 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree Forensic Cues for JPEG AI Images
Apr 04, 2025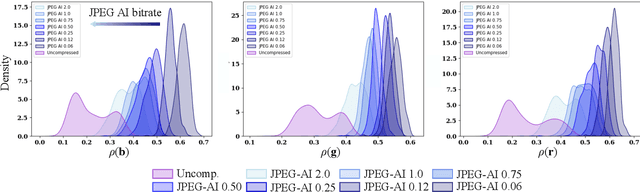

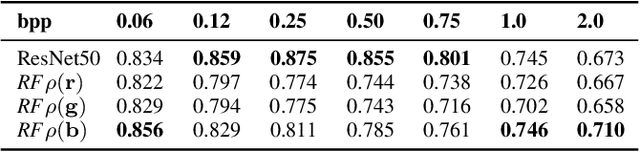
The JPEG standard was vastly successful. Currently, the first AI-based compression method ``JPEG AI'' will be standardized. JPEG AI brings remarkable benefits. JPEG AI images exhibit impressive image quality at bitrates that are an order of magnitude lower than images compressed with traditional JPEG. However, forensic analysis of JPEG AI has to be completely re-thought: forensic tools for traditional JPEG do not transfer to JPEG AI, and artifacts from JPEG AI are easily confused with artifacts from artificially generated images (``DeepFakes''). This creates a need for novel forensic approaches to detection and distinction of JPEG AI images. In this work, we make a first step towards a forensic JPEG AI toolset. We propose three cues for forensic algorithms for JPEG AI. These algorithms address three forensic questions: first, we show that the JPEG AI preprocessing introduces correlations in the color channels that do not occur in uncompressed images. Second, we show that repeated compression of JPEG AI images leads to diminishing distortion differences. This can be used to detect recompression, in a spirit similar to some classic JPEG forensics methods. Third, we show that the quantization of JPEG AI images in the latent space can be used to distinguish real images with JPEG AI compression from synthetically generated images. The proposed methods are interpretable for a forensic analyst, and we hope that they inspire further research in the forensics of AI-compressed images.
Overview of Variable Rate Coding in JPEG AI
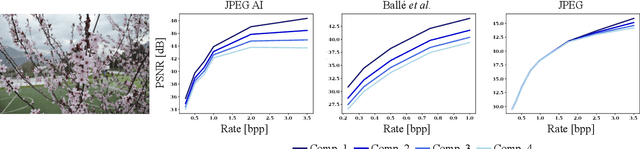
Mar 20, 2025Empirical evidence has demonstrated that learning-based image compression can outperform classical compression frameworks. This has led to the ongoing standardization of learned-based image codecs, namely Joint Photographic Experts Group (JPEG) AI. The objective of JPEG AI is to enhance compression efficiency and provide a software and hardwarefriendly solution. Based on our research, JPEG AI represents the first standardization that can facilitate the implementation of a learned image codec on a mobile device. This article presents an overview of the variable rate coding functionality in JPEG AI, which includes three variable rate adaptations: a threedimensional quality map, a fast bit rate matching algorithm, and a training strategy. The variable rate adaptations offer a continuous rate function up to 2.0 bpp, exhibiting a high level of performance, a flexible bit allocation between different color components, and a region of interest function for the specified use case. The evaluation of performance encompasses both objective and subjective results. With regard to the objective bit rate matching, the main profile with low complexity yielded a 13.1% BD-rate gain over VVC intra, while the high profile with high complexity achieved a 19.2% BD-rate gain over VVC intra. The BD-rate result is calculated as the mean of the seven perceptual metrics defined in the JPEG AI common test conditions. With respect to subjective results, the example of improving the quality of the region of interest is illustrated.
