 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Taxonomy of Miscompressions: Preparing Image Forensics for Neural Compression
Sep 09, 2024Neural compression has the potential to revolutionize lossy image compression. Based on generative models, recent schemes achieve unprecedented compression rates at high perceptual quality but compromise semantic fidelity. Details of decompressed images may appear optically flawless but semantically different from the originals, making compression errors difficult or impossible to detect. We explore the problem space and propose a provisional taxonomy of miscompressions. It defines three types of 'what happens' and has a binary 'high impact' flag indicating miscompressions that alter symbols. We discuss how the taxonomy can facilitate risk communication and research into mitigations.
Landscape More Secure Than Portrait? Zooming Into the Directionality of Digital Images With Security Implications
Jun 21, 2024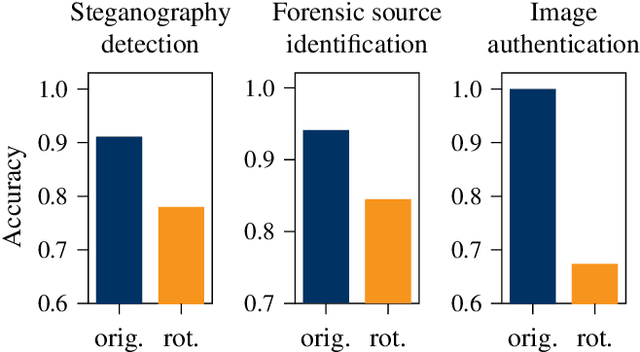
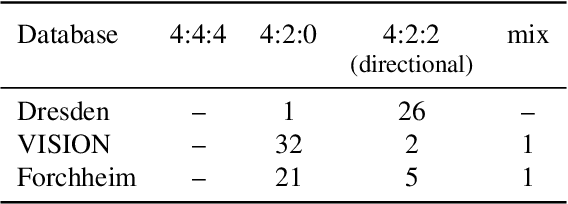

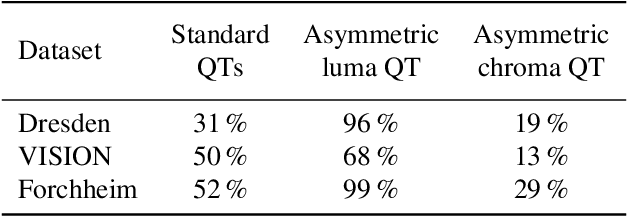
The orientation in which a source image is captured can affect the resulting security in downstream applications. One reason for this is that many state-of-the-art methods in media security assume that image statistics are similar in the horizontal and vertical directions, allowing them to reduce the number of features (or trainable weights) by merging coefficients. We show that this artificial symmetrization tends to suppress important properties of natural images and common processing operations, causing a loss of performance. We also observe the opposite problem, where unaddressed directionality causes learning-based methods to overfit to a single orientation. These are vulnerable to manipulation if an adversary chooses inputs with the less common orientation. This paper takes a comprehensive approach, identifies and systematizes causes of directionality at several stages of a typical acquisition pipeline, measures their effect, and demonstrates for three selected security applications (steganalysis, forensic source identification, and the detection of synthetic images) how the performance of state-of-the-art methods can be improved by properly accounting for directionality.
iNNformant: Boundary Samples as Telltale Watermarks
Jun 14, 2021


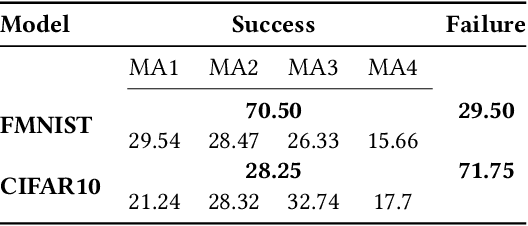
Boundary samples are special inputs to artificial neural networks crafted to identify the execution environment used for inference by the resulting output label. The paper presents and evaluates algorithms to generate transparent boundary samples. Transparency refers to a small perceptual distortion of the host signal (i.e., a natural input sample). For two established image classifiers, ResNet on FMNIST and CIFAR10, we show that it is possible to generate sets of boundary samples which can identify any of four tested microarchitectures. These sets can be built to not contain any sample with a worse peak signal-to-noise ratio than 70dB. We analyze the relationship between search complexity and resulting transparency.
More Real than Real: A Study on Human Visual Perception of Synthetic Faces
Jun 14, 2021



Deep fakes became extremely popular in the last years, also thanks to their increasing realism. Therefore, there is the need to measures human's ability to distinguish between real and synthetic face images when confronted with cutting-edge creation technologies. We describe the design and results of a perceptual experiment we have conducted, where a wide and diverse group of volunteers has been exposed to synthetic face images produced by state-of-the-art Generative Adversarial Networks (namely, PG-GAN, StyleGAN, StyleGAN2). The experiment outcomes reveal how strongly we should call into question our human ability to discriminate real faces from synthetic ones generated through modern AI.
Forensicability of Deep Neural Network Inference Pipelines
Feb 18, 2021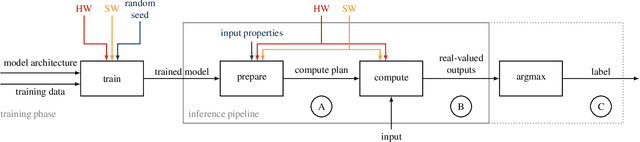
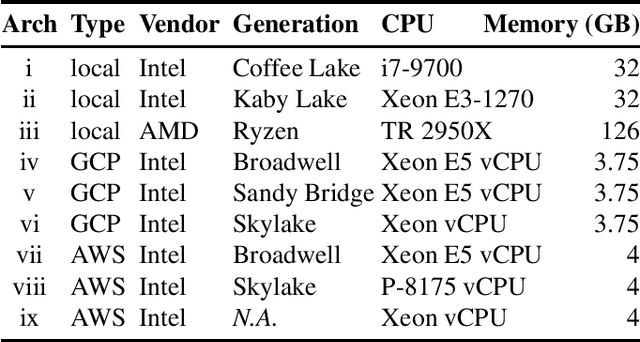
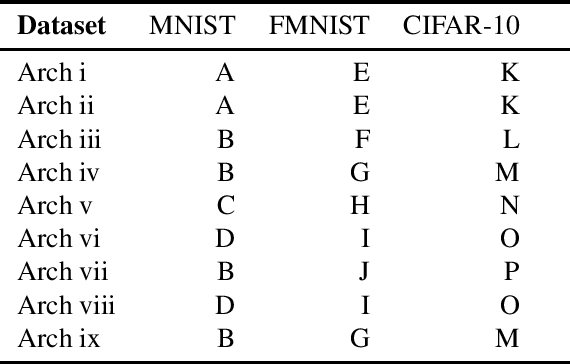
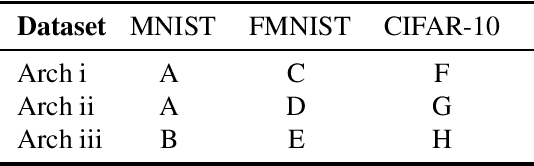
We propose methods to infer properties of the execution environment of machine learning pipelines by tracing characteristic numerical deviations in observable outputs. Results from a series of proof-of-concept experiments obtained on local and cloud-hosted machines give rise to possible forensic applications, such as the identification of the hardware platform used to produce deep neural network predictions. Finally, we introduce boundary samples that amplify the numerical deviations in order to distinguish machines by their predicted label only.