 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Processing for the OpenGPT-X Model Family
Oct 11, 2024



This paper presents a comprehensive overview of the data preparation pipeline developed for the OpenGPT-X project, a large-scale initiative aimed at creating open and high-performance multilingual large language models (LLMs). The project goal is to deliver models that cover all major European languages, with a particular focus on real-world applications within the European Union. We explain all data processing steps, starting with the data selection and requirement definition to the preparation of the final datasets for model training. We distinguish between curated data and web data, as each of these categories is handled by distinct pipelines, with curated data undergoing minimal filtering and web data requiring extensive filtering and deduplication. This distinction guided the development of specialized algorithmic solutions for both pipelines. In addition to describing the processing methodologies, we provide an in-depth analysis of the datasets, increasing transparency and alignment with European data regulations. Finally, we share key insights and challenges faced during the project, offering recommendations for future endeavors in large-scale multilingual data preparation for LLMs.
How Hateful are Movies? A Study and Prediction on Movie Subtitles
Aug 19, 2021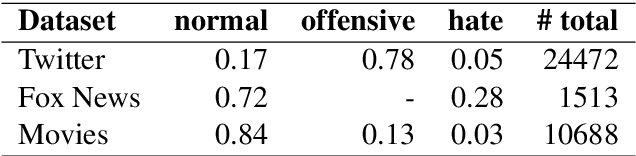

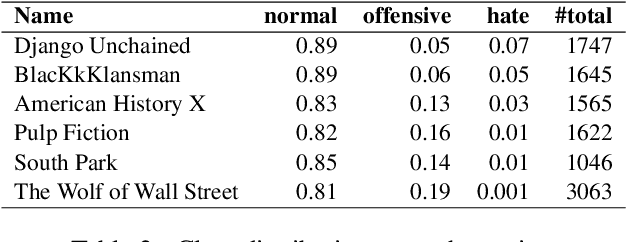
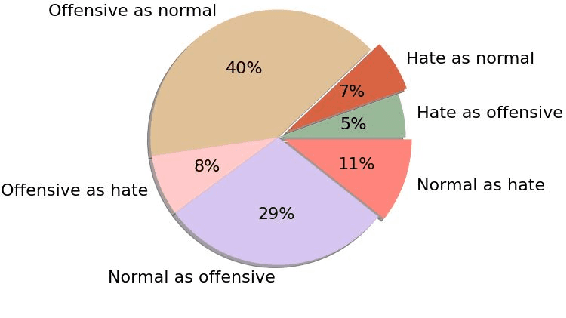
In this research, we investigate techniques to detect hate speech in movies. We introduce a new dataset collected from the subtitles of six movies, where each utterance is annotated either as hate, offensive or normal. We apply transfer learning techniques of domain adaptation and fine-tuning on existing social media datasets, namely from Twitter and Fox News. We evaluate different representations, i.e., Bag of Words (BoW), Bi-directional Long short-term memory (Bi-LSTM), and Bidirectional Encoder Representations from Transformers (BERT) on 11k movie subtitles. The BERT model obtained the best macro-averaged F1-score of 77%. Hence, we show that transfer learning from the social media domain is efficacious in classifying hate and offensive speech in movies through subtitles.