On Annotation-free Optimization of Video Coding for Machines
Jun 12, 2024
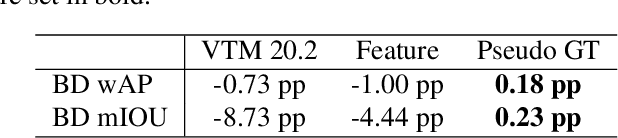
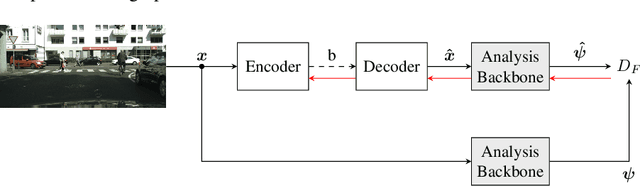
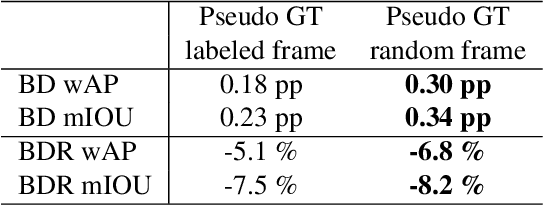
Today, image and video data is not only viewed by humans, but also automatically analyzed by computer vision algorithms. However, current coding standards are optimized for human perception. Emerging from this, research on video coding for machines tries to develop coding methods designed for machines as information sink. Since many of these algorithms are based on neural networks, most proposals for video coding for machines build upon neural compression. So far, optimizing the compression by applying the task loss of the analysis network, for which ground truth data is needed, is achieving the best coding performance. But ground truth data is difficult to obtain and thus an optimization without ground truth is preferred. In this paper, we present an annotation-free optimization strategy for video coding for machines. We measure the distortion by calculating the task loss of the analysis network. Therefore, the predictions on the compressed image are compared with the predictions on the original image, instead of the ground truth data. Our results show that this strategy can even outperform training with ground truth data with rate savings of up to 7.5 %. By using the non-annotated training data, the rate gains can be further increased up to 8.2 %.
Analysis of Neural Video Compression Networks for 360-Degree Video Coding
Feb 15, 2024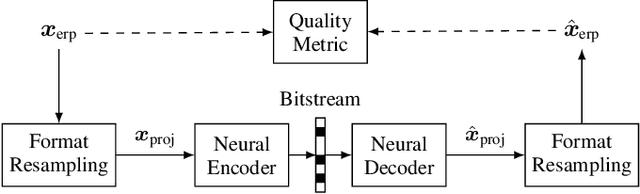
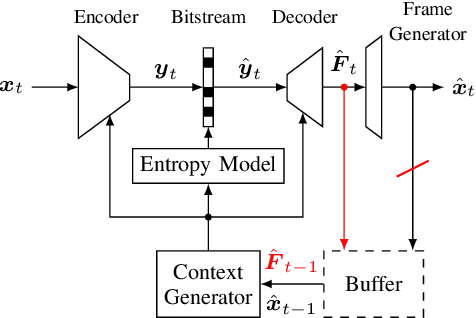
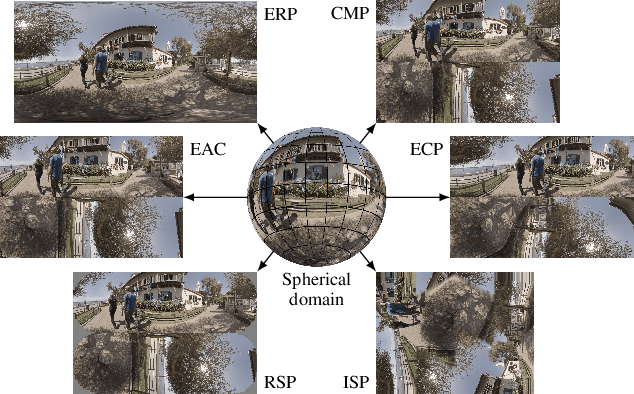
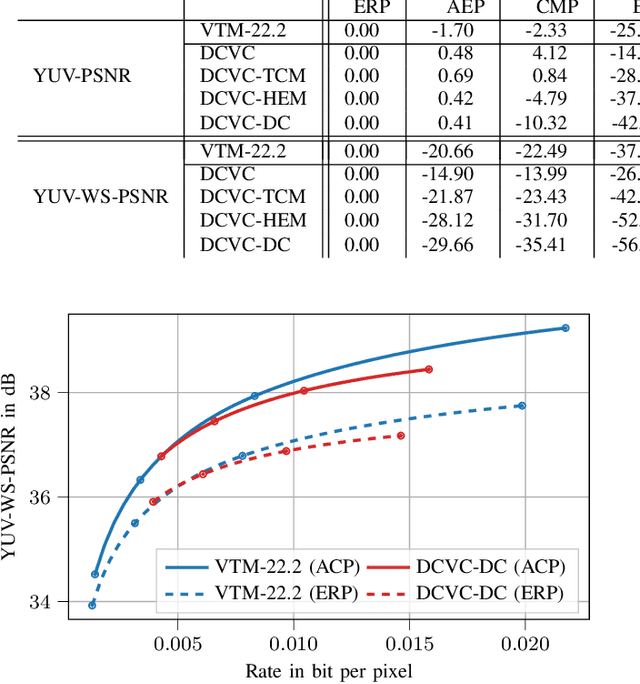
