 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Versatile Video Coding at UHD with Machine-Learning-Based Super-Resolution
Aug 12, 2023Coding 4K data has become of vital interest in recent years, since the amount of 4K data is significantly increasing. We propose a coding chain with spatial down- and upscaling that combines the next-generation VVC codec with machine learning based single image super-resolution algorithms for 4K. The investigated coding chain, which spatially downscales the 4K data before coding, shows superior quality than the conventional VVC reference software for low bitrate scenarios. Throughout several tests, we find that up to 12 % and 18 % Bjontegaard delta rate gains can be achieved on average when coding 4K sequences with VVC and QP values above 34 and 42, respectively. Additionally, the investigated scenario with up- and downscaling helps to reduce the loss of details and compression artifacts, as it is shown in a visual example.
Spatially-Adaptive Learning-Based Image Compression with Hierarchical Multi-Scale Latent Spaces
Jul 12, 2023



Adaptive block partitioning is responsible for large gains in current image and video compression systems. This method is able to compress large stationary image areas with only a few symbols, while maintaining a high level of quality in more detailed areas. Current state-of-the-art neural-network-based image compression systems however use only one scale to transmit the latent space. In previous publications, we proposed RDONet, a scheme to transmit the latent space in multiple spatial resolutions. Following this principle, we extend a state-of-the-art compression network by a second hierarchical latent-space level to enable multi-scale processing. We extend the existing rate variability capabilities of RDONet by a gain unit. With that we are able to outperform an equivalent traditional autoencoder by 7% rate savings. Furthermore, we show that even though we add an additional latent space, the complexity only increases marginally and the decoding time can potentially even be decreased.
The Bjøntegaard Bible -- Why your Way of Comparing Video Codecs May Be Wrong
Apr 25, 2023



In this paper, we provide an in-depth assessment on the Bj{\o}ntegaard Delta. We construct a large data set of video compression performance comparisons using a diverse set of metrics including PSNR, VMAF, bitrate, and processing energies. These metrics are evaluated for visual data types such as classic perspective video, 360{\deg} video, point clouds, and screen content. As compression technology, we consider multiple hybrid video codecs as well as state-of-the-art neural network based compression methods. Using additional performance points inbetween standard points defined by parameters such as the quantization parameter, we assess the interpolation error of the Bj{\o}ntegaard-Delta (BD) calculus and its impact on the final BD value. Performing an in-depth analysis, we find that the BD calculus is most accurate in the standard application of rate-distortion comparisons with mean errors below 0.5 percentage points. For other applications, the errors are higher (up to 10 percentage points), but can be reduced by a higher number of performance points. We finally come up with recommendations on how to use the BD calculus such that the validity of the resulting BD-values is maximized. Main recommendations include the use of Akima interpolation, the interpretation of relative difference curves, and the use of the logarithmic domain for saturating metrics such as SSIM and VMAF.
Saliency-Driven Hierarchical Learned Image Coding for Machines
Feb 27, 2023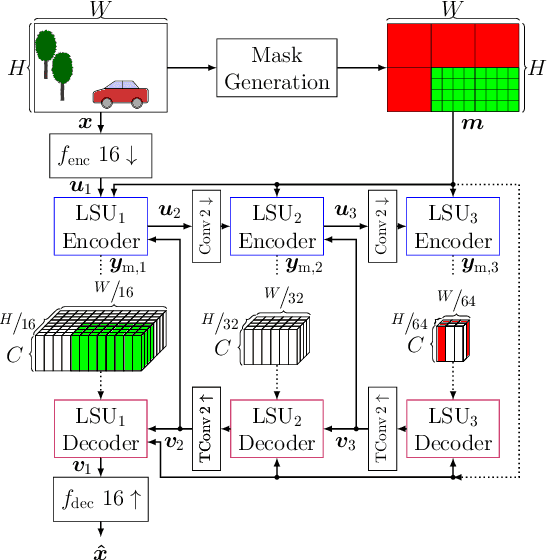



