 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetector-Augmented SAMURAI for Long-Duration Drone Tracking
Jan 08, 2026Robust long-term tracking of drone is a critical requirement for modern surveillance systems, given their increasing threat potential. While detector-based approaches typically achieve strong frame-level accuracy, they often suffer from temporal inconsistencies caused by frequent detection dropouts. Despite its practical relevance, research on RGB-based drone tracking is still limited and largely reliant on conventional motion models. Meanwhile, foundation models like SAMURAI have established their effectiveness across other domains, exhibiting strong category-agnostic tracking performance. However, their applicability in drone-specific scenarios has not been investigated yet. Motivated by this gap, we present the first systematic evaluation of SAMURAI's potential for robust drone tracking in urban surveillance settings. Furthermore, we introduce a detector-augmented extension of SAMURAI to mitigate sensitivity to bounding-box initialization and sequence length. Our findings demonstrate that the proposed extension significantly improves robustness in complex urban environments, with pronounced benefits in long-duration sequences - especially under drone exit-re-entry events. The incorporation of detector cues yields consistent gains over SAMURAI's zero-shot performance across datasets and metrics, with success rate improvements of up to +0.393 and FNR reductions of up to -0.475.
Performance Optimization of YOLO-FEDER FusionNet for Robust Drone Detection in Visually Complex Environments
Sep 17, 2025



Drone detection in visually complex environments remains challenging due to background clutter, small object scale, and camouflage effects. While generic object detectors like YOLO exhibit strong performance in low-texture scenes, their effectiveness degrades in cluttered environments with low object-background separability. To address these limitations, this work presents an enhanced iteration of YOLO-FEDER FusionNet -- a detection framework that integrates generic object detection with camouflage object detection techniques. Building upon the original architecture, the proposed iteration introduces systematic advancements in training data composition, feature fusion strategies, and backbone design. Specifically, the training process leverages large-scale, photo-realistic synthetic data, complemented by a small set of real-world samples, to enhance robustness under visually complex conditions. The contribution of intermediate multi-scale FEDER features is systematically evaluated, and detection performance is comprehensively benchmarked across multiple YOLO-based backbone configurations. Empirical results indicate that integrating intermediate FEDER features, in combination with backbone upgrades, contributes to notable performance improvements. In the most promising configuration -- YOLO-FEDER FusionNet with a YOLOv8l backbone and FEDER features derived from the DWD module -- these enhancements lead to a FNR reduction of up to 39.1 percentage points and a mAP increase of up to 62.8 percentage points at an IoU threshold of 0.5, compared to the initial baseline.
Rotation Invariance in Floor Plan Digitization using Zernike Moments
Apr 04, 2025Nowadays, a lot of old floor plans exist in printed form or are stored as scanned raster images. Slight rotations or shifts may occur during scanning. Bringing floor plans of this form into a machine readable form to enable further use, still poses a problem. Therefore, we propose an end-to-end pipeline that pre-processes the image and leverages a novel approach to create a region adjacency graph (RAG) from the pre-processed image and predict its nodes. By incorporating normalization steps into the RAG feature extraction, we significantly improved the rotation invariance of the RAG feature calculation. Moreover, applying our method leads to an improved F1 score and IoU on rotated data. Furthermore, we proposed a wall splitting algorithm for partitioning walls into segments associated with the corresponding rooms.
Transforming Engineering Diagrams: A Novel Approach for P&ID Digitization using Transformers
Nov 21, 2024The digitization of complex technical systems, such as Piping and Instrumentation Diagrams (P&IDs), is crucial for efficient maintenance and operation of complex systems in hydraulic and process engineering. Previous approaches often rely on separate modules that analyze diagram elements individually, neglecting the diagram's overall structure. We address this limitation by proposing a novel approach that utilizes the Relationformer, a state-of-the-art deep learning architecture, to extract graphs from P&IDs. Our method leverages the ability of the Relationformer to simultaneously detect objects and their relationships in images, making it suitable for the task of graph extraction from engineering diagrams. We apply our proposed approach to both real-world and synthetically created P&ID datasets, and evaluate its effectiveness by comparing it with a modular digitization approach based on recent literature. We present PID2Graph, the first publicly accessible P&ID dataset featuring comprehensive labels for the graph structure, including symbols, nodes and their connections that is used for evaluation. To understand the effect of patching and stitching of both of the approaches, we compare values before and after merging the patches. For the real-world data, the Relationformer achieves convincing results, outperforming the modular digitization approach for edge detection by more than 25%. Our work provides a comprehensive framework for assessing the performance of P&ID digitization methods and opens up new avenues for research in this area using transformer architectures. The P&ID dataset used for evaluation will be published and publicly available upon acceptance of the paper.
SynDroneVision: A Synthetic Dataset for Image-Based Drone Detection
Nov 08, 2024