With the increasing efforts of bringing high-quality virtual reality technologies into the market, efficient 360-degree video compression gains in importance. As such, the state-of-the-art H.266/VVC video coding standard integrates dedicated tools for 360-degree video, and considerable efforts have been put into designing 360-degree projection formats with improved compression efficiency. For the fast-evolving field of neural video compression networks (NVCs), the effects of different 360-degree projection formats on the overall compression performance have not yet been investigated. It is thus unclear, whether a resampling from the conventional equirectangular projection (ERP) to other projection formats yields similar gains for NVCs as for hybrid video codecs, and which formats perform best. In this paper, we analyze several generations of NVCs and an extensive set of 360-degree projection formats with respect to their compression performance for 360-degree video. Based on our analysis, we find that projection format resampling yields significant improvements in compression performance also for NVCs. The adjusted cubemap projection (ACP) and equatorial cylindrical projection (ECP) show to perform best and achieve rate savings of more than 55% compared to ERP based on WS-PSNR for the most recent NVC. Remarkably, the observed rate savings are higher than for H.266/VVC, emphasizing the importance of projection format resampling for NVCs.
Conditional Residual Coding: A Remedy for Bottleneck Problems in Conditional Inter Frame Coding
Jul 24, 2023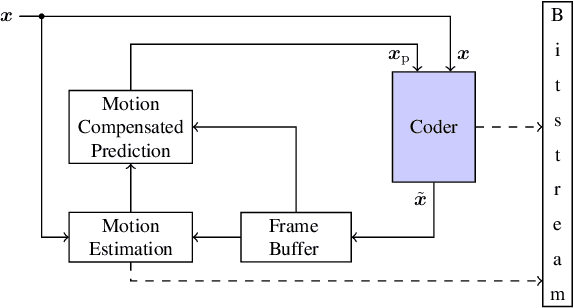
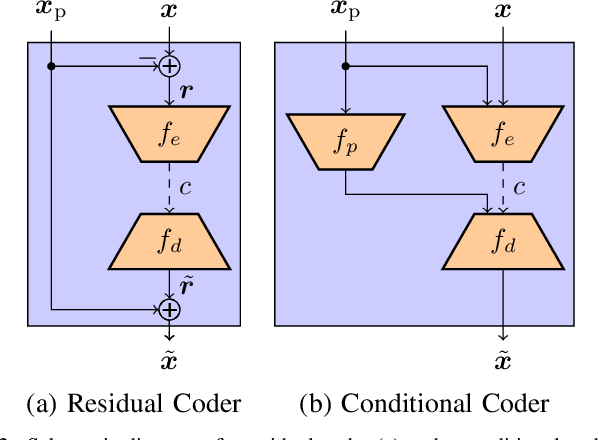
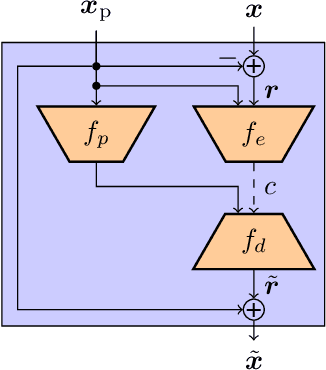
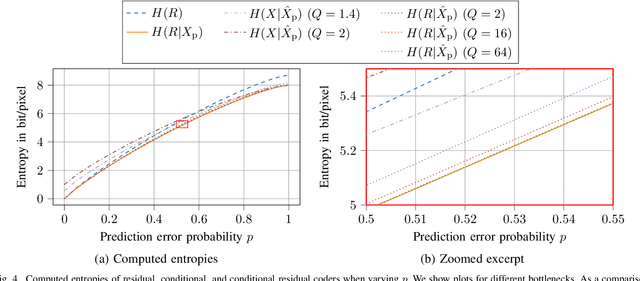
Conditional coding is a new video coding paradigm enabled by neural-network-based compression. It can be shown that conditional coding is in theory better than the traditional residual coding, which is widely used in video compression standards like HEVC or VVC. However, on closer inspection, it becomes clear that conditional coders can suffer from information bottlenecks in the prediction path, i.e., that due to the data processing inequality