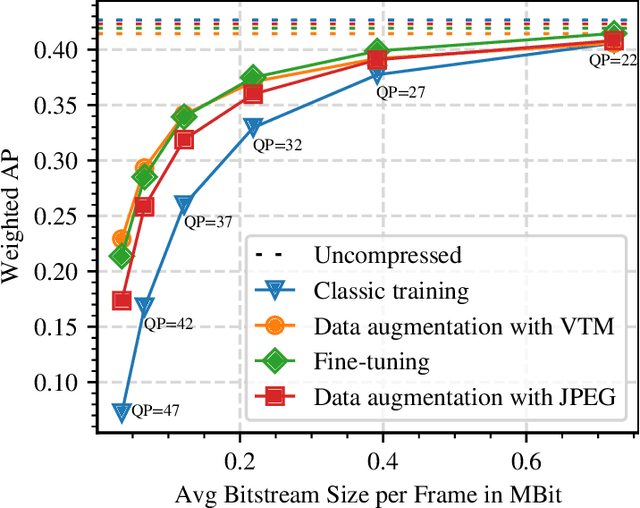
We propose to employ a saliency-driven hierarchical neural image compression network for a machine-to-machine communication scenario following the compress-then-analyze paradigm. By that, different areas of the image are coded at different qualities depending on whether salient objects are located in the corresponding area. Areas without saliency are transmitted in latent spaces of lower spatial resolution in order to reduce the bitrate. The saliency information is explicitly derived from the detections of an object detection network. Furthermore, we propose to add saliency information to the training process in order to further specialize the different latent spaces. All in all, our hierarchical model with all proposed optimizations achieves 77.1 % bitrate savings over the latest video coding standard VVC on the Cityscapes dataset and with Mask R-CNN as analysis network at the decoder side. Thereby, it also outperforms traditional, non-hierarchical compression networks.
Learning Frequency-Specific Quantization Scaling in VVC for Standard-Compliant Task-driven Image Coding
Jan 20, 2023Today, visual data is often analyzed by a neural network without any human being involved, which demands for specialized codecs. For standard-compliant codec adaptations towards certain information sinks, HEVC or VVC provide the possibility of frequency-specific quantization with scaling lists. This is a well-known method for the human visual system, where scaling lists are derived from psycho-visual models. In this work, we employ scaling lists when performing VVC intra coding for neural networks as information sink. To this end, we propose a novel data-driven method to obtain optimal scaling lists for arbitrary neural networks. Experiments with Mask R-CNN as information sink reveal that coding the Cityscapes dataset with the proposed scaling lists result in peak bitrate savings of 8.9 % over VVC with constant quantization. By that, our approach also outperforms scaling lists optimized for the human visual system. The generated scaling lists can be found under https://github.com/FAU-LMS/VCM_scaling_lists.
* Originally submitted at IEEE ICIP 2022
Evaluation of Video Coding for Machines without Ground Truth
May 13, 2022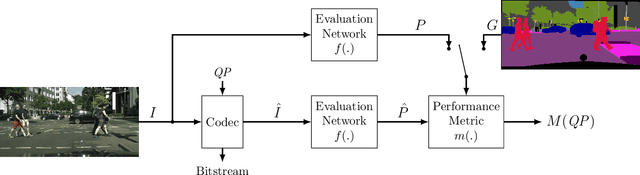



In the emerging field of video coding for machines, video datasets with pristine video quality and high-quality annotations are required for a comprehensive evaluation. However, existing video datasets with detailed annotations are severely limited in size and video quality. Thus, current methods have to either evaluate their codecs on still images or on already compressed data. To mitigate this problem, we propose an evaluation method based on pseudo ground-truth data from the field of semantic segmentation to the evaluation of video coding for machines. Through extensive evaluation, this paper shows that the proposed ground-truth-agnostic evaluation method results in an acceptable absolute measurement error below 0.7 percentage points on the Bjontegaard Delta Rate compared to using the true ground truth for mid-range bitrates. We evaluate on the three tasks of semantic segmentation, instance segmentation, and object detection. Lastly, we utilize the ground-truth-agnostic method to measure the coding performances of the VVC compared against HEVC on the Cityscapes sequences. This reveals that the coding position has a significant influence on the task performance.
* Originally submitted at IEEE ICASSP 2022
Analysis of Neural Image Compression Networks for Machine-to-Machine Communication
May 13, 2022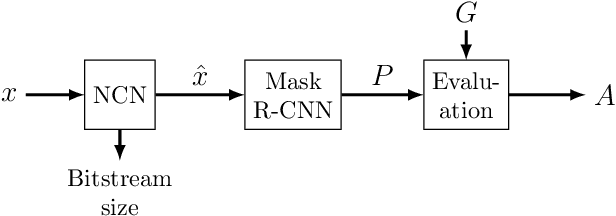

