 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU-accelerated SIFT-aided source identification of stabilized videos
Jul 29, 2022


Video stabilization is an in-camera processing commonly applied by modern acquisition devices. While significantly improving the visual quality of the resulting videos, it has been shown that such operation typically hinders the forensic analysis of video signals. In fact, the correct identification of the acquisition source usually based on Photo Response non-Uniformity (PRNU) is subject to the estimation of the transformation applied to each frame in the stabilization phase. A number of techniques have been proposed for dealing with this problem, which however typically suffer from a high computational burden due to the grid search in the space of inversion parameters. Our work attempts to alleviate these shortcomings by exploiting the parallelization capabilities of Graphics Processing Units (GPUs), typically used for deep learning applications, in the framework of stabilised frames inversion. Moreover, we propose to exploit SIFT features {to estimate the camera momentum and} %to identify less stabilized temporal segments, thus enabling a more accurate identification analysis, and to efficiently initialize the frame-wise parameter search of consecutive frames. Experiments on a consolidated benchmark dataset confirm the effectiveness of the proposed approach in reducing the required computational time and improving the source identification accuracy. {The code is available at \url{https://github.com/AMontiB/GPU-PRNU-SIFT}}.
More Real than Real: A Study on Human Visual Perception of Synthetic Faces
Jun 14, 2021



Deep fakes became extremely popular in the last years, also thanks to their increasing realism. Therefore, there is the need to measures human's ability to distinguish between real and synthetic face images when confronted with cutting-edge creation technologies. We describe the design and results of a perceptual experiment we have conducted, where a wide and diverse group of volunteers has been exposed to synthetic face images produced by state-of-the-art Generative Adversarial Networks (namely, PG-GAN, StyleGAN, StyleGAN2). The experiment outcomes reveal how strongly we should call into question our human ability to discriminate real faces from synthetic ones generated through modern AI.
Dynamic texture analysis for detecting fake faces in video sequences
Jul 30, 2020
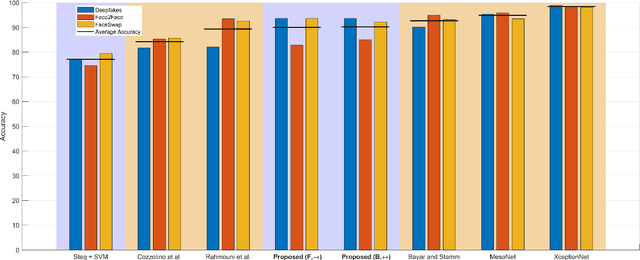
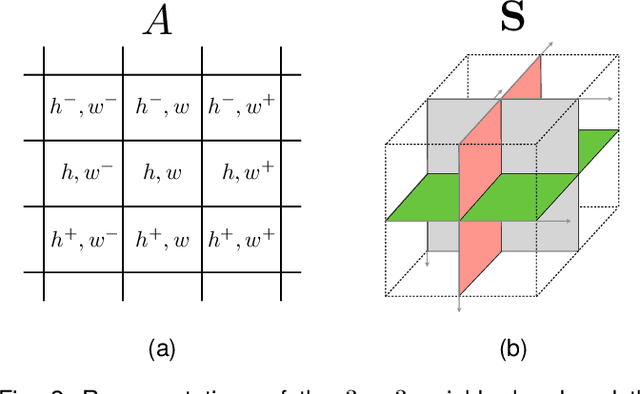
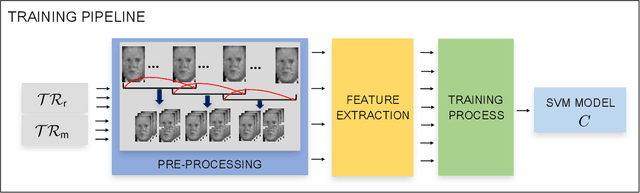
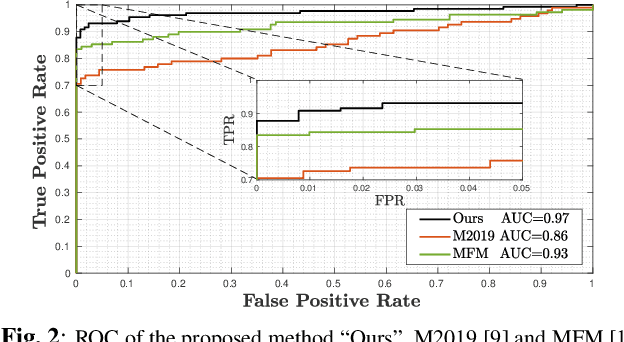
The creation of manipulated multimedia content involving human characters has reached in the last years unprecedented realism, calling for automated techniques to expose synthetically generated faces in images and videos. This work explores the analysis of spatio-temporal texture dynamics of the video signal, with the goal of characterizing and distinguishing real and fake sequences. We propose to build a binary decision on the joint analysis of multiple temporal segments and, in contrast to previous approaches, to exploit the textural dynamics of both the spatial and temporal dimensions. This is achieved through the use of Local Derivative Patterns on Three Orthogonal Planes (LDP-TOP), a compact feature representation known to be an important asset for the detection of face spoofing attacks. Experimental analyses on state-of-the-art datasets of manipulated videos show the discriminative power of such descriptors in separating real and fake sequences, and also identifying the creation method used. Linear Support Vector Machines (SVMs) are used which, despite the lower complexity, yield comparable performance to previously proposed deep models for fake content detection.