 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Semantic Segmentation of Satellite Images for Land Cover Mapping -- Challenges and Opportunities
Paper and Code

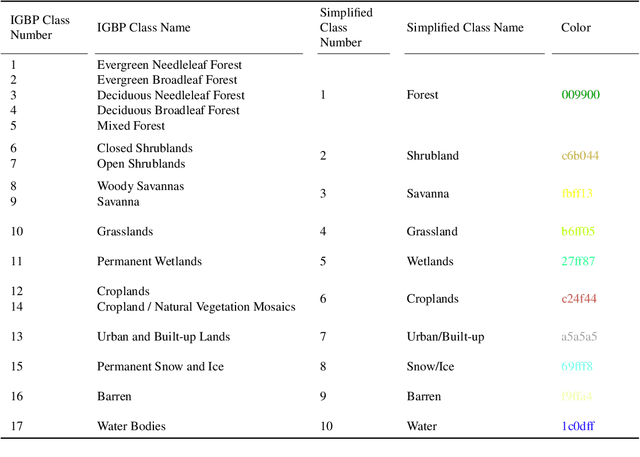
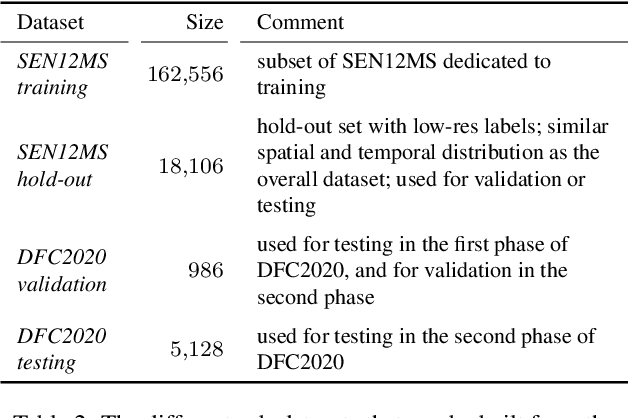
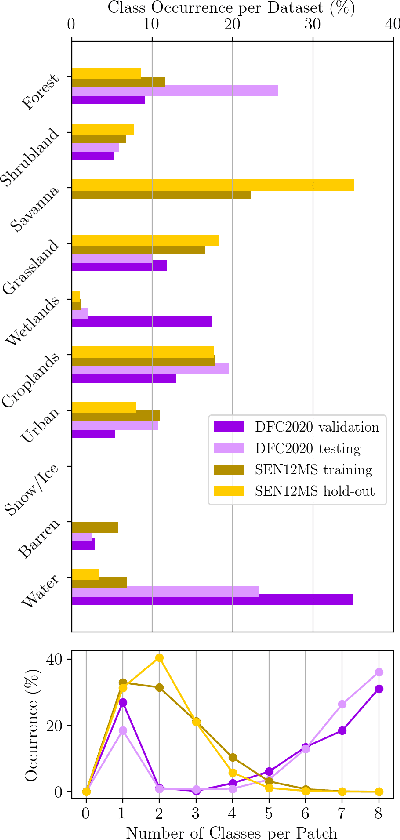
Fully automatic large-scale land cover mapping belongs to the core challenges addressed by the remote sensing community. Usually, the basis of this task is formed by (supervised) machine learning models. However, in spite of recent growth in the availability of satellite observations, accurate training data remains comparably scarce. On the other hand, numerous global land cover products exist and can be accessed often free-of-charge. Unfortunately, these maps are typically of a much lower resolution than modern day satellite imagery. Besides, they always come with a significant amount of noise, as they cannot be considered ground truth, but are products of previous (semi-)automatic prediction tasks. Therefore, this paper seeks to make a case for the application of weakly supervised learning strategies to get the most out of available data sources and achieve progress in high-resolution large-scale land cover mapping. Challenges and opportunities are discussed based on the SEN12MS dataset, for which also some baseline results are shown. These baselines indicate that there is still a lot of potential for dedicated approaches designed to deal with remote sensing-specific forms of weak supervision.