 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Estimation for Fisheye Video With an Application to Temporal Resolution Enhancement
Mar 01, 2023Surveying wide areas with only one camera is a typical scenario in surveillance and automotive applications. Ultra wide-angle fisheye cameras employed to that end produce video data with characteristics that differ significantly from conventional rectilinear imagery as obtained by perspective pinhole cameras. Those characteristics are not considered in typical image and video processing algorithms such as motion estimation, where translation is assumed to be the predominant kind of motion. This contribution introduces an adapted technique for use in block-based motion estimation that takes into the account the projection function of fisheye cameras and thus compensates for the non-perspective properties of fisheye videos. By including suitable projections, the translational motion model that would otherwise only hold for perspective material is exploited, leading to improved motion estimation results without altering the source material. In addition, we discuss extensions that allow for a better prediction of the peripheral image areas, where motion estimation falters due to spatial constraints, and further include calibration information to account for lens properties deviating from the theoretical function. Simulations and experiments are conducted on synthetic as well as real-world fisheye video sequences that are part of a data set created in the context of this paper. Average synthetic and real-world gains of 1.45 and 1.51 dB in luminance PSNR are achieved compared against conventional block matching. Furthermore, the proposed fisheye motion estimation method is successfully applied to motion compensated temporal resolution enhancement, where average gains amount to 0.79 and 0.76 dB.
Centroid adapted frequency selective extrapolation for reconstruction of lost image areas
Jan 12, 2023Lost image areas with different size and arbitrary shape can occur in many scenarios such as error-prone communication, depth-based image rendering or motion compensated wavelet lifting. The goal of image reconstruction is to restore these lost image areas as close to the original as possible. Frequency selective extrapolation is a block-based method for efficiently reconstructing lost areas in images. So far, the actual shape of the lost area is not considered directly. We propose a centroid adaption to enhance the existing frequency selective extrapolation algorithm that takes the shape of lost areas into account. To enlarge the test set for evaluation we further propose a method to generate arbitrarily shaped lost areas. On our large test set, we obtain an average reconstruction gain of 1.29 dB.
Disparity estimation for fisheye images with an application to intermediate view synthesis
Dec 02, 2022



To obtain depth information from a stereo camera setup, a common way is to conduct disparity estimation between the two views; the disparity map thus generated may then also be used to synthesize arbitrary intermediate views. A straightforward approach to disparity estimation is block matching, which performs well with perspective data. When dealing with non-perspective imagery such as obtained from ultra wide-angle fisheye cameras, however, block matching meets its limits. In this paper, an adapted disparity estimation approach for fisheye images is introduced. The proposed method exploits knowledge about the fisheye projection function to transform the fisheye coordinate grid to a corresponding perspective mesh. Offsets between views can thus be determined more accurately, resulting in more reliable disparity maps. By re-projecting the perspective mesh to the fisheye domain, the original fisheye field of view is retained. The benefit of the proposed method is demonstrated in the context of intermediate view synthesis, for which both objectively evaluated as well as visually convincing results are provided.
Motion estimation for fisheye video sequences combining perspective projection with camera calibration information
Dec 02, 2022



Fisheye cameras prove a convenient means in surveillance and automotive applications as they provide a very wide field of view for capturing their surroundings. Contrary to typical rectilinear imagery, however, fisheye video sequences follow a different mapping from the world coordinates to the image plane which is not considered in standard video processing techniques. In this paper, we present a motion estimation method for real-world fisheye videos by combining perspective projection with knowledge about the underlying fisheye projection. The latter is obtained by camera calibration since actual lenses rarely follow exact models. Furthermore, we introduce a re-mapping for ultra-wide angles which would otherwise lead to wrong motion compensation results for the fisheye boundary. Both concepts extend an existing hybrid motion estimation method for equisolid fisheye video sequences that decides between traditional and fisheye block matching in a block-based manner. Compared to that method, the proposed calibration and re-mapping extensions yield gains of up to 0.58 dB in luminance PSNR for real-world fisheye video sequences. Overall gains amount to up to 3.32 dB compared to traditional block matching.
