 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Learning for Human Settlement Extent Regression and Local Climate Zone Classification
Nov 23, 2020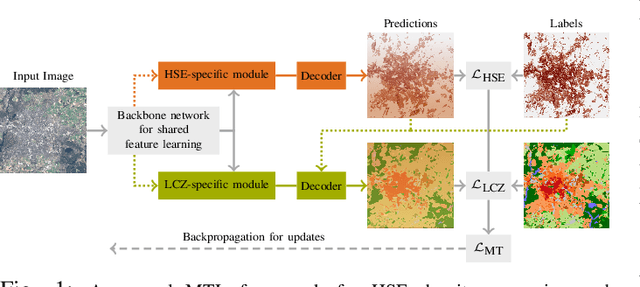
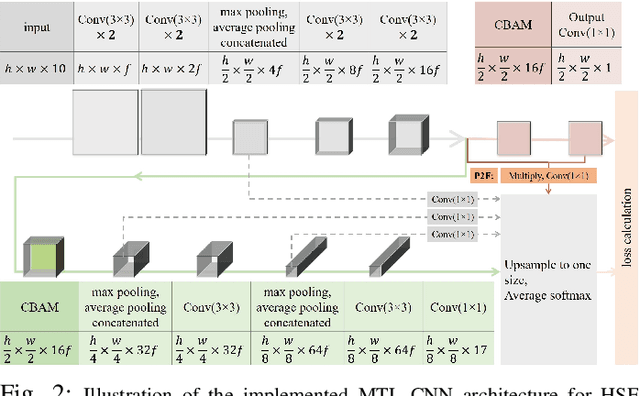
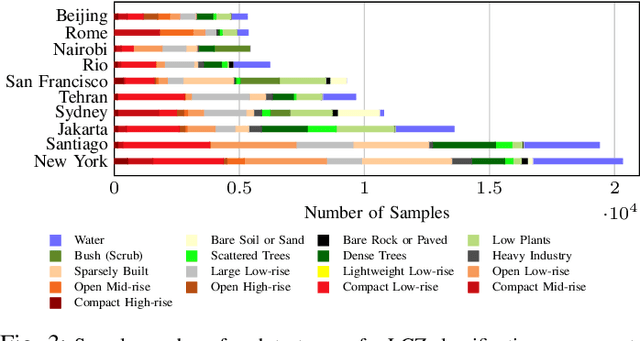
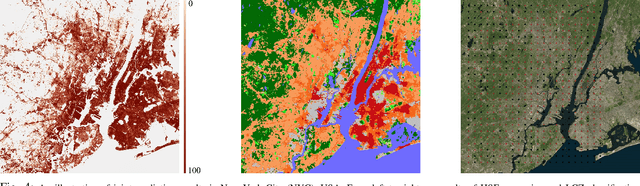
Human Settlement Extent (HSE) and Local Climate Zone (LCZ) maps are both essential sources, e.g., for sustainable urban development and Urban Heat Island (UHI) studies. Remote sensing (RS)- and deep learning (DL)-based classification approaches play a significant role by providing the potential for global mapping. However, most of the efforts only focus on one of the two schemes, usually on a specific scale. This leads to unnecessary redundancies, since the learned features could be leveraged for both of these related tasks. In this letter, the concept of multi-task learning (MTL) is introduced to HSE regression and LCZ classification for the first time. We propose a MTL framework and develop an end-to-end Convolutional Neural Network (CNN), which consists of a backbone network for shared feature learning, attention modules for task-specific feature learning, and a weighting strategy for balancing the two tasks. We additionally propose to exploit HSE predictions as a prior for LCZ classification to enhance the accuracy. The MTL approach was extensively tested with Sentinel-2 data of 13 cities across the world. The results demonstrate that the framework is able to provide a competitive solution for both tasks.
