 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable Rate Learned Wavelet Video Coding with Temporal Layer Adaptivity
Oct 21, 2024



Learned wavelet video coders provide an explainable framework by performing discrete wavelet transforms in temporal, horizontal, and vertical dimensions. With a temporal transform based on motion-compensated temporal filtering (MCTF), spatial and temporal scalability is obtained. In this paper, we introduce variable rate support and a mechanism for quality adaption to different temporal layers for a higher coding efficiency. Moreover, we propose a multi-stage training strategy that allows training with multiple temporal layers. Our experiments demonstrate Bj{\o}ntegaard Delta bitrate savings of at least -17% compared to a learned MCTF model without these extensions. Our method also outperforms other learned video coders like DCVC-DC. Training and inference code is available at: https://github.com/FAU-LMS/Learned-pMCTF.
Efficient Learned Wavelet Image and Video Coding
May 21, 2024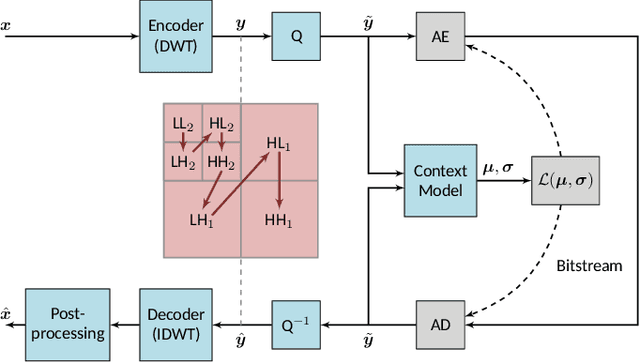
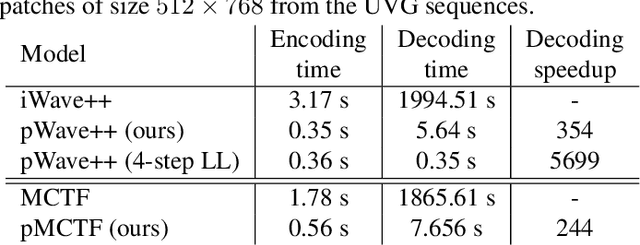
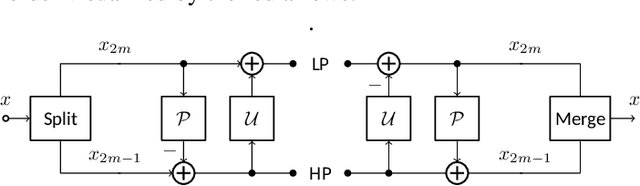
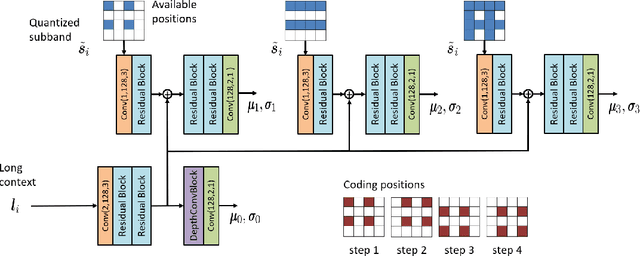
Learned wavelet image and video coding approaches provide an explainable framework with a latent space corresponding to a wavelet decomposition. The wavelet image coder iWave++ achieves state-of-the-art performance and has been employed for various compression tasks, including lossy as well as lossless image, video, and medical data compression. However, the approaches suffer from slow decoding speed due to the autoregressive context model used in iWave++. In this paper, we show how a parallelized context model can be integrated into the iWave++ framework. Our experimental results demonstrate a speedup factor of over 350 and 240 for image and video compression, respectively. At the same time, the rate-distortion performance in terms of Bj{\o}ntegaard delta bitrate is slightly worse by 1.5\% for image coding and 1\% for video coding. In addition, we analyze the learned wavelet decomposition by visualizing its subband impulse responses.
Learned Wavelet Video Coding using Motion Compensated Temporal Filtering
May 25, 2023



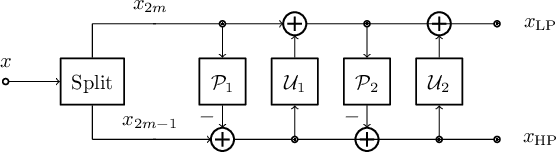
We present an end-to-end trainable wavelet video coder based on motion compensated temporal filtering (MCTF). Thereby, we introduce a different coding scheme for learned video compression, which is currently dominated by residual and conditional coding approaches. By performing discrete wavelet transforms