 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Deep Neural Object Detection and Segmentation for Automotive Driving Scenario with Compressed Image Data
Paper and Code
May 13, 2022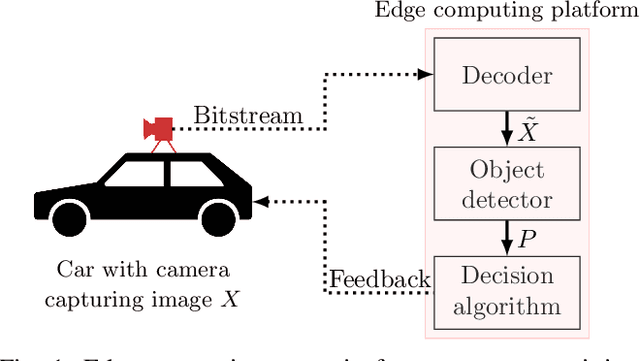
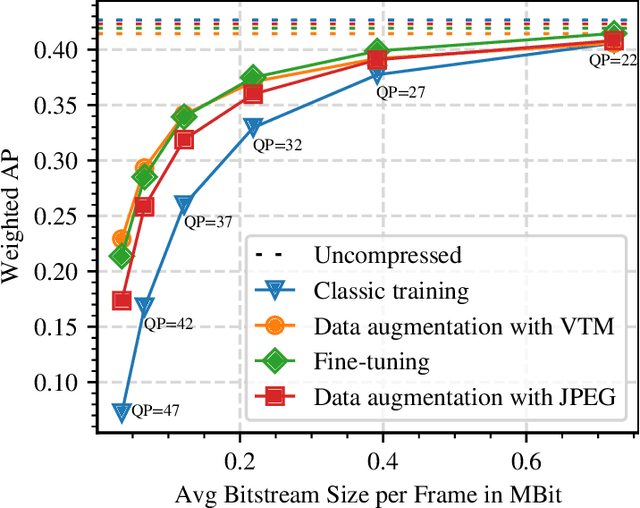


Deep neural object detection or segmentation networks are commonly trained with pristine, uncompressed data. However, in practical applications the input images are usually deteriorated by compression that is applied to efficiently transmit the data. Thus, we propose to add deteriorated images to the training process in order to increase the robustness of the two state-of-the-art networks Faster and Mask R-CNN. Throughout our paper, we investigate an autonomous driving scenario by evaluating the newly trained models on the Cityscapes dataset that has been compressed with the upcoming video coding standard Versatile Video Coding (VVC). When employing the models that have been trained with the proposed method, the weighted average precision of the R-CNNs can be increased by up to 3.68 percentage points for compressed input images, which corresponds to bitrate savings of nearly 48 %.