A Generalized Multi-Task Learning Approach to Stereo DSM Filtering in Urban Areas
Apr 07, 2020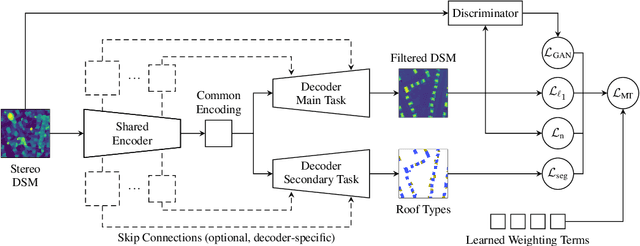
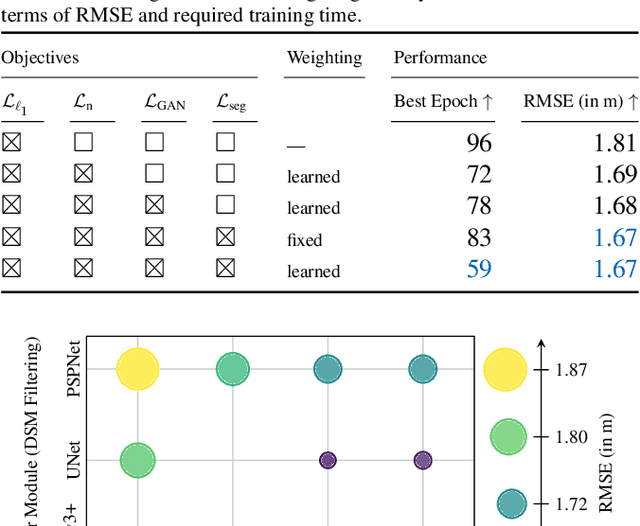
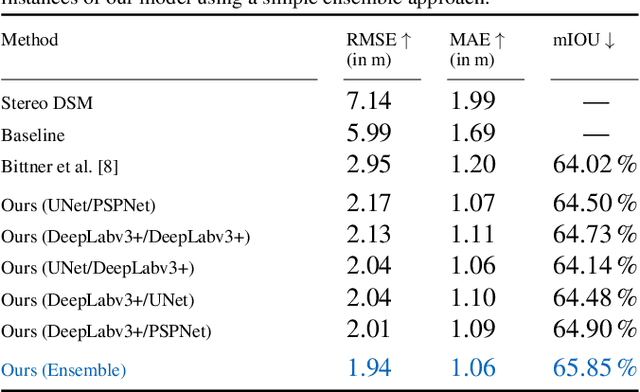
City models and height maps of urban areas serve as a valuable data source for numerous applications, such as disaster management or city planning. While this information is not globally available, it can be substituted by digital surface models (DSMs), automatically produced from inexpensive satellite imagery. However, stereo DSMs often suffer from noise and blur. Furthermore, they are heavily distorted by vegetation, which is of lesser relevance for most applications. Such basic models can be filtered by convolutional neural networks (CNNs), trained on labels derived from digital elevation models (DEMs) and 3D city models, in order to obtain a refined DSM. We propose a modular multi-task learning concept that consolidates existing approaches into a generalized framework. Our encoder-decoder models with shared encoders and multiple task-specific decoders leverage roof type classification as a secondary task and multiple objectives including a conditional adversarial term. The contributing single-objective losses are automatically weighted in the final multi-task loss function based on learned uncertainty estimates. We evaluated the performance of specific instances of this family of network architectures. Our method consistently outperforms the state of the art on common data, both quantitatively and qualitatively, and generalizes well to a new dataset of an independent study area.
Weakly Supervised Semantic Segmentation of Satellite Images for Land Cover Mapping -- Challenges and Opportunities
Feb 19, 2020
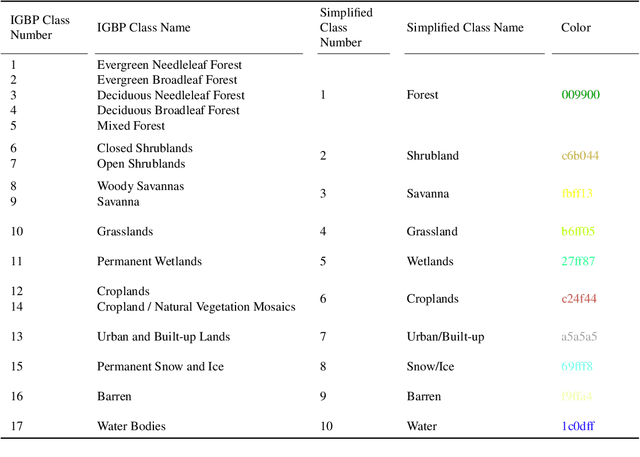
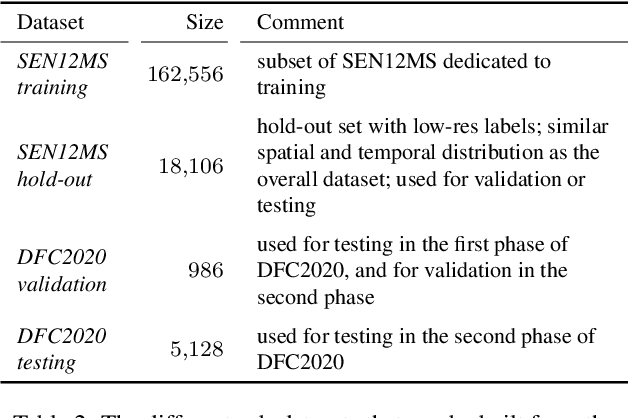
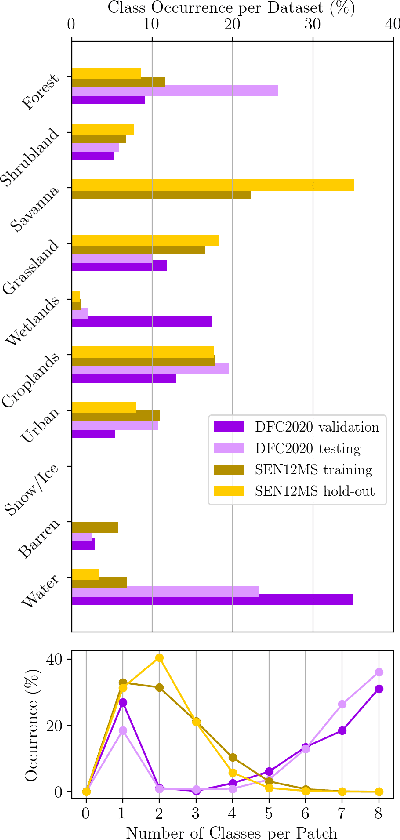
Fully automatic large-scale land cover mapping belongs to the core challenges addressed by the remote sensing community. Usually, the basis of this task is formed by (supervised) machine learning models. However, in spite of recent growth in the availability of satellite observations, accurate training data remains comparably scarce. On the other hand, numerous