A hybrid motion estimation technique for fisheye video sequences based on equisolid re-projection
Nov 30, 2022
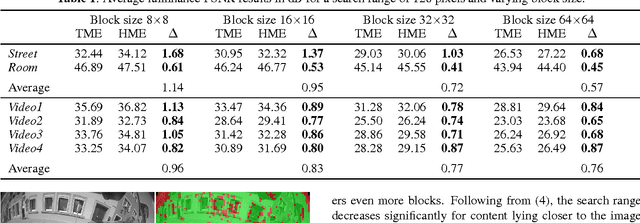

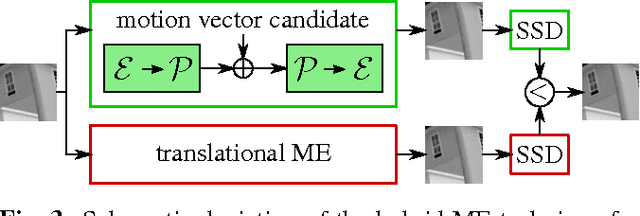
Capturing large fields of view with only one camera is an important aspect in surveillance and automotive applications, but the wide-angle fisheye imagery thus obtained exhibits very special characteristics that may not be very well suited for typical image and video processing methods such as motion estimation. This paper introduces a motion estimation method that adapts to the typical radial characteristics of fisheye video sequences by making use of an equisolid re-projection after moving part of the motion vector search into the perspective domain via a corresponding back-projection. By combining this approach with conventional translational motion estimation and compensation, average gains in luminance PSNR of up to 1.14 dB are achieved for synthetic fish-eye sequences and up to 0.96 dB for real-world data. Maximum gains for selected frame pairs amount to 2.40 dB and 1.39 dB for synthetic and real-world data, respectively.
Temporal error concealment for fisheye video sequences based on equisolid re-projection
Nov 21, 2022



Wide-angle video sequences obtained by fisheye cameras exhibit characteristics that may not very well comply with standard image and video processing techniques such as error concealment. This paper introduces a temporal error concealment technique designed for the inherent characteristics of equisolid fisheye video sequences by applying a re-projection into the equisolid domain after conducting part of the error concealment in the perspective domain. Combining this technique with conventional decoder motion vector estimation achieves average gains of 0.71 dB compared against pure decoder motion vector estimation for the test sequences used. Maximum gains amount to up to 2.04 dB for selected frames.
Reconstruction of images taken by a pair of non-regular sampling sensors using correlation based matching
Apr 07, 2022
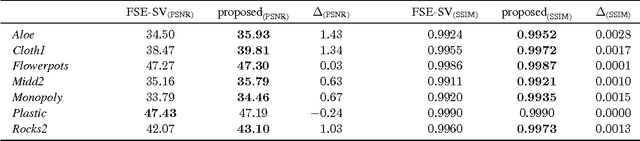
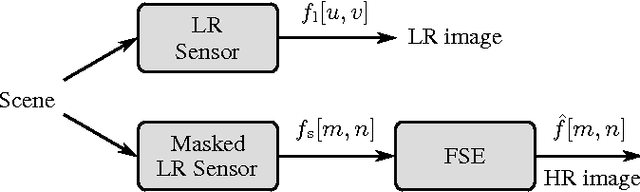
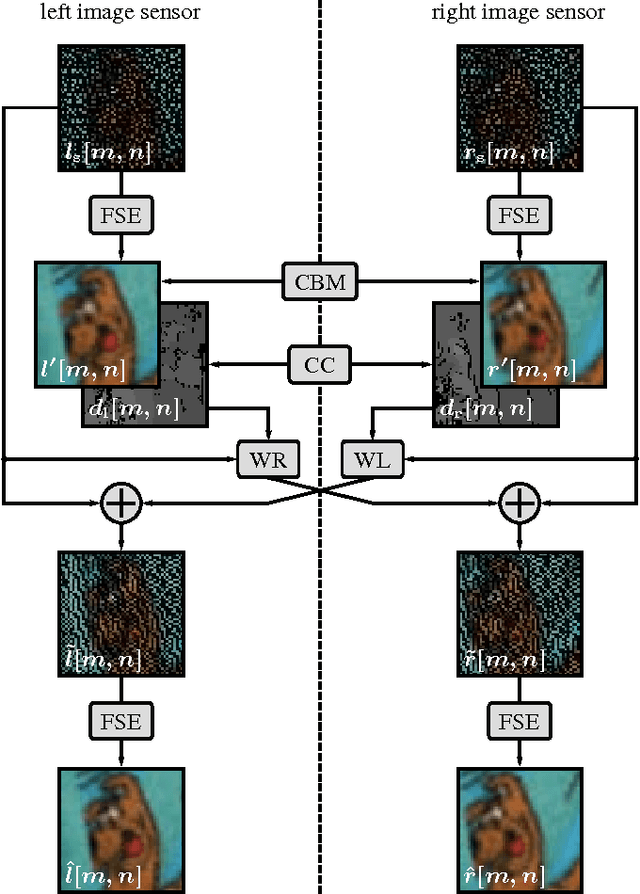
Multi-view image acquisition systems with two or more cameras can be rather costly due to the number of high resolution image sensors that are required. Recently, it has been shown that by covering a low resolution sensor with a non-regular sampling mask and by using an efficient algorithm for image reconstruction, a high resolution image can be obtained. In this paper, a stereo image reconstruction setup for multi-view scenarios is proposed. A scene is captured by a pair of non-regular sampling sensors and by incorporating information from the adjacent view, the reconstruction quality can be increased. Compared to a state-of-the-art single-view reconstruction algorithm, this leads to a visually noticeable average gain in PSNR of 0.74 dB.
