 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency-Driven Versatile Video Coding for Neural Object Detection
Mar 11, 2022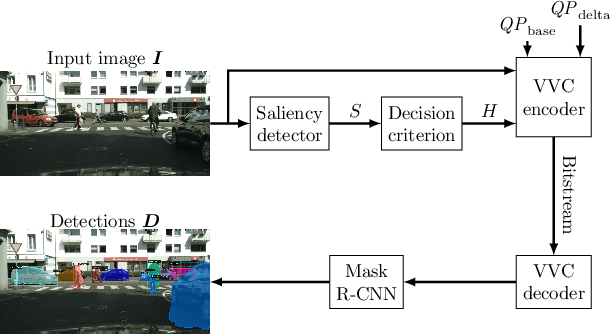
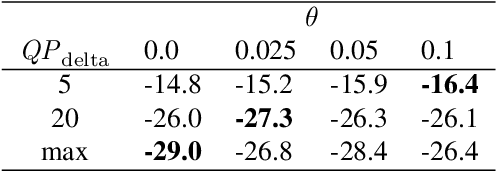

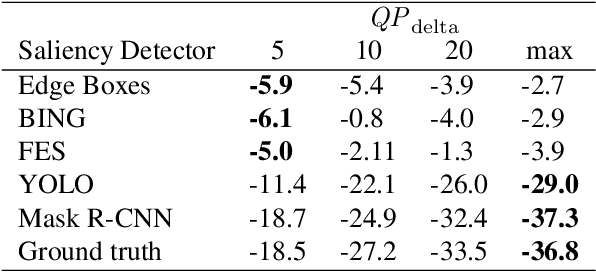
Saliency-driven image and video coding for humans has gained importance in the recent past. In this paper, we propose such a saliency-driven coding framework for the video coding for machines task using the latest video coding standard Versatile Video Coding (VVC). To determine the salient regions before encoding, we employ the real-time-capable object detection network You Only Look Once~(YOLO) in combination with a novel decision criterion. To measure the coding quality for a machine, the state-of-the-art object segmentation network Mask R-CNN was applied to the decoded frame. From extensive simulations we find that, compared to the reference VVC with a constant quality, up to 29 % of bitrate can be saved with the same detection accuracy at the decoder side by applying the proposed saliency-driven framework. Besides, we compare YOLO against other, more traditional saliency detection methods.
* 5 pages, 3 figures, 2 tables; Originally submitted at IEEE ICASSP 2021