 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal and Volumetric Denoising via Quantile Sparse Image (QuaSI) Prior in Optical Coherence Tomography and Beyond
Jul 05, 2018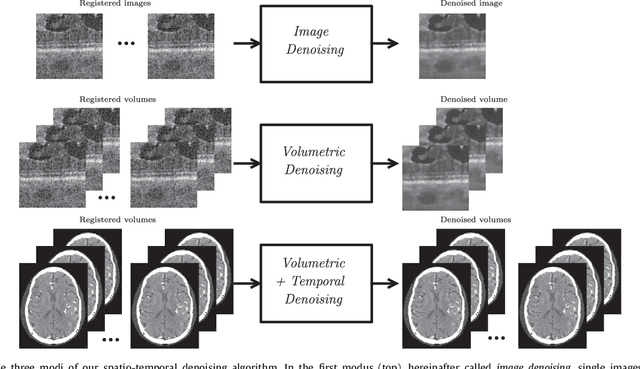


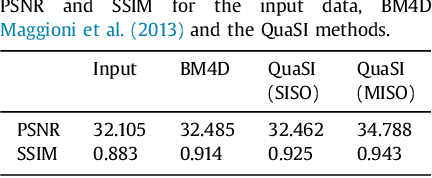
This paper introduces an universal and structure-preserving regularization term, called quantile sparse image (QuaSI) prior. The prior is suitable for denoising images from various medical imaging modalities. We demonstrate its effectiveness on volumetric optical coherence tomography (OCT) and computed tomography (CT) data, which show different noise and image characteristics. OCT offers high-resolution scans of the human retina but is inherently impaired by speckle noise. CT on the other hand has a lower resolution and shows high-frequency noise. For the purpose of denoising, we propose a variational framework based on the QuaSI prior and a Huber data fidelity model that can handle 3-D and 3-D+t data. Efficient optimization is facilitated through the use of an alternating direction method of multipliers (ADMM) scheme and the linearization of the quantile filter. Experiments on multiple datasets emphasize the excellent performance of the proposed method.
QuaSI: Quantile Sparse Image Prior for Spatio-Temporal Denoising of Retinal OCT Data
Mar 08, 2017
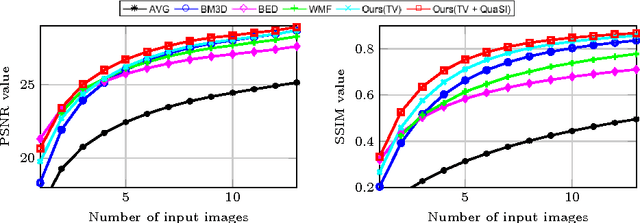

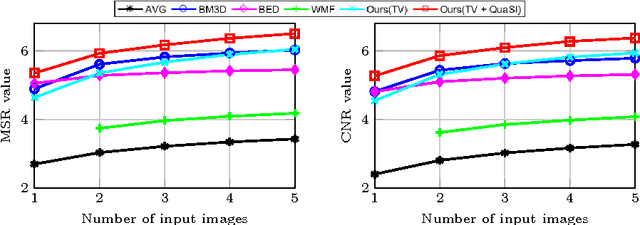
Optical coherence tomography (OCT) enables high-resolution and non-invasive 3D imaging of the human retina but is inherently impaired by speckle noise. This paper introduces a spatio-temporal denoising algorithm for OCT data on a B-scan level using a novel quantile sparse image (QuaSI) prior. To remove speckle noise while preserving image structures of diagnostic relevance, we implement our QuaSI prior via median filter regularization coupled with a Huber data fidelity model in a variational approach. For efficient energy minimization, we develop an alternating direction method of multipliers (ADMM) scheme using a linearization of median filtering. Our spatio-temporal method can handle both, denoising of single B-scans and temporally consecutive B-scans, to gain volumetric OCT data with enhanced signal-to-noise ratio. Our algorithm based on 4 B-scans only achieved comparable performance to averaging 13 B-scans and outperformed other current denoising methods.
