 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColor Agnostic Cross-Spectral Disparity Estimation
Dec 14, 2023Since camera modules become more and more affordable, multispectral camera arrays have found their way from special applications to the mass market, e.g., in automotive systems, smartphones, or drones. Due to multiple modalities, the registration of different viewpoints and the required cross-spectral disparity estimation is up to the present extremely challenging. To overcome this problem, we introduce a novel spectral image synthesis in combination with a color agnostic transform. Thus, any recently published stereo matching network can be turned to a cross-spectral disparity estimator. Our novel algorithm requires only RGB stereo data to train a cross-spectral disparity estimator and a generalization from artificial training data to camera-captured images is obtained. The theoretical examination of the novel color agnostic method is completed by an extensive evaluation compared to state of the art including self-recorded multispectral data and a reference implementation. The novel color agnostic disparity estimation improves cross-spectral as well as conventional color stereo matching by reducing the average end-point error by 41% for cross-spectral and by 22% for mono-modal content, respectively.
RGB-Guided Resolution Enhancement of IR Images
Sep 12, 2023



This paper introduces a novel method for RGB-Guided Resolution Enhancement of infrared (IR) images called Guided IR Resolution Enhancement (GIRRE). In the area of single image super resolution (SISR) there exists a wide variety of algorithms like interpolation methods or neural networks to improve the spatial resolution of images. In contrast to SISR, even more information can be gathered on the recorded scene when using multiple cameras. In our setup, we are dealing with multi image super resolution, especially with stereo super resolution. We consider a color camera and an IR camera. Current IR sensors have a very low resolution compared to color sensors so that recent color sensors take up 100 times more pixels than IR sensors. To this end, GIRRE increases the spatial resolution of the low-resolution IR image. After that, the upscaled image is filtered with the aid of the high-resolution color image. We show that our method achieves an average PSNR gain of 1.2 dB and at best up to 1.8 dB compared to state-of-the-art methods, which is visually noticeable.
Multispectral Image Compression Based on HEVC Using Pel-Recursive Inter-Band Prediction
Mar 09, 2023Recent developments in optical sensors enable a wide range of applications for multispectral imaging, e.g., in surveillance, optical sorting, and life-science instrumentation. Increasing spatial and spectral resolution allows creating higher quality products, however, it poses challenges in handling such large amounts of data. Consequently, specialized compression techniques for multispectral images are required. High Efficiency Video Coding (HEVC) is known to be the state of the art in efficiency for both video coding and still image coding. In this paper, we propose a cross-spectral compression scheme for efficiently coding multispectral data based on HEVC. Extending intra picture prediction by a novel inter-band predictor, spectral as well as spatial redundancies can be effectively exploited. Dependencies among the current band and further spectral references are considered jointly by adaptive linear regression modeling. The proposed backward prediction scheme does not require additional side information for decoding. We show that our novel approach is able to outperform state-of-the-art lossy compression techniques in terms of rate-distortion performance. On different data sets, average Bj{\o}ntegaard delta rate savings of 82 % and 55 % compared to HEVC and a reference method from literature are achieved, respectively.
* 6 pages, 4 figures, 1 table; Originally published as conference paper at IEEE MMSP 2020
Structure-Preserving Spectral Reflectance Estimation using Guided Filtering
Sep 16, 2022

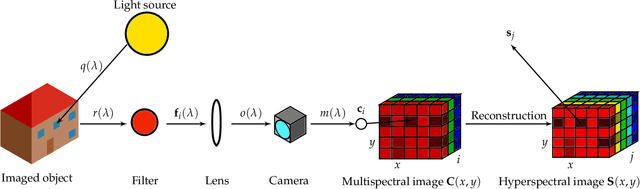
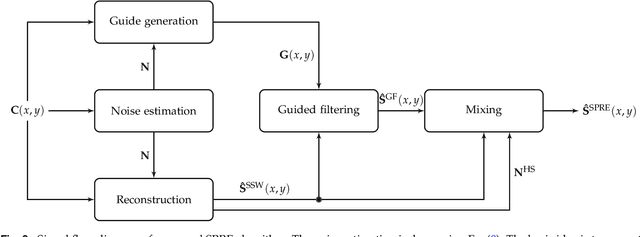
Light spectra are a very important source of information for diverse classification problems, e.g., for discrimination of materials. To lower the cost for acquiring this information, multispectral cameras are used. Several techniques exist for estimating light spectra out of multispectral images by exploiting properties about the spectrum. Unfortunately, especially when capturing multispectral videos, the images are heavily affected by noise due to the nature of limited exposure times in videos. Therefore, models that explicitly try to lower the influence of noise on the reconstructed spectrum are highly desirable. Hence, a novel reconstruction algorithm is presented. This novel estimation method is based on the guided filtering technique which preserves basic structures, while using spatial information to reduce the influence of noise. The evaluation based on spectra of natural images reveals that this new technique yields better quantitative and subjective results in noisy scenarios than other state-of-the-art spatial reconstruction methods. Specifically, the proposed algorithm lowers the mean squared error and the spectral angle up to 46% and 35% in noisy scenarios, respectively. Furthermore, it is shown that the proposed reconstruction technique works out-of-the-box and does not need any calibration or training by reconstructing spectra from a real-world multispectral camera with nine channels.
Rate-Distortion Optimal Transform Coefficient Selection for Unoccupied Regions in Video-Based Point Cloud Compression
Jun 24, 2022