Reconstruction of Videos Taken by a Non-Regular Sampling Sensor
Apr 07, 2022
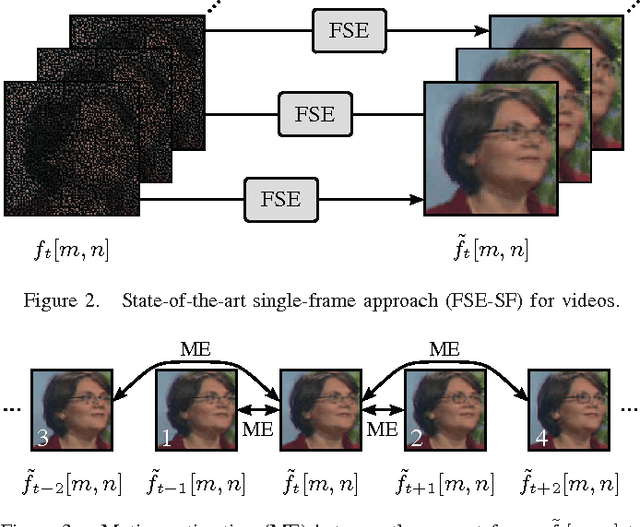
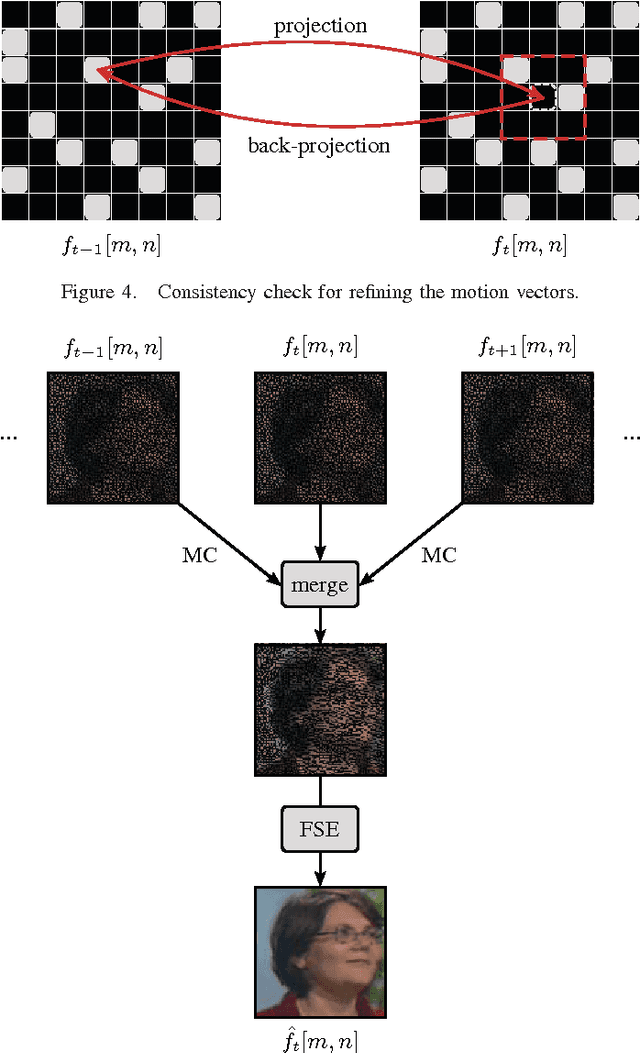
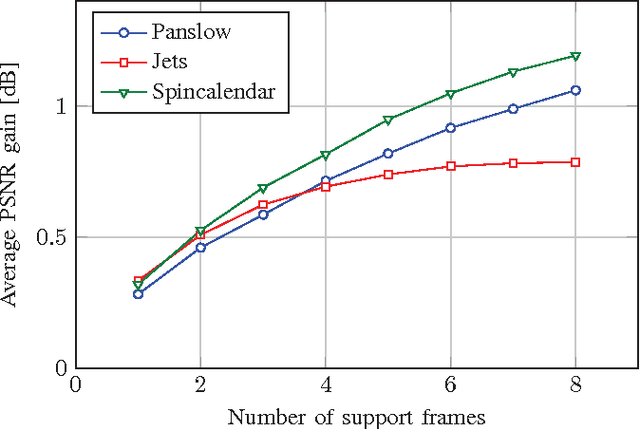
Recently, it has been shown that a high resolution image can be obtained without the usage of a high resolution sensor. The main idea has been that a low resolution sensor is covered with a non-regular sampling mask followed by a reconstruction of the incomplete high resolution image captured this way. In this paper, a multi-frame reconstruction approach is proposed where a video is taken by a non-regular sampling sensor and fully reconstructed afterwards. By utilizing the temporal correlation between neighboring frames, the reconstruction quality can be further enhanced. Compared to a state-of-the-art single-frame reconstruction approach, this leads to a visually noticeable gain in PSNR of up to 1.19 dB on average.