Mixed one-bit compressive sensing with applications to overexposure correction for CT reconstruction
Jan 03, 2017

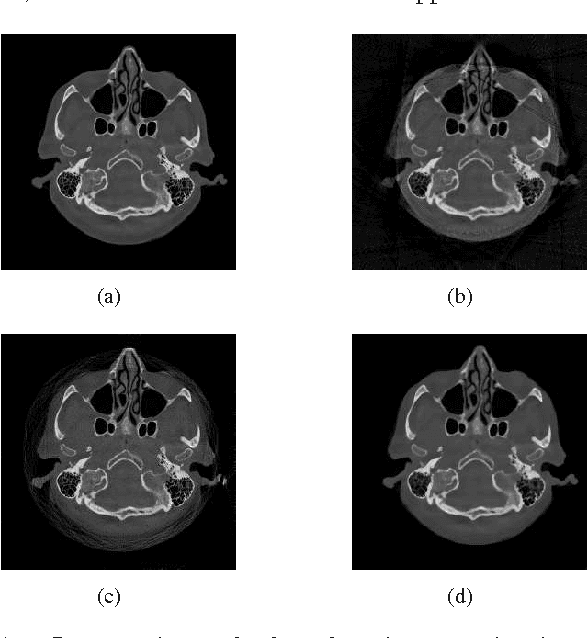

When a measurement falls outside the quantization or measurable range, it becomes saturated and cannot be used in classical reconstruction methods. For example, in C-arm angiography systems, which provide projection radiography, fluoroscopy, digital subtraction angiography, and are widely used for medical diagnoses and interventions, the limited dynamic range of C-arm flat detectors leads to overexposure in some projections during an acquisition, such as imaging relatively thin body parts (e.g., the knee). Aiming at overexposure correction for computed tomography (CT) reconstruction, we in this paper propose a mixed one-bit compressive sensing (M1bit-CS) to acquire information from both regular and saturated measurements. This method is inspired by the recent progress on one-bit compressive sensing, which deals with only sign observations. Its successful applications imply that information carried by saturated measurements is useful to improve recovery quality. For the proposed M1bit-CS model, alternating direction methods of multipliers is developed and an iterative saturation detection scheme is established. Then we evaluate M1bit-CS on one-dimensional signal recovery tasks. In some experiments, the performance of the proposed algorithms on mixed measurements is almost the same as recovery on unsaturated ones with the same amount of measurements. Finally, we apply the proposed method to overexposure correction for CT reconstruction on a phantom and a simulated clinical image. The results are promising, as the typical streaking artifacts and capping artifacts introduced by saturated projection data are effectively reduced, yielding significant error reduction compared with existing algorithms based on extrapolation.
A Self-Taught Artificial Agent for Multi-Physics Computational Model Personalization
May 01, 2016
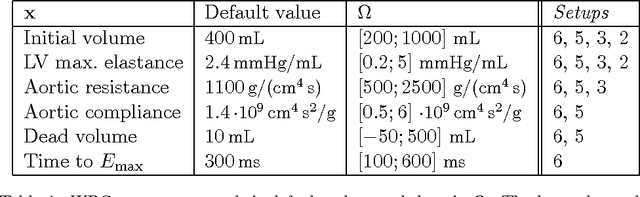
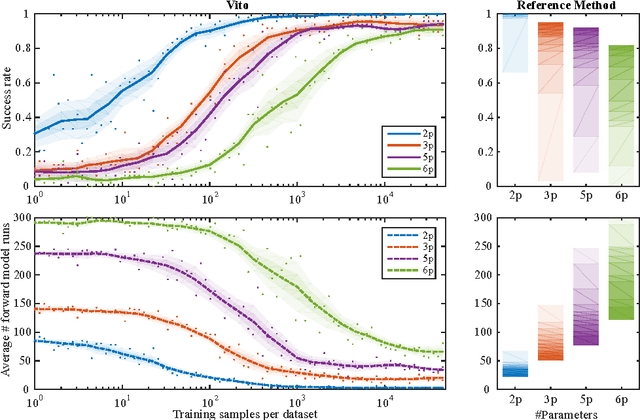

Personalization is the process of fitting a model to patient data, a critical step towards application of multi-physics computational models in clinical practice. Designing robust personalization algorithms is often a tedious, time-consuming, model- and data-specific process. We propose to use artificial intelligence concepts to learn this task, inspired by how human experts manually perform it. The problem is reformulated in terms of reinforcement learning. In an off-line phase, Vito, our self-taught artificial agent, learns a representative decision process model through exploration of the computational model: it learns how the model behaves under change of parameters. The agent then automatically learns an optimal strategy for on-line personalization. The algorithm is model-independent; applying it to a new model requires only adjusting few hyper-parameters of the agent and defining the observations to match. The full knowledge of the model itself is not required. Vito was tested in a synthetic scenario, showing that it could learn how to optimize cost functions generically. Then Vito was applied to the inverse problem of cardiac electrophysiology and the personalization of a whole-body circulation model. The obtained results suggested that Vito could achieve equivalent, if not better goodness of fit than standard methods, while being more robust (up to 11% higher success rates) and with faster (up to seven times) convergence rate. Our artificial intelligence approach could thus make personalization algorithms generalizable and self-adaptable to any patient and any model.
