 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency-Driven Hierarchical Learned Image Coding for Machines
Paper and Code
Feb 27, 2023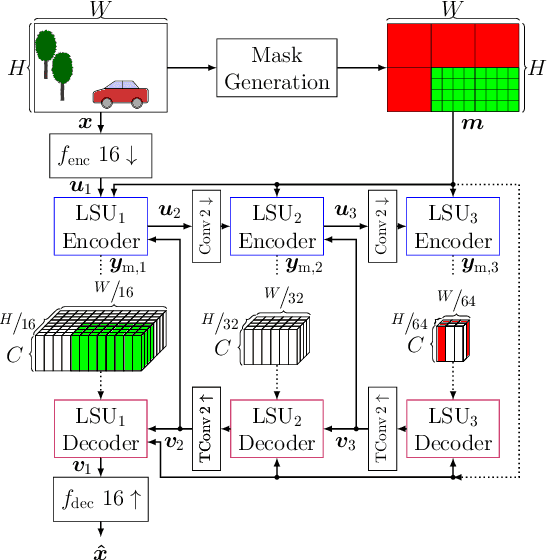



We propose to employ a saliency-driven hierarchical neural image compression network for a machine-to-machine communication scenario following the compress-then-analyze paradigm. By that, different areas of the image are coded at different qualities depending on whether salient objects are located in the corresponding area. Areas without saliency are transmitted in latent spaces of lower spatial resolution in order to reduce the bitrate. The saliency information is explicitly derived from the detections of an object detection network. Furthermore, we propose to add saliency information to the training process in order to further specialize the different latent spaces. All in all, our hierarchical model with all proposed optimizations achieves 77.1 % bitrate savings over the latest video coding standard VVC on the Cityscapes dataset and with Mask R-CNN as analysis network at the decoder side. Thereby, it also outperforms traditional, non-hierarchical compression networks.