 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic texture analysis for detecting fake faces in video sequences
Paper and Code
Jul 30, 2020
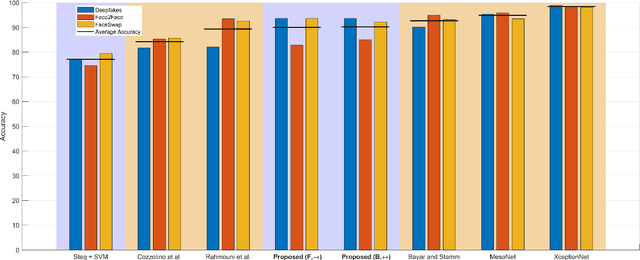
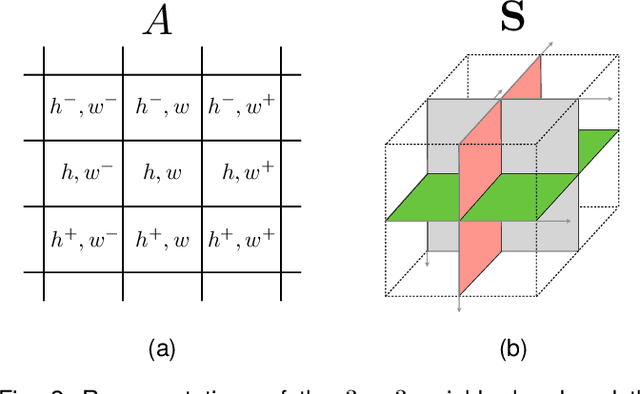
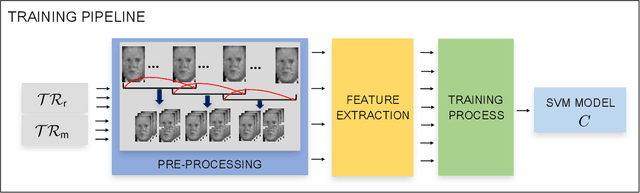
The creation of manipulated multimedia content involving human characters has reached in the last years unprecedented realism, calling for automated techniques to expose synthetically generated faces in images and videos. This work explores the analysis of spatio-temporal texture dynamics of the video signal, with the goal of characterizing and distinguishing real and fake sequences. We propose to build a binary decision on the joint analysis of multiple temporal segments and, in contrast to previous approaches, to exploit the textural dynamics of both the spatial and temporal dimensions. This is achieved through the use of Local Derivative Patterns on Three Orthogonal Planes (LDP-TOP), a compact feature representation known to be an important asset for the detection of face spoofing attacks. Experimental analyses on state-of-the-art datasets of manipulated videos show the discriminative power of such descriptors in separating real and fake sequences, and also identifying the creation method used. Linear Support Vector Machines (SVMs) are used which, despite the lower complexity, yield comparable performance to previously proposed deep models for fake content detection.