Developing robust drone detection systems is often constrained by the limited availability of large-scale annotated training data and the high costs associated with real-world data collection. However, leveraging synthetic data generated via game engine-based simulations provides a promising and cost-effective solution to overcome this issue. Therefore, we present SynDroneVision, a synthetic dataset specifically designed for RGB-based drone detection in surveillance applications. Featuring diverse backgrounds, lighting conditions, and drone models, SynDroneVision offers a comprehensive training foundation for deep learning algorithms. To evaluate the dataset's effectiveness, we perform a comparative analysis across a selection of recent YOLO detection models. Our findings demonstrate that SynDroneVision is a valuable resource for real-world data enrichment, achieving notable enhancements in model performance and robustness, while significantly reducing the time and costs of real-world data acquisition. SynDroneVision will be publicly released upon paper acceptance.
YOLO-FEDER FusionNet: A Novel Deep Learning Architecture for Drone Detection
Jun 17, 2024



Predominant methods for image-based drone detection frequently rely on employing generic object detection algorithms like YOLOv5. While proficient in identifying drones against homogeneous backgrounds, these algorithms often struggle in complex, highly textured environments. In such scenarios, drones seamlessly integrate into the background, creating camouflage effects that adversely affect the detection quality. To address this issue, we introduce a novel deep learning architecture called YOLO-FEDER FusionNet. Unlike conventional approaches, YOLO-FEDER FusionNet combines generic object detection methods with the specialized strength of camouflage object detection techniques to enhance drone detection capabilities. Comprehensive evaluations of YOLO-FEDER FusionNet show the efficiency of the proposed model and demonstrate substantial improvements in both reducing missed detections and false alarms.
LORD: Leveraging Open-Set Recognition with Unknown Data
Aug 24, 2023



Handling entirely unknown data is a challenge for any deployed classifier. Classification models are typically trained on a static pre-defined dataset and are kept in the dark for the open unassigned feature space. As a result, they struggle to deal with out-of-distribution data during inference. Addressing this task on the class-level is termed open-set recognition (OSR). However, most OSR methods are inherently limited, as they train closed-set classifiers and only adapt the downstream predictions to OSR. This work presents LORD, a framework to Leverage Open-set Recognition by exploiting unknown Data. LORD explicitly models open space during classifier training and provides a systematic evaluation for such approaches. We identify three model-agnostic training strategies that exploit background data and applied them to well-established classifiers. Due to LORD's extensive evaluation protocol, we consistently demonstrate improved recognition of unknown data. The benchmarks facilitate in-depth analysis across various requirement levels. To mitigate dependency on extensive and costly background datasets, we explore mixup as an off-the-shelf data generation technique. Our experiments highlight mixup's effectiveness as a substitute for background datasets. Lightweight constraints on mixup synthesis further improve OSR performance.
Exploring the Open World Using Incremental Extreme Value Machines
May 30, 2022

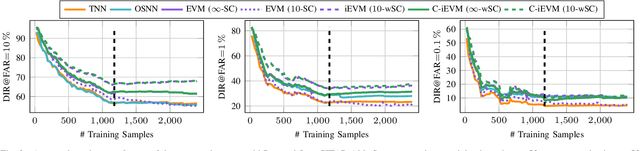

Dynamic environments require adaptive applications. One particular machine learning problem in dynamic environments is open world recognition. It characterizes a continuously changing domain where only some classes are seen in one batch of the training data and such batches can only be learned incrementally. Open world recognition is a demanding task that is, to the best of our knowledge, addressed by only a few methods. This work introduces a modification of the widely known Extreme Value Machine (EVM) to enable open world recognition. Our proposed method extends the EVM with a partial model fitting function by neglecting unaffected space during an update. This reduces the training time by a factor of 28. In addition, we provide a modified model reduction using weighted maximum K-set cover to strictly bound the model complexity and reduce the computational effort by a factor of 3.5 from 2.1 s to 0.6 s. In our experiments, we rigorously evaluate openness with two novel evaluation protocols. The proposed method achieves superior accuracy of about 12 % and computational efficiency in the tasks of image classification and face recognition.
Evaluation of CNN-based Single-Image Depth Estimation Methods
May 03, 2018
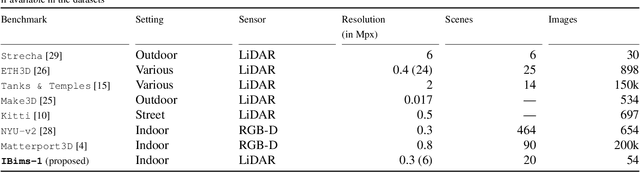

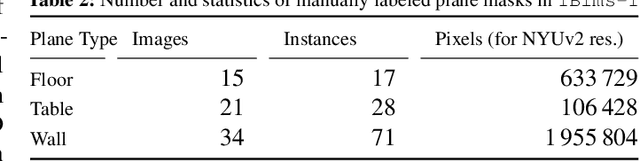
While an increasing interest in deep models for single-image depth estimation methods can be observed, established schemes for their evaluation are still limited. We propose a set of novel quality criteria, allowing for a more detailed analysis by focusing on specific characteristics of depth maps. In particular, we address the preservation of edges and planar regions, depth consistency, and absolute distance accuracy. In order to employ these metrics to evaluate and compare state-of-the-art single-image depth estimation approaches, we provide a new high-quality RGB-D dataset. We used a DSLR camera together with a laser scanner to acquire high-resolution images and highly accurate depth maps. Experimental results show the validity of our proposed evaluation protocol.