 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGONITE: Iterative Retrieval on Induced Databases and Verbalized RDF for Conversational QA over KGs with RAG
Dec 24, 2024



Conversational question answering (ConvQA) is a convenient means of searching over RDF knowledge graphs (KGs), where a prevalent approach is to translate natural language questions to SPARQL queries. However, SPARQL has certain shortcomings: (i) it is brittle for complex intents and conversational questions, and (ii) it is not suitable for more abstract needs. Instead, we propose a novel two-pronged system where we fuse: (i) SQL-query results over a database automatically derived from the KG, and (ii) text-search results over verbalizations of KG facts. Our pipeline supports iterative retrieval: when the results of any branch are found to be unsatisfactory, the system can automatically opt for further rounds. We put everything together in a retrieval augmented generation (RAG) setup, where an LLM generates a coherent response from accumulated search results. We demonstrate the superiority of our proposed system over several baselines on a knowledge graph of BMW automobiles.
Data Processing for the OpenGPT-X Model Family
Oct 11, 2024



This paper presents a comprehensive overview of the data preparation pipeline developed for the OpenGPT-X project, a large-scale initiative aimed at creating open and high-performance multilingual large language models (LLMs). The project goal is to deliver models that cover all major European languages, with a particular focus on real-world applications within the European Union. We explain all data processing steps, starting with the data selection and requirement definition to the preparation of the final datasets for model training. We distinguish between curated data and web data, as each of these categories is handled by distinct pipelines, with curated data undergoing minimal filtering and web data requiring extensive filtering and deduplication. This distinction guided the development of specialized algorithmic solutions for both pipelines. In addition to describing the processing methodologies, we provide an in-depth analysis of the datasets, increasing transparency and alignment with European data regulations. Finally, we share key insights and challenges faced during the project, offering recommendations for future endeavors in large-scale multilingual data preparation for LLMs.
Bridging the Simulated-to-Real Gap: Benchmarking Super-Resolution on Real Data
Sep 17, 2018
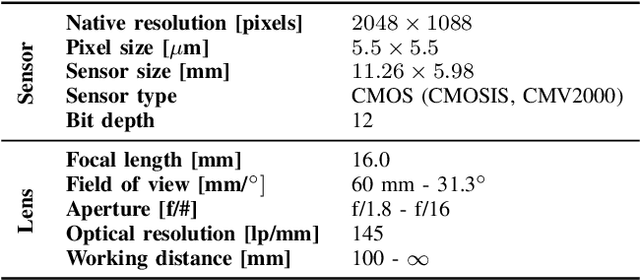
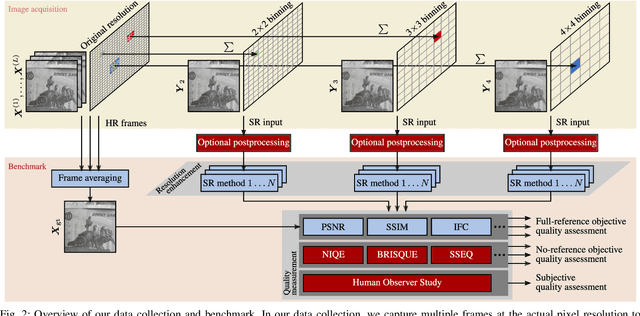

Capturing ground truth data to benchmark super-resolution (SR) is challenging. Therefore, current quantitative studies are mainly evaluated on simulated data artificially sampled from ground truth images. We argue that such evaluations overestimate the actual performance of SR methods compared to their behavior on real images. To bridge this simulated-to-real gap, we introduce the Super-Resolution Erlangen (SupER) database, the first comprehensive laboratory SR database of all-real acquisitions with pixel-wise ground truth. It consists of more than 80k images of 14 scenes combining different facets: CMOS sensor noise, real sampling at four resolution levels, nine scene motion types, two photometric conditions, and lossy video coding at five levels. As such, the database exceeds existing benchmarks by an order of magnitude in quality and quantity. This paper also benchmarks 19 popular single-image and multi-frame algorithms on our data. The benchmark comprises a quantitative study by exploiting ground truth data and qualitative evaluations in a large-scale observer study. We also rigorously investigate agreements between both evaluations from a statistical perspective. One interesting result is that top-performing methods on simulated data may be surpassed by others on real data. Our insights can spur further algorithm development, and the publicy available dataset can foster future evaluations.
Benchmarking Super-Resolution Algorithms on Real Data
Sep 08, 2017Over the past decades, various super-resolution (SR) techniques have been developed to enhance the spatial resolution of digital images. Despite the great number of methodical contributions, there is still a lack of comparative validations of SR under practical conditions, as capturing real ground truth data is a challenging task. Therefore, current studies are either evaluated 1) on simulated data or 2) on real data without a pixel-wise ground truth. To facilitate comprehensive studies, this paper introduces the publicly available Super-Resolution Erlangen (SupER) database that includes real low-resolution images along with high-resolution ground truth data. Our database comprises image sequences with more than 20k images captured from 14 scenes under various types of motions and photometric conditions. The datasets cover four spatial resolution levels using camera hardware binning. With this database, we benchmark 15 single-image and multi-frame SR algorithms. Our experiments quantitatively analyze SR accuracy and robustness under realistic conditions including independent object and camera motion or photometric variations.