 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Annotation-free Optimization of Video Coding for Machines
Paper and Code

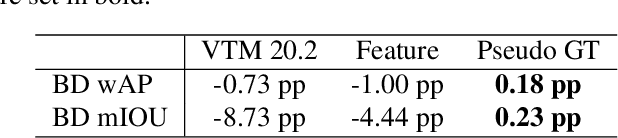
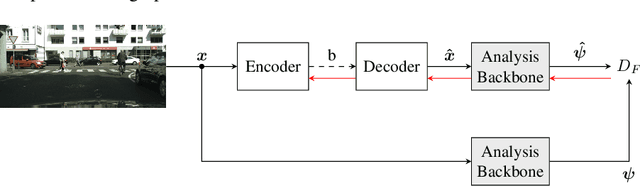
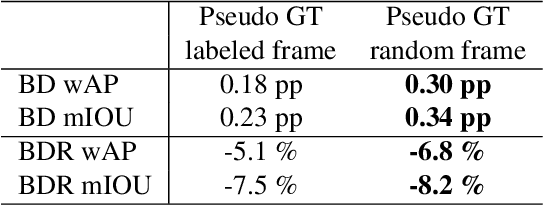
Today, image and video data is not only viewed by humans, but also automatically analyzed by computer vision algorithms. However, current coding standards are optimized for human perception. Emerging from this, research on video coding for machines tries to develop coding methods designed for machines as information sink. Since many of these algorithms are based on neural networks, most proposals for video coding for machines build upon neural compression. So far, optimizing the compression by applying the task loss of the analysis network, for which ground truth data is needed, is achieving the best coding performance. But ground truth data is difficult to obtain and thus an optimization without ground truth is preferred. In this paper, we present an annotation-free optimization strategy for video coding for machines. We measure the distortion by calculating the task loss of the analysis network. Therefore, the predictions on the compressed image are compared with the predictions on the original image, instead of the ground truth data. Our results show that this strategy can even outperform training with ground truth data with rate savings of up to 7.5 %. By using the non-annotated training data, the rate gains can be further increased up to 8.2 %.