 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiscale Augmented Normalizing Flows for Image Compression
Paper and Code
May 09, 2023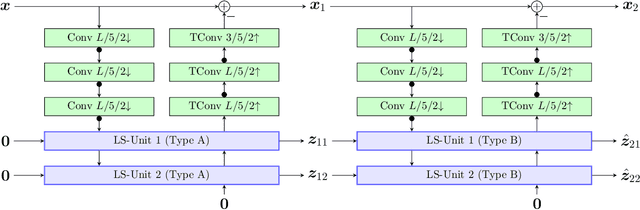
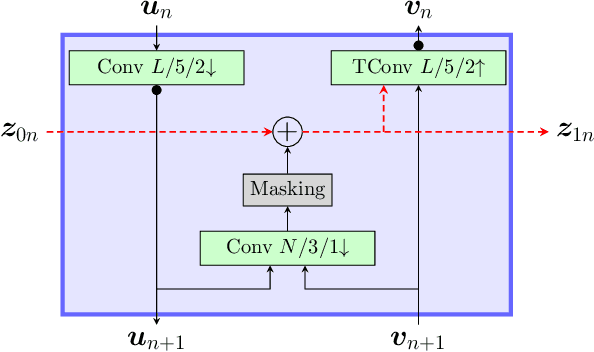
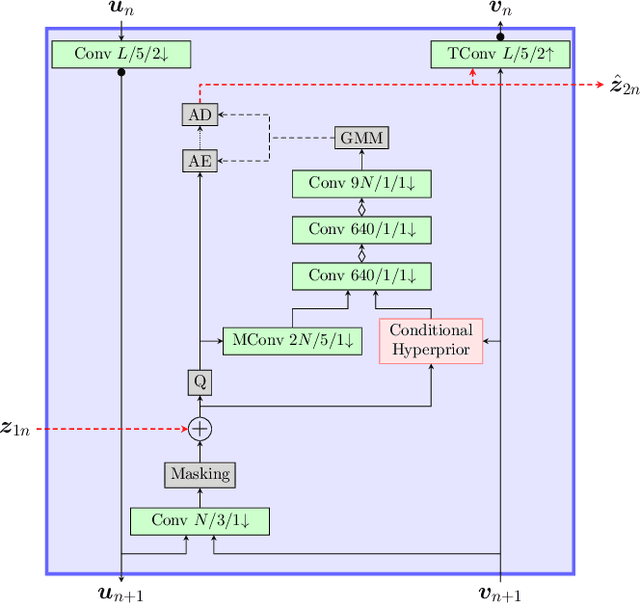
Most learning-based image compression methods lack efficiency for high image quality due to their non-invertible design. The decoding function of the frequently applied compressive autoencoder architecture is only an approximated inverse of the encoding transform. This issue can be resolved by using invertible latent variable models, which allow a perfect reconstruction if no quantization is performed. Furthermore, many traditional image and video coders apply dynamic block partitioning to vary the compression of certain image regions depending on their content. Inspired by this approach, hierarchical latent spaces have been applied to learning-based compression networks. In this paper, we present a novel concept, which adapts the hierarchical latent space for augmented normalizing flows, an invertible latent variable model. Our best performing model achieved average rate savings of more than 7% over comparable single-scale models.