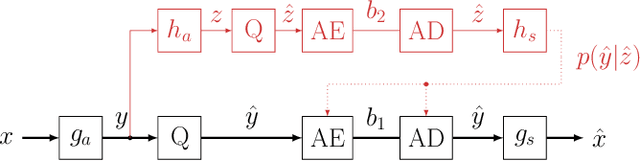
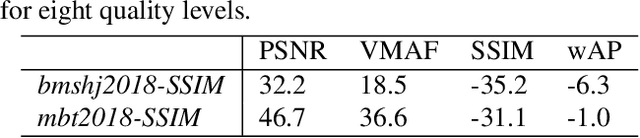
Video and image coding for machines (VCM) is an emerging field that aims to develop compression methods resulting in optimal bitstreams when the decoded frames are analyzed by a neural network. Several approaches already exist improving classic hybrid codecs for this task. However, neural compression networks (NCNs) have made an enormous progress in coding images over the last years. Thus, it is reasonable to consider such NCNs, when the information sink at the decoder side is a neural network as well. Therefore, we build-up an evaluation framework analyzing the performance of four state-of-the-art NCNs, when a Mask R-CNN is segmenting objects from the decoded image. The compression performance is measured by the weighted average precision for the Cityscapes dataset. Based on that analysis, we find that networks with leaky ReLU as non-linearity and training with SSIM as distortion criteria results in the highest coding gains for the VCM task. Furthermore, it is shown that the GAN-based NCN architecture achieves the best coding performance and even out-performs the recently standardized Versatile Video Coding (VVC) for the given scenario.
* Originally submitted at IEEE ICIP 2021
Robust Deep Neural Object Detection and Segmentation for Automotive Driving Scenario with Compressed Image Data
May 13, 2022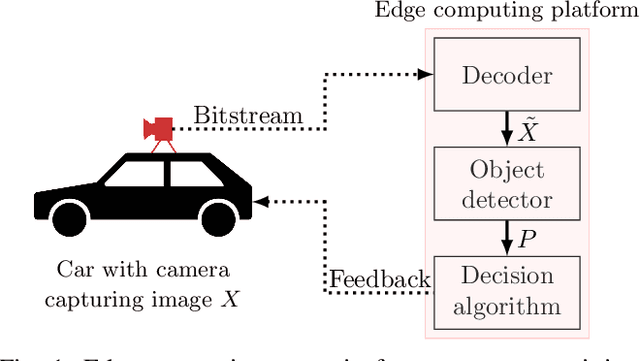


Deep neural object detection or segmentation networks are commonly trained with pristine, uncompressed data. However, in practical applications the input images are usually deteriorated by compression that is applied to efficiently transmit the data. Thus, we propose to add deteriorated images to the training process in order to increase the robustness of the two state-of-the-art networks Faster and Mask R-CNN. Throughout our paper, we investigate an autonomous driving scenario by evaluating the newly trained models on the Cityscapes dataset that has been compressed with the upcoming video coding standard Versatile Video Coding (VVC). When employing the models that have been trained with the proposed method, the weighted average precision of the R-CNNs can be increased by up to 3.68 percentage points for compressed input images, which corresponds to bitrate savings of nearly 48 %.
* Originally submitted at IEEE ISCAS 2021
Saliency-Driven Versatile Video Coding for Neural Object Detection
Mar 11, 2022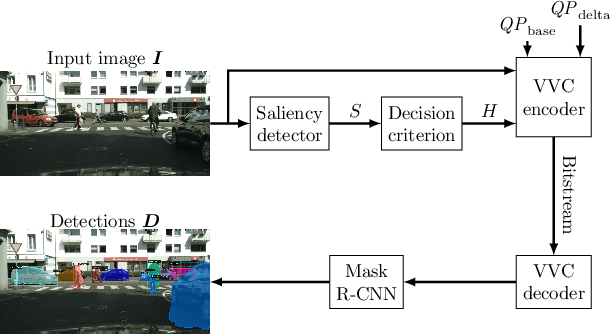
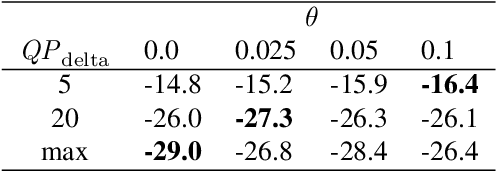

