 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating multiscale topology in digital pathology with pyramidal graph convolutional networks
Mar 22, 2024Graph convolutional networks (GCNs) have emerged as a powerful alternative to multiple instance learning with convolutional neural networks in digital pathology, offering superior handling of structural information across various spatial ranges - a crucial aspect of learning from gigapixel H&E-stained whole slide images (WSI). However, graph message-passing algorithms often suffer from oversmoothing when aggregating a large neighborhood. Hence, effective modeling of multi-range interactions relies on the careful construction of the graph. Our proposed multi-scale GCN (MS-GCN) tackles this issue by leveraging information across multiple magnification levels in WSIs. MS-GCN enables the simultaneous modeling of long-range structural dependencies at lower magnifications and high-resolution cellular details at higher magnifications, akin to analysis pipelines usually conducted by pathologists. The architecture's unique configuration allows for the concurrent modeling of structural patterns at lower magnifications and detailed cellular features at higher ones, while also quantifying the contribution of each magnification level to the prediction. Through testing on different datasets, MS-GCN demonstrates superior performance over existing single-magnification GCN methods. The enhancement in performance and interpretability afforded by our method holds promise for advancing computational pathology models, especially in tasks requiring extensive spatial context.
A comparative study between vision transformers and CNNs in digital pathology
Jun 01, 2022
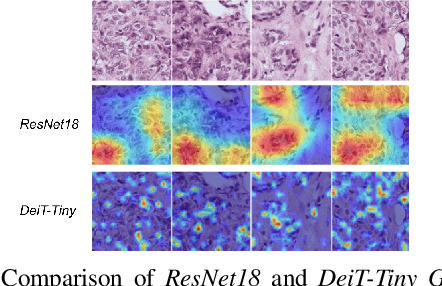


Recently, vision transformers were shown to be capable of outperforming convolutional neural networks when pretrained on sufficient amounts of data. In comparison to convolutional neural networks, vision transformers have a weaker inductive bias and therefore allow a more flexible feature detection. Due to their promising feature detection, this work explores vision transformers for tumor detection in digital pathology whole slide images in four tissue types, and for tissue type identification. We compared the patch-wise classification performance of the vision transformer DeiT-Tiny to the state-of-the-art convolutional neural network ResNet18. Due to the sparse availability of annotated whole slide images, we further compared both models pretrained on large amounts of unlabeled whole-slide images using state-of-the-art self-supervised approaches. The results show that the vision transformer performed slightly better than the ResNet18 for three of four tissue types for tumor detection while the ResNet18 performed slightly better for the remaining tasks. The aggregated predictions of both models on slide level were correlated, indicating that the models captured similar imaging features. All together, the vision transformer models performed on par with the ResNet18 while requiring more effort to train. In order to surpass the performance of convolutional neural networks, vision transformers might require more challenging tasks to benefit from their weak inductive bias.