution images show that the predictive uncertainty reliably finds wrong predictions. We also show that a multi-task combination of classification and super-resolution improves the recognition performance by 109\% and the detection of wrong predictions by 29 %.
Compliance Challenges in Forensic Image Analysis Under the Artificial Intelligence Act
Mar 01, 2022In many applications of forensic image analysis, state-of-the-art results are nowadays achieved with machine learning methods. However, concerns about their reliability and opaqueness raise the question whether such methods can be used in criminal investigations. So far, this question of legal compliance has hardly been discussed, also because legal regulations for machine learning methods were not defined explicitly. To this end, the European Commission recently proposed the artificial intelligence (AI) act, a regulatory framework for the trustworthy use of AI. Under the draft AI act, high-risk AI systems for use in law enforcement are permitted but subject to compliance with mandatory requirements. In this paper, we review why the use of machine learning in forensic image analysis is classified as high-risk. We then summarize the mandatory requirements for high-risk AI systems and discuss these requirements in light of two forensic applications, license plate recognition and deep fake detection. The goal of this paper is to raise awareness of the upcoming legal requirements and to point out avenues for future research.
Toward Reliable Models for Authenticating Multimedia Content: Detecting Resampling Artifacts With Bayesian Neural Networks
Jul 28, 2020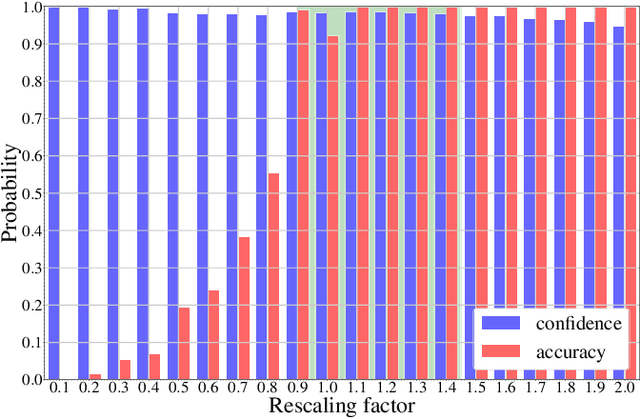
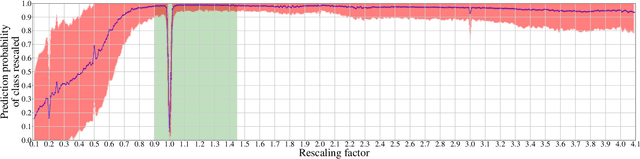
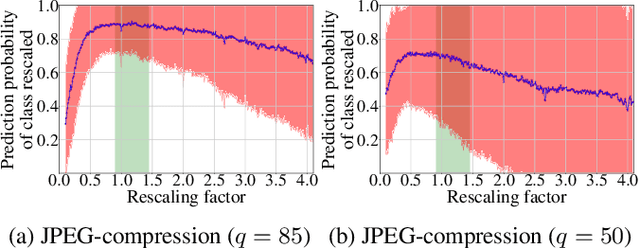
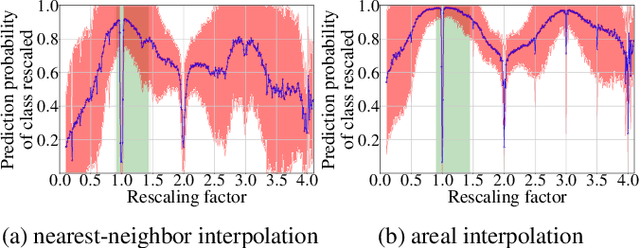
In multimedia forensics, learning-based methods provide state-of-the-art performance in determining origin and authenticity of images and videos. However, most existing methods are challenged by out-of-distribution data, i.e., with characteristics that are not covered in the training set. This makes it difficult to know when to trust a model, particularly for practitioners with limited technical background. In this work, we make a first step toward redesigning forensic algorithms with a strong focus on reliability. To this end, we propose to use Bayesian neural networks (BNN), which combine the power of deep neural networks with the rigorous probabilistic formulation of a Bayesian framework. Instead of providing a point estimate like standard neural networks, BNNs provide distributions that express both the estimate and also an uncertainty range. We demonstrate the usefulness of this framework on a classical forensic task: resampling detection. The BNN yields state-of-the-art detection performance, plus excellent capabilities for detecting out-of-distribution samples. This is demonstrated for three pathologic issues in resampling detection, namely unseen resampling factors, unseen JPEG compression, and unseen resampling algorithms. We hope that this proposal spurs further research toward reliability in multimedia forensics.