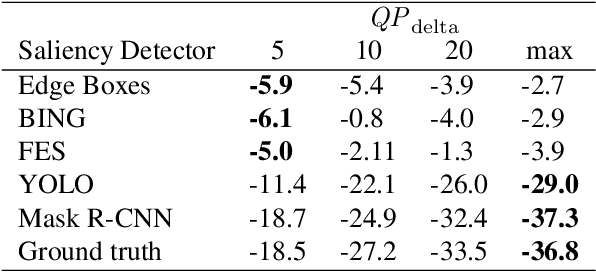
Saliency-driven image and video coding for humans has gained importance in the recent past. In this paper, we propose such a saliency-driven coding framework for the video coding for machines task using the latest video coding standard Versatile Video Coding (VVC). To determine the salient regions before encoding, we employ the real-time-capable object detection network You Only Look Once~(YOLO) in combination with a novel decision criterion. To measure the coding quality for a machine, the state-of-the-art object segmentation network Mask R-CNN was applied to the decoded frame. From extensive simulations we find that, compared to the reference VVC with a constant quality, up to 29 % of bitrate can be saved with the same detection accuracy at the decoder side by applying the proposed saliency-driven framework. Besides, we compare YOLO against other, more traditional saliency detection methods.
* 5 pages, 3 figures, 2 tables; Originally submitted at IEEE ICASSP 2021
On Intra Video Coding and In-loop Filtering for Neural Object Detection Networks
Mar 11, 2022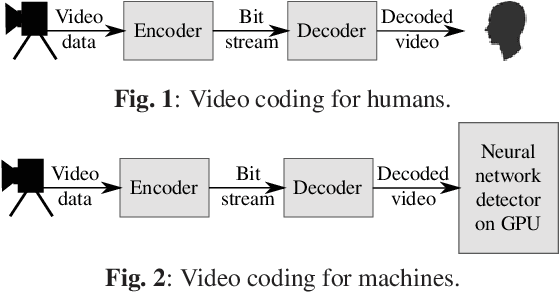
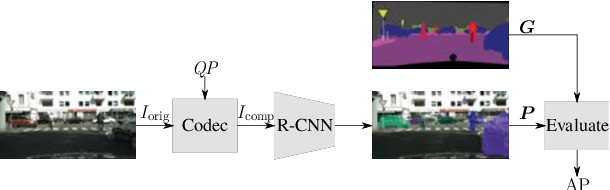


Classical video coding for satisfying humans as the final user is a widely investigated field of studies for visual content, and common video codecs are all optimized for the human visual system (HVS). But are the assumptions and optimizations also valid when the compressed video stream is analyzed by a machine? To answer this question, we compared the performance of two state-of-the-art neural detection networks when being fed with deteriorated input images coded with HEVC and VVC in an autonomous driving scenario using intra coding. Additionally, the impact of the three VVC in-loop filters when coding images for a neural network is examined. The results are compared using the mean average precision metric to evaluate the object detection performance for the compressed inputs. Throughout these tests, we found that the Bj{\o}ntegaard Delta Rate savings with respect to PSNR of 22.2 % using VVC instead of HEVC cannot be reached when coding for object detection networks with only 13.6% in the best case. Besides, it is shown that disabling the VVC in-loop filters SAO and ALF results in bitrate savings of 6.4 % compared to the standard VTM at the same mean average precision.
* 5 pages, 6 figures, 2 tables; Originally published at IEEE ICIP 2020