 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLRC-DHVC: Towards Local Rate Control in Neural Video Compression
Jan 20, 2026Local rate control is a key enabler to generalize image and video compression for dedicated challenges, such as video coding for machines. While traditional hybrid video coding can easily adapt the local rate-distortion trade-off by changing the local quantization parameter, no such approach is currently available for learning-based video compression. In this paper, we propose LRC-DHVC, a hierarchical video compression network, which allows continuous local rate control on a pixel level to vary the spatial quality distribution within individual video frames. This is achieved by concatenating a quality map to the input frame and applying a weighted MSE loss which matches the pixelwise trade-off factors in the quality map. During training, the model sees a variety of quality maps due to a constrained-random generation. Our model is the first neural video compression network, which can continuously and spatially adapt to varying quality constraints. Due to the wide quality and bit rate range, a single set of network parameters is sufficient. Compared to single rate point networks, which scale linearly with the number of rate points, the memory requirements for our network parameters remain constant. The code and model are available at link-updated-upon-acceptance.
On Annotation-free Optimization of Video Coding for Machines
Jun 12, 2024
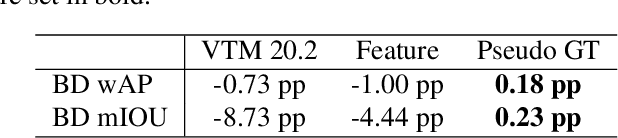
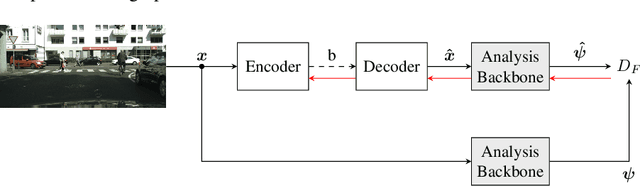
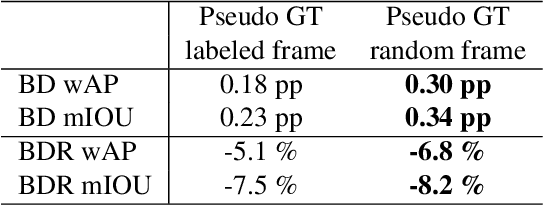
Today, image and video data is not only viewed by humans, but also automatically analyzed by computer vision algorithms. However, current coding standards are optimized for human perception. Emerging from this, research on video coding for machines tries to develop coding methods designed for machines as information sink. Since many of these algorithms are based on neural networks, most proposals for video coding for machines build upon neural compression. So far, optimizing the compression by applying the task loss of the analysis network, for which ground truth data is needed, is achieving the best coding performance. But ground truth data is difficult to obtain and thus an optimization without ground truth is preferred. In this paper, we present an annotation-free optimization strategy for video coding for machines. We measure the distortion by calculating the task loss of the analysis network. Therefore, the predictions on the compressed image are compared with the predictions on the original image, instead of the ground truth data. Our results show that this strategy can even outperform training with ground truth data with rate savings of up to 7.5 %. By using the non-annotated training data, the rate gains can be further increased up to 8.2 %.
Multiscale Augmented Normalizing Flows for Image Compression
May 09, 2023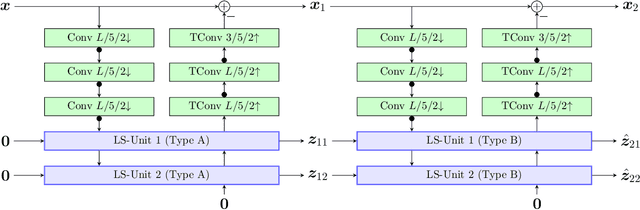
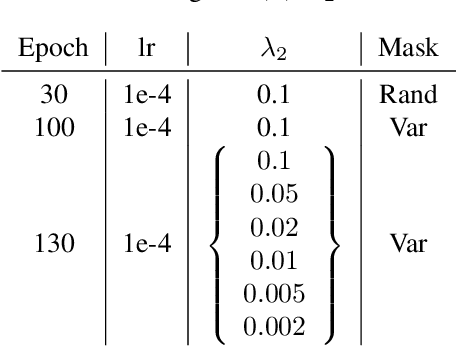
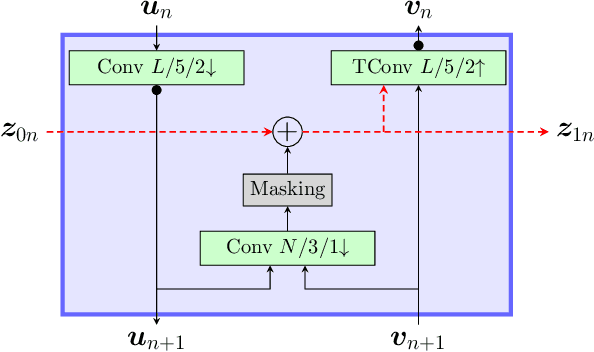
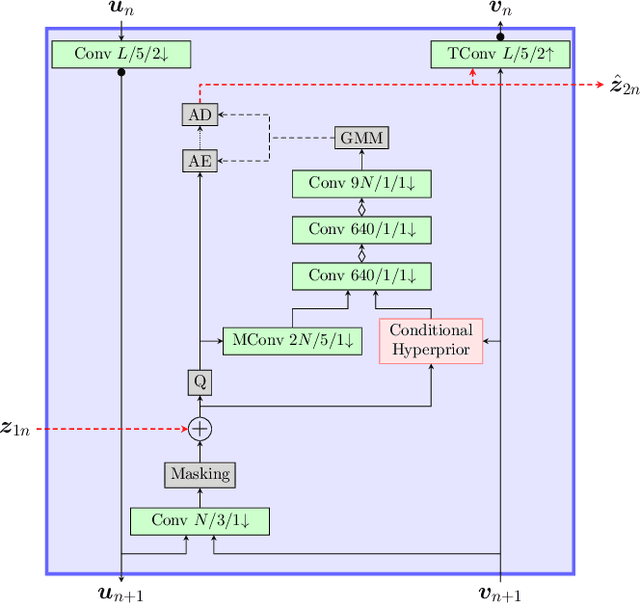
Most learning-based image compression methods lack efficiency for high image quality due to their non-invertible design. The decoding function of the frequently applied compressive autoencoder architecture is only an approximated inverse of the encoding transform. This issue can be resolved by using invertible latent variable models, which allow a perfect reconstruction if no quantization is performed. Furthermore, many traditional image and video coders apply dynamic block partitioning to vary the compression of certain image regions depending on their content. Inspired by this approach, hierarchical latent spaces have been applied to learning-based compression networks. In this paper, we present a novel concept, which adapts the hierarchical latent space for augmented normalizing flows, an invertible latent variable model. Our best performing model achieved average rate savings of more than 7% over comparable single-scale models.