Dynamic Non-Regular Sampling Sensor Using Frequency Selective Reconstruction
Apr 07, 2022
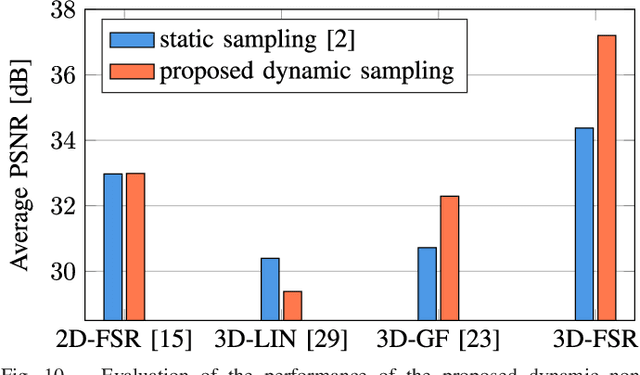


Both a high spatial and a high temporal resolution of images and videos are desirable in many applications such as entertainment systems, monitoring manufacturing processes, or video surveillance. Due to the limited throughput of pixels per second, however, there is always a trade-off between acquiring sequences with a high spatial resolution at a low temporal resolution or vice versa. In this paper, a modified sensor concept is proposed which is able to acquire both a high spatial and a high temporal resolution. This is achieved by dynamically reading out only a subset of pixels in a non-regular order to obtain a high temporal resolution. A full high spatial resolution is then obtained by performing a subsequent three-dimensional reconstruction of the partially acquired frames. The main benefit of the proposed dynamic readout is that for each frame, different sampling points are available which is advantageous since this information can significantly enhance the reconstruction quality of the proposed reconstruction algorithm. Using the proposed dynamic readout strategy, gains in PSNR of up to 8.55 dB are achieved compared to a static readout strategy. Compared to other state-of-the-art techniques like frame rate up-conversion or super-resolution which are also able to reconstruct sequences with both a high spatial and a high temporal resolution, average gains in PSNR of up to 6.58 dB are possible.
Bridging the Simulated-to-Real Gap: Benchmarking Super-Resolution on Real Data
Sep 17, 2018
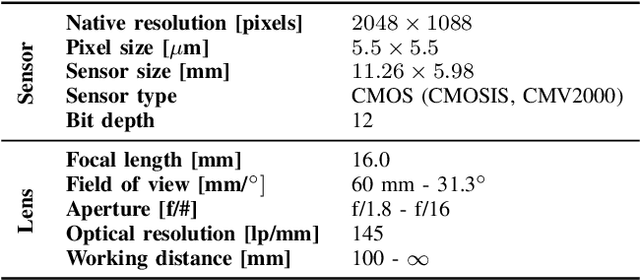
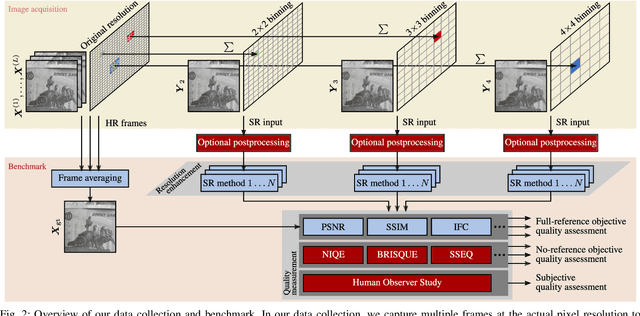

Capturing ground truth data to benchmark super-resolution (SR) is challenging. Therefore, current quantitative studies are mainly evaluated on simulated data artificially sampled from ground truth images. We argue that such evaluations overestimate the actual performance of SR methods compared to their behavior on real images. To bridge this simulated-to-real gap, we introduce the Super-Resolution Erlangen (SupER) database, the first comprehensive laboratory SR database of all-real acquisitions with pixel-wise ground truth. It consists of more than 80k images of 14 scenes combining different facets: CMOS sensor noise, real sampling at four resolution levels, nine scene motion types, two photometric conditions, and lossy video coding at five levels. As such, the database exceeds existing benchmarks by an order of magnitude in quality and quantity. This paper also benchmarks 19 popular single-image and multi-frame algorithms on our data. The benchmark comprises a quantitative study by exploiting ground truth data and qualitative evaluations in a large-scale observer study. We also rigorously investigate agreements between both evaluations from a statistical perspective. One interesting result is that top-performing methods on simulated data may be surpassed by others on real data. Our insights can spur further algorithm development, and the publicy available dataset can foster future evaluations.