 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLossless 4:2:0 Screen Content Coding Using Luma-Guided Soft Context Formation
Aug 26, 2025The soft context formation coder is a pixel-wise state-of-the-art lossless screen content coder using pattern matching and color palette coding in combination with arithmetic coding. It achieves excellent compression performance on screen content images in RGB 4:4:4 format with few distinct colors. In contrast to many other lossless compression methods, it codes entire color pixels at once, i.e., all color components of one pixel are coded together. Consequently, it does not natively support image formats with downsampled chroma, such as YCbCr 4:2:0, which is an often used chroma format in video compression. In this paper, we extend the soft context formation coding capabilities to 4:2:0 image compression, by successively coding Y and CbCr planes based on an analysis of normalized mutual information between image planes. Additionally, we propose an enhancement to the chroma prediction based on the luminance plane. Furthermore, we propose to transmit side-information about occurring luma-chroma combinations to improve chroma probability distribution modelling. Averaged over a large screen content image dataset, our proposed method outperforms HEVC-SCC, with HEVC-SCC needing 5.66% more bitrate compared to our method.
Enhanced Color Palette Modeling for Lossless Screen Content Compression
Jan 09, 2024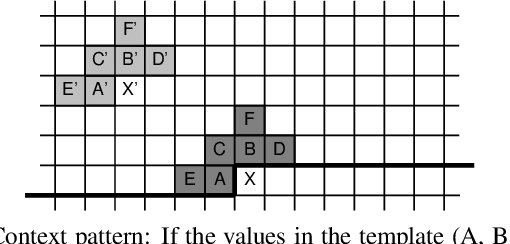
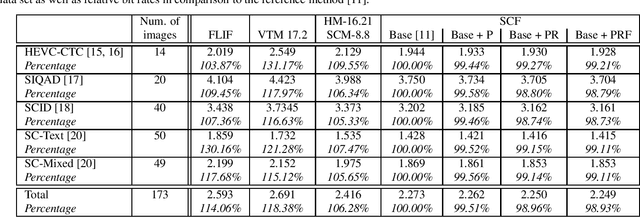
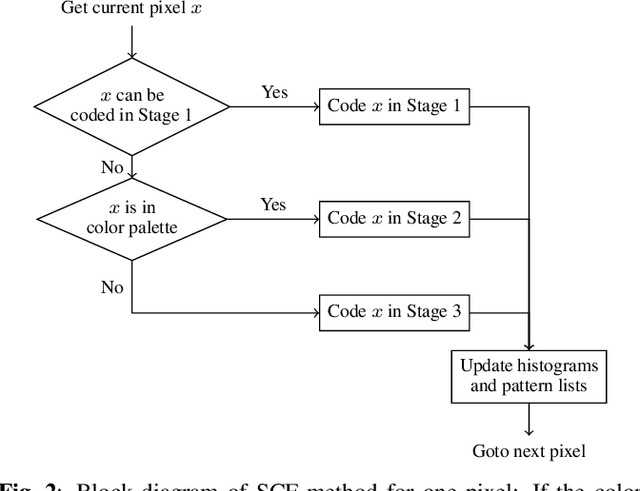
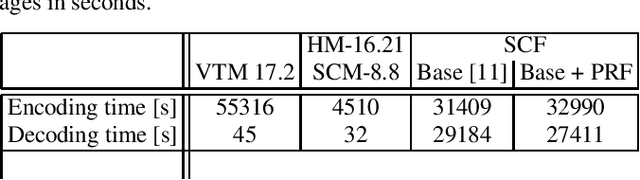
Soft context formation is a lossless image coding method for screen content. It encodes images pixel by pixel via arithmetic coding by collecting statistics for probability distribution estimation. Its main pipeline includes three stages, namely a context model based stage, a color palette stage and a residual coding stage. Each subsequent stage is only employed if the previous stage can not be applied since necessary statistics, e.g. colors or contexts, have not been learned yet. We propose the following enhancements: First, information from previous stages is used to remove redundant color palette entries and prediction errors in subsequent stages. Additionally, implicitly known stage decision signals are no longer explicitly transmitted. These enhancements lead to an average bit rate decrease of 1.07% on the evaluated data. Compared to VVC and HEVC, the proposed method needs roughly 0.44 and 0.17 bits per pixel less on average for 24-bit screen content images, respectively.
Color Agnostic Cross-Spectral Disparity Estimation
Dec 14, 2023Since camera modules become more and more affordable, multispectral camera arrays have found their way from special applications to the mass market, e.g., in automotive systems, smartphones, or drones. Due to multiple modalities, the registration of different viewpoints and the required cross-spectral disparity estimation is up to the present extremely challenging. To overcome this problem, we introduce a novel spectral image synthesis in combination with a color agnostic transform. Thus, any recently published stereo matching network can be turned to a cross-spectral disparity estimator. Our novel algorithm requires only RGB stereo data to train a cross-spectral disparity estimator and a generalization from artificial training data to camera-captured images is obtained. The theoretical examination of the novel color agnostic method is completed by an extensive evaluation compared to state of the art including self-recorded multispectral data and a reference implementation. The novel color agnostic disparity estimation improves cross-spectral as well as conventional color stereo matching by reducing the average end-point error by 41% for cross-spectral and by 22% for mono-modal content, respectively.
Image Segmentation For Improved Lossless Screen Content Compression
May 10, 2023