global land cover products exist and can be accessed often free-of-charge. Unfortunately, these maps are typically of a much lower resolution than modern day satellite imagery. Besides, they always come with a significant amount of noise, as they cannot be considered ground truth, but are products of previous (semi-)automatic prediction tasks. Therefore, this paper seeks to make a case for the application of weakly supervised learning strategies to get the most out of available data sources and achieve progress in high-resolution large-scale land cover mapping. Challenges and opportunities are discussed based on the SEN12MS dataset, for which also some baseline results are shown. These baselines indicate that there is still a lot of potential for dedicated approaches designed to deal with remote sensing-specific forms of weak supervision.
MultiDepth: Single-Image Depth Estimation via Multi-Task Regression and Classification
Jul 25, 2019



We introduce MultiDepth, a novel training strategy and convolutional neural network (CNN) architecture that allows approaching single-image depth estimation (SIDE) as a multi-task problem. SIDE is an important part of road scene understanding. It, thus, plays a vital role in advanced driver assistance systems and autonomous vehicles. Best results for the SIDE task so far have been achieved using deep CNNs. However, optimization of regression problems, such as estimating depth, is still a challenging task. For the related tasks of image classification and semantic segmentation, numerous CNN-based methods with robust training behavior have been proposed. Hence, in order to overcome the notorious instability and slow convergence of depth value regression during training, MultiDepth makes use of depth interval classification as an auxiliary task. The auxiliary task can be disabled at test-time to predict continuous depth values using the main regression branch more efficiently. We applied MultiDepth to road scenes and present results on the KITTI depth prediction dataset. In experiments, we were able to show that end-to-end multi-task learning with both, regression and classification, is able to considerably improve training and yield more accurate results.