Super-Resolved Retinal Image Mosaicing
Feb 10, 2016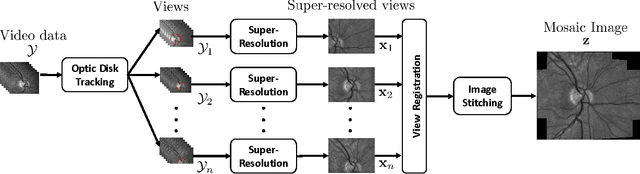
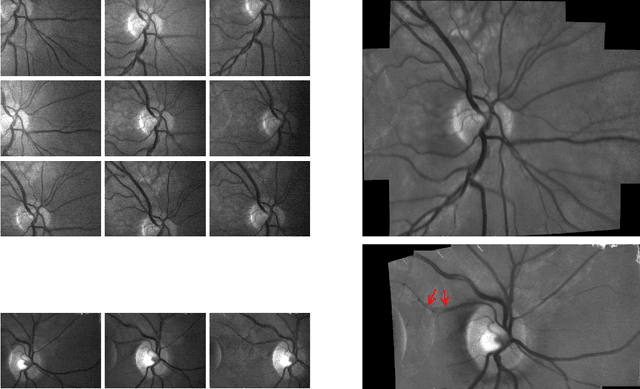

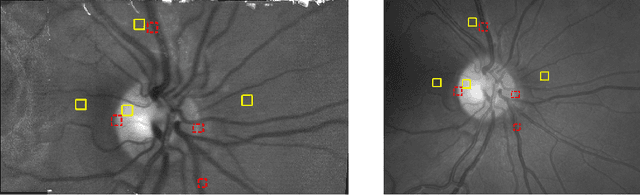
The acquisition of high-resolution retinal fundus images with a large field of view (FOV) is challenging due to technological, physiological and economic reasons. This paper proposes a fully automatic framework to reconstruct retinal images of high spatial resolution and increased FOV from multiple low-resolution images captured with non-mydriatic, mobile and video-capable but low-cost cameras. Within the scope of one examination, we scan different regions on the retina by exploiting eye motion conducted by a patient guidance. Appropriate views for our mosaicing method are selected based on optic disk tracking to trace eye movements. For each view, one super-resolved image is reconstructed by fusion of multiple video frames. Finally, all super-resolved views are registered to a common reference using a novel polynomial registration scheme and combined by means of image mosaicing. We evaluated our framework for a mobile and low-cost video fundus camera. In our experiments, we reconstructed retinal images of up to 30{\deg} FOV from 10 complementary views of 15{\deg} FOV. An evaluation of the mosaics by human experts as well as a quantitative comparison to conventional color fundus images encourage the clinical usability of our framework.