In recent years, it has been found that screen content images (SCI) can be effectively compressed based on appropriate probability modelling and suitable entropy coding methods such as arithmetic coding. The key objective is determining the best probability distribution for each pixel position. This strategy works particularly well for images with synthetic (textual) content. However, usually screen content images not only consist of synthetic but also pictorial (natural) regions. These images require diverse models of probability distributions to be optimally compressed. One way to achieve this goal is to separate synthetic and natural regions. This paper proposes a segmentation method that identifies natural regions enabling better adaptive treatment. It supplements a compression method known as Soft Context Formation (SCF) and operates as a pre-processing step. If at least one natural segment is found within the SCI, it is split into two sub images (natural and synthetic parts), and the process of modelling and coding is performed separately for both. For SCIs with natural regions, the proposed method achieves a bit-rate reduction of up to 11.6% and 1.52% with respect to HEVC and the previous version of the SCF.
Improved Screen Content Coding in VVC Using Soft Context Formation
May 09, 2023Screen content images (SCIs) often contain a mix of natural and synthetic image parts. Synthetic sections usually are comprised of uniformly colored areas as well as repeating colors and patterns. In the Versatile Video Coding (VVC) standard, these properties are largely exploited using Intra Block Copy and Palette Mode. However, the Soft Context Formation (SCF) coder, a pixel-wise lossless coder for SCIs based on pattern matching and entropy coding, outperforms the VVC in very synthetic image areas even when compared to the lossy VVC. In this paper, we propose an enhanced VVC coding approach for SCIs using Soft Context Formation. First, the image is separated into two distinct layers in a block-wise manner using a learning-based method with 4 block features. Highly synthetic image parts are coded losslessly using the SCF coder, whereas the rest of the image is coded using VVC. The SCF coder is further modified to incorporate information gained by the decoded VVC layer when encoding the SCF layer. Using this approach, we achieve BD-rate gains of 4.15% on average on the evaluated data sets when compared to VVC.
The Bjøntegaard Bible -- Why your Way of Comparing Video Codecs May Be Wrong
Apr 25, 2023



In this paper, we provide an in-depth assessment on the Bj{\o}ntegaard Delta. We construct a large data set of video compression performance comparisons using a diverse set of metrics including PSNR, VMAF, bitrate, and processing energies. These metrics are evaluated for visual data types such as classic perspective video, 360{\deg} video, point clouds, and screen content. As compression technology, we consider multiple hybrid video codecs as well as state-of-the-art neural network based compression methods. Using additional performance points inbetween standard points defined by parameters such as the quantization parameter, we assess the interpolation error of the Bj{\o}ntegaard-Delta (BD) calculus and its impact on the final BD value. Performing an in-depth analysis, we find that the BD calculus is most accurate in the standard application of rate-distortion comparisons with mean errors below 0.5 percentage points. For other applications, the errors are higher (up to 10 percentage points), but can be reduced by a higher number of performance points. We finally come up with recommendations on how to use the BD calculus such that the validity of the resulting BD-values is maximized. Main recommendations include the use of Akima interpolation, the interpretation of relative difference curves, and the use of the logarithmic domain for saturating metrics such as SSIM and VMAF.
Optimization of Probability Distributions for Residual Coding of Screen Content
Dec 02, 2022



Probability distribution modeling is the basis for most competitive methods for lossless coding of screen content. One such state-of-the-art method is known as soft context formation (SCF). For each pixel to be encoded, a probability distribution is estimated based on the neighboring pattern and the occurrence of that pattern in the already encoded image. Using an arithmetic coder, the pixel color can thus be encoded very efficiently, provided that the current color has been observed before in association with a similar pattern. If this is not the case, the color is instead encoded using a color palette or, if it is still unknown, via residual coding. Both palette-based coding and residual coding have significantly worse compression efficiency than coding based on soft context formation. In this paper, the residual coding stage is improved by adaptively trimming the probability distributions for the residual error. Furthermore, an enhanced probability modeling for indicating a new color depending on the occurrence of new colors in the neighborhood is proposed. These modifications result in a bitrate reduction of up to 2.9% on average. Compared to HEVC (HM-16.21 + SCM-8.8) and FLIF, the improved SCF method saves on average about 11% and 18% rate, respectively.