Auxiliary Tasks in Multi-task Learning
May 17, 2018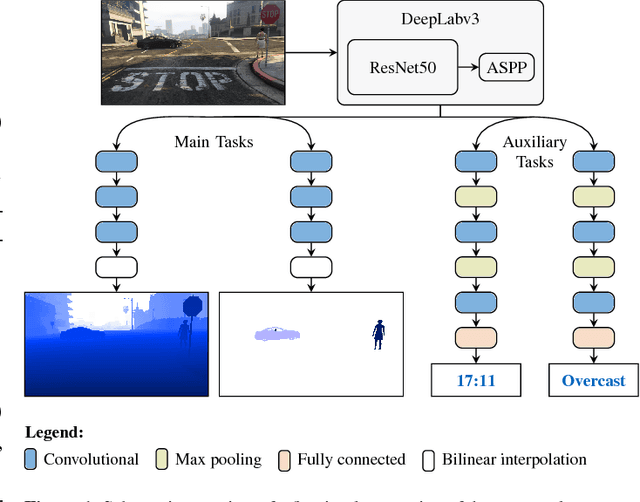

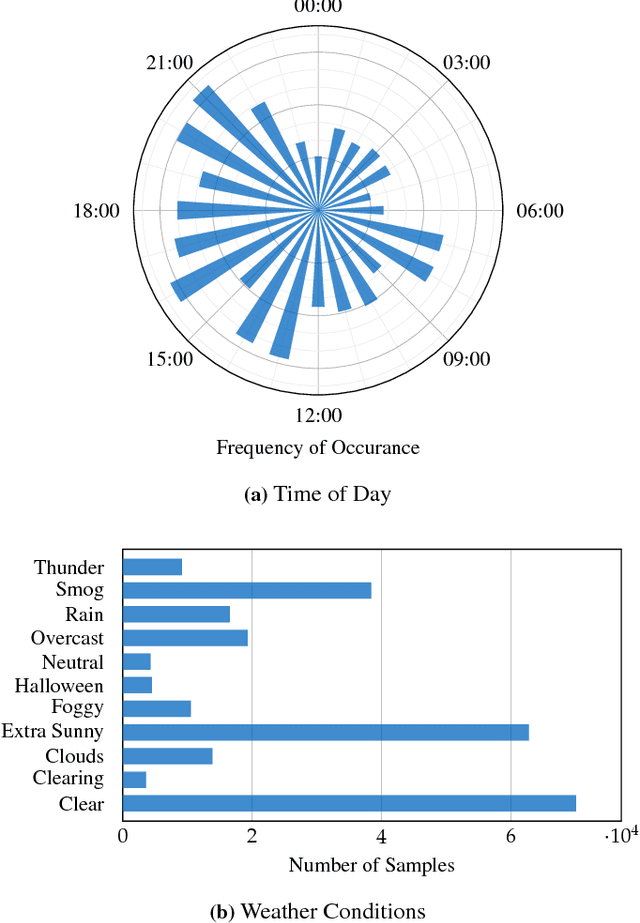
Multi-task convolutional neural networks (CNNs) have shown impressive results for certain combinations of tasks, such as single-image depth estimation (SIDE) and semantic segmentation. This is achieved by pushing the network towards learning a robust representation that generalizes well to different atomic tasks. We extend this concept by adding auxiliary tasks, which are of minor relevance for the application, to the set of learned tasks. As a kind of additional regularization, they are expected to boost the performance of the ultimately desired main tasks. To study the proposed approach, we picked vision-based road scene understanding (RSU) as an exemplary application. Since multi-task learning requires specialized datasets, particularly when using extensive sets of tasks, we provide a multi-modal dataset for multi-task RSU, called synMT. More than 2.5 $\cdot$ 10^5 synthetic images, annotated with 21 different labels, were acquired from the video game Grand Theft Auto V (GTA V). Our proposed deep multi-task CNN architecture was trained on various combination of tasks using synMT. The experiments confirmed that auxiliary tasks can indeed boost network performance, both in terms of final results and training time.
Evaluation of CNN-based Single-Image Depth Estimation Methods
May 03, 2018
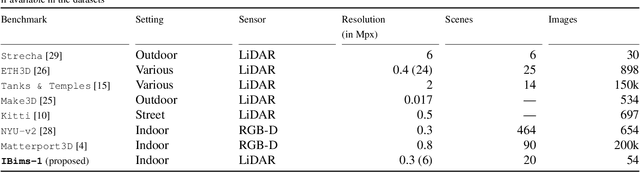

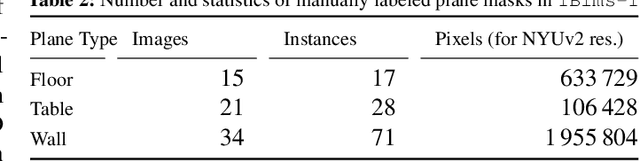
While an increasing interest in deep models for single-image depth estimation methods can be observed, established schemes for their evaluation are still limited. We propose a set of novel quality criteria, allowing for a more detailed analysis by focusing on specific characteristics of depth maps. In particular, we address the preservation of edges and planar regions, depth consistency, and absolute distance accuracy. In order to employ these metrics to evaluate and compare state-of-the-art single-image depth estimation approaches, we provide a new high-quality RGB-D dataset. We used a DSLR camera together with a laser scanner to acquire high-resolution images and highly accurate depth maps. Experimental results show the validity of our proposed evaluation protocol.