3-D/2-D Registration of Cardiac Structures by 3-D Contrast Agent Distribution Estimation
Jan 22, 2016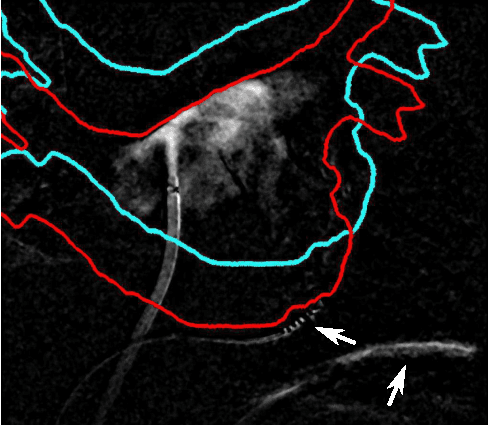
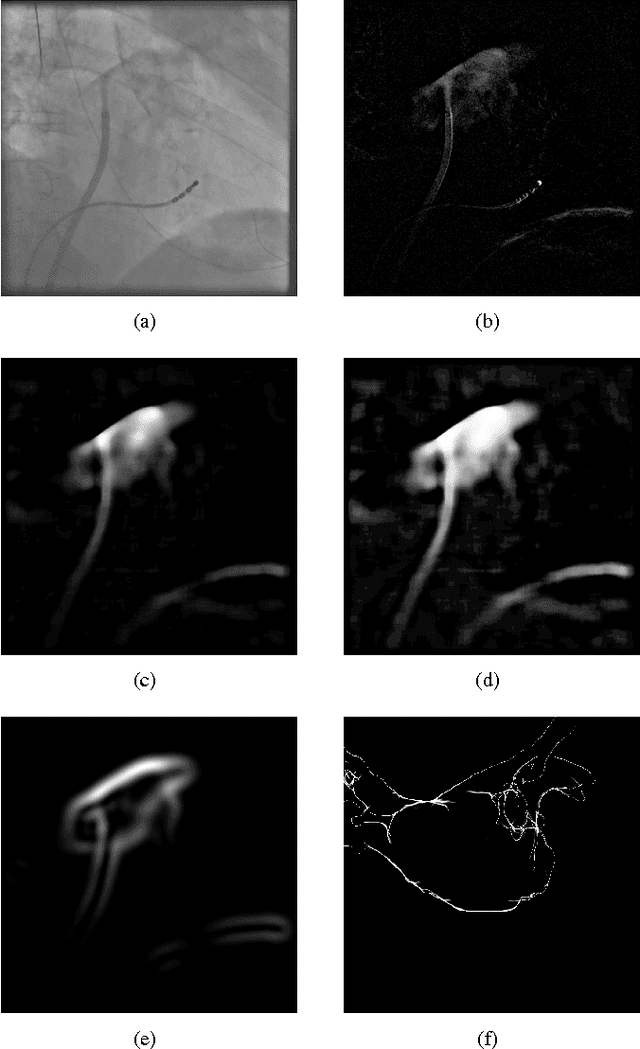
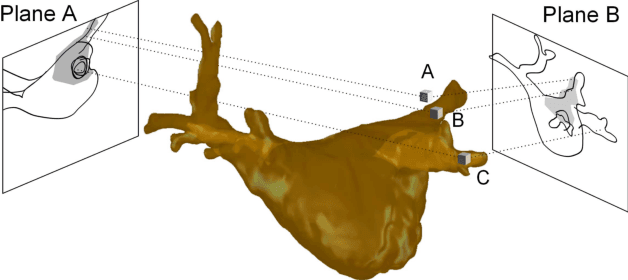
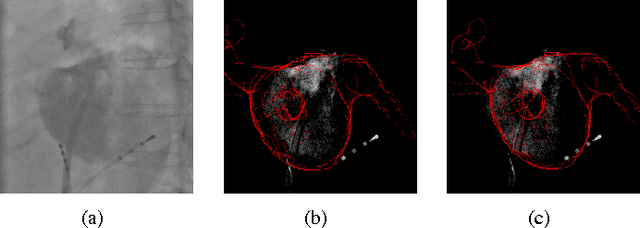
For augmented fluoroscopy during cardiac catheter ablation procedures, a preoperatively acquired 3-D model of the left atrium of the patient can be registered to X-ray images. Therefore the 3D-model is matched with the contrast agent based appearance of the left atrium. Commonly, only small amounts of contrast agent (CA) are used to locate the left atrium. This is why we focus on robust registration methods that work also if the structure of interest is only partially contrasted. In particular, we propose two similarity measures for CA-based registration: The first similarity measure, explicit apparent edges, focuses on edges of the patient anatomy made visible by contrast agent and can be computed quickly on the GPU. The second novel similarity measure computes a contrast agent distribution estimate (CADE) inside the 3-D model and rates its consistency with the CA seen in biplane fluoroscopic images. As the CADE computation involves a reconstruction of CA in 3-D using the CA within the fluoroscopic images, it is slower. Using a combination of both methods, our evaluation on 11 well-contrasted clinical datasets yielded an error of 7.9+/-6.3 mm over all frames. For 10 datasets with little CA, we obtained an error of 8.8+/-6.7 mm. Our new methods outperform a registration based on the projected shadow significantly (p<0.05).