not all information from the prediction signal can be passed to the reconstructed signal, thereby impairing the coder performance. In this paper we propose the conditional residual coding concept, which we derive from information theoretical properties of the conditional coder. This coder significantly reduces the influence of bottlenecks, while maintaining the theoretical performance of the conditional coder. We provide a theoretical analysis of the coding paradigm and demonstrate the performance of the conditional residual coder in a practical example. We show that conditional residual coders alleviate the disadvantages of conditional coders while being able to maintain their advantages over residual coders. In the spectrum of residual and conditional coding, we can therefore consider them as ``the best from both worlds''.
Spatially-Adaptive Learning-Based Image Compression with Hierarchical Multi-Scale Latent Spaces
Jul 12, 2023



Adaptive block partitioning is responsible for large gains in current image and video compression systems. This method is able to compress large stationary image areas with only a few symbols, while maintaining a high level of quality in more detailed areas. Current state-of-the-art neural-network-based image compression systems however use only one scale to transmit the latent space. In previous publications, we proposed RDONet, a scheme to transmit the latent space in multiple spatial resolutions. Following this principle, we extend a state-of-the-art compression network by a second hierarchical latent-space level to enable multi-scale processing. We extend the existing rate variability capabilities of RDONet by a gain unit. With that we are able to outperform an equivalent traditional autoencoder by 7% rate savings. Furthermore, we show that even though we add an additional latent space, the complexity only increases marginally and the decoding time can potentially even be decreased.