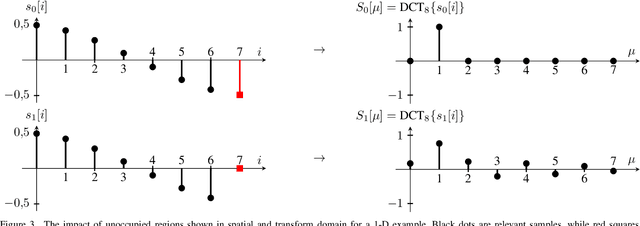
This paper presents a novel method to determine rate-distortion optimized transform coefficients for efficient compression of videos generated from point clouds. The method exploits a generalized frequency selective extrapolation approach that iteratively determines rate-distortion-optimized coefficients for all basis functions of two-dimensional discrete cosine and sine transforms. The method is applied to blocks containing both occupied and unoccupied pixels in video based point cloud compression for HEVC encoding. In the proposed algorithm, only the values of the transform coefficients are changed such that resulting bit streams are compliant to the V-PCC standard. For all-intra coded point clouds, bitrate savings of more than 4% for geometry and more than 6% for texture error metrics with respect to standard encoding can be observed. These savings are more than twice as high as savings obtained using competing methods from literature. In the randomaccess case, our proposed method outperforms competing V-PCC methods by more than 0.5%.
* 14 pages, 9 figures
Key Point Agnostic Frequency-Selective Mesh-to-Grid Image Resampling using Spectral Weighting
Mar 15, 2022
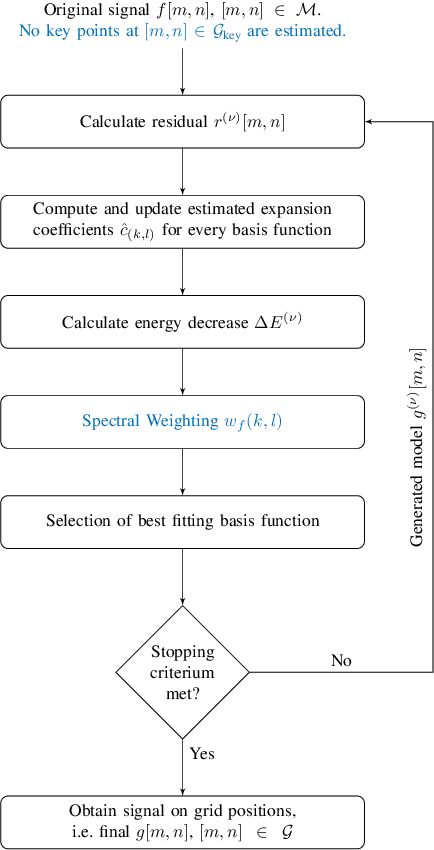
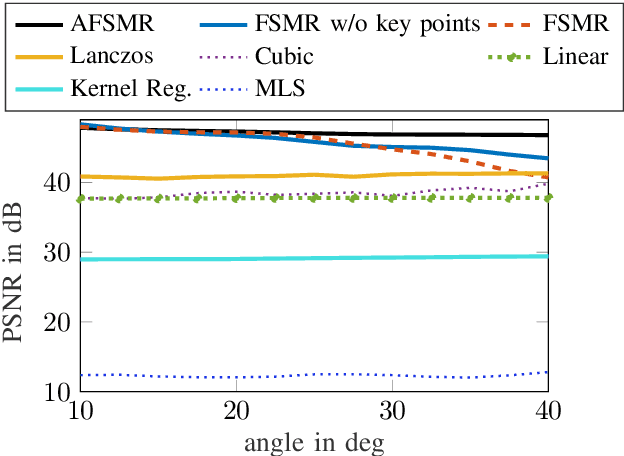

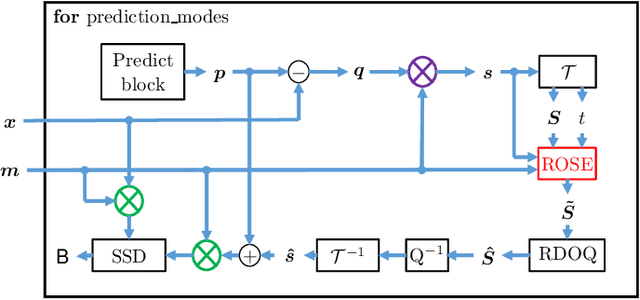
Many applications in image processing require resampling of arbitrarily located samples onto regular grid positions. This is important in frame-rate up-conversion, super-resolution, and image warping among others. A state-of-the-art high quality model-based resampling technique is frequency-selective mesh-to-grid resampling which requires pre-estimation of key points. In this paper, we propose a new key point agnostic frequency-selective mesh-to-grid resampling that does not depend on pre-estimated key points. Hence, the number of data points that are included is reduced drastically and the run time decreases significantly. To compensate for the key points, a spectral weighting function is introduced that models the optical transfer function in order to favor low frequencies more than high ones. Thereby, resampling artefacts like ringing are supressed reliably and the resampling quality increases. On average, the new AFSMR is conceptually simpler and gains up to 1.2 dB in terms of PSNR compared to the original mesh-to-grid resampling while being approximately 14.5 times faster.
* 6 pages, 5 figures; Originally submitted to IEEE MMSP 2020