Processing Energy Modeling for Neural Network Based Image Compression
Jun 29, 2023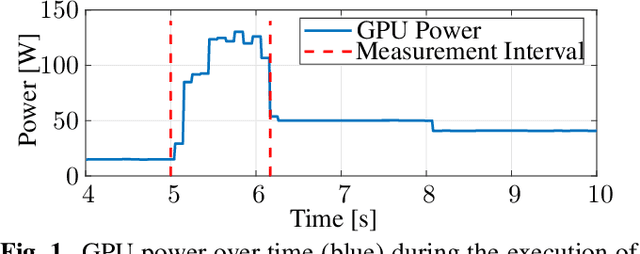
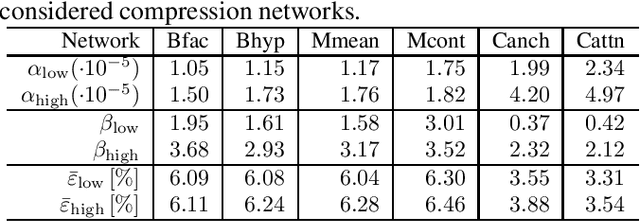
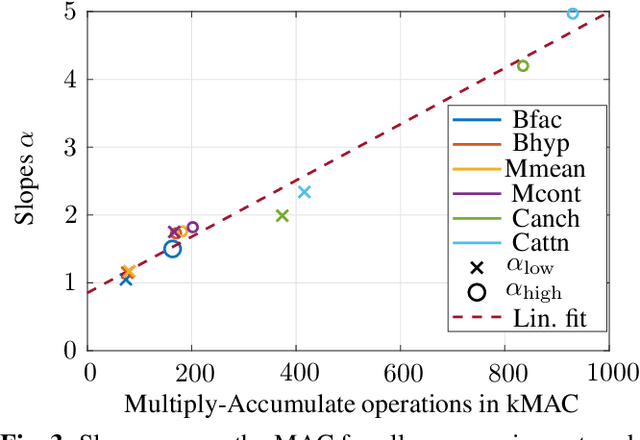
Nowadays, the compression performance of neural-networkbased image compression algorithms outperforms state-of-the-art compression approaches such as JPEG or HEIC-based image compression. Unfortunately, most neural-network based compression methods are executed on GPUs and consume a high amount of energy during execution. Therefore, this paper performs an in-depth analysis on the energy consumption of state-of-the-art neural-network based compression methods on a GPU and show that the energy consumption of compression networks can be estimated using the image size with mean estimation errors of less than 7%. Finally, using a correlation analysis, we find that the number of operations per pixel is the main driving force for energy consumption and deduce that the network layers up to the second downsampling step are consuming most energy.
Learned Wavelet Video Coding using Motion Compensated Temporal Filtering
May 25, 2023



We present an end-to-end trainable wavelet video coder based on motion compensated temporal filtering (MCTF). Thereby, we introduce a different coding scheme for learned video compression, which is currently dominated by residual and conditional coding approaches. By performing discrete wavelet transforms in temporal, horizontal, and vertical dimension, we obtain an explainable framework with spatial and temporal scalability. We focus on investigating a novel trainable MCTF module that is implemented using the lifting scheme. We show how multiple temporal decomposition levels in MCTF can be considered during training and how larger temporal displacements due to the MCTF coding order can be handled. Further, we present a content adaptive extension to MCTF which adapts to different motion strengths during inference. In our experiments, we compare our MCTF-based approach to learning-based conditional coders and traditional hybrid video coding. Especially at high rates, our approach has promising rate-distortion performance. Our method achieves average Bj{\o}ntegaard Delta savings of up to 21% over HEVC on the UVG data set and thereby outperforms state-of-the-art learned video coders.
Multiscale Augmented Normalizing Flows for Image Compression
May 09, 2023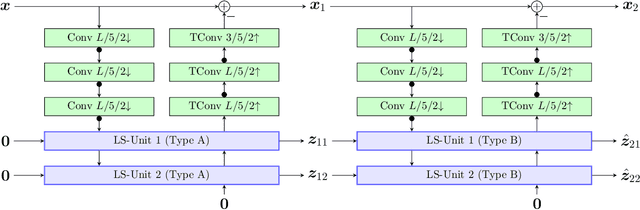
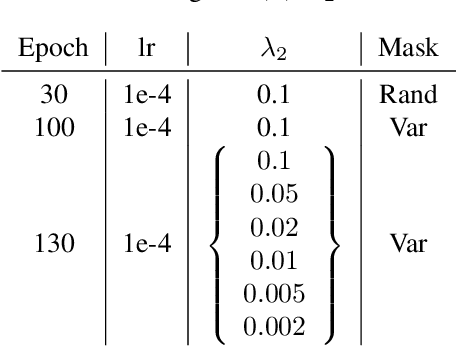
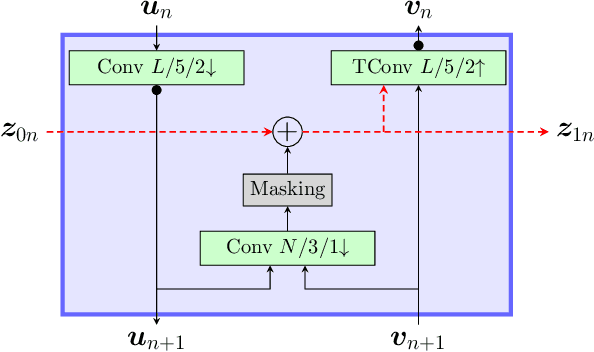
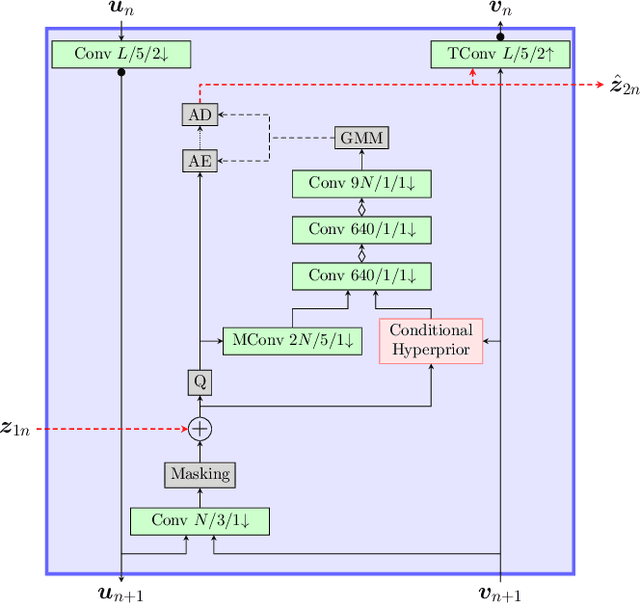
Most learning-based image compression methods lack efficiency for high image quality due to their non-invertible design. The decoding function of the frequently applied compressive autoencoder architecture is only an approximated inverse of the encoding transform. This issue can be resolved by using invertible latent variable models, which allow a perfect reconstruction if no quantization is performed. Furthermore, many traditional image and video coders apply dynamic block partitioning to vary the compression of certain image regions depending on their content. Inspired by this approach, hierarchical latent spaces have been applied to learning-based compression networks. In this paper, we present a novel concept, which adapts the hierarchical latent space for augmented normalizing flows, an invertible latent variable model. Our best performing model achieved average rate savings of more than 7% over comparable single-scale models.
The Bjøntegaard Bible -- Why your Way of Comparing Video Codecs May Be Wrong
Apr 25, 2023



In this paper, we provide an in-depth assessment on the Bj{\o}ntegaard Delta. We construct a large data set of video compression performance comparisons using a diverse set of metrics including PSNR, VMAF, bitrate, and processing energies. These metrics are evaluated for visual data types such as classic perspective video, 360{\deg} video, point clouds, and screen content. As compression technology, we consider multiple hybrid video codecs as well as state-of-the-art neural network based compression methods. Using additional performance points inbetween standard points defined by parameters such as the quantization parameter, we assess the interpolation error of the Bj{\o}ntegaard-Delta (BD) calculus and its impact on the final BD value. Performing an in-depth analysis, we find that the BD calculus is most accurate in the standard application of rate-distortion comparisons with mean errors below 0.5 percentage points. For other applications, the errors are higher (up to 10 percentage points), but can be reduced by a higher number of performance points. We finally come up with recommendations on how to use the BD calculus such that the validity of the resulting BD-values is maximized. Main recommendations include the use of Akima interpolation, the interpretation of relative difference curves, and the use of the logarithmic domain for saturating metrics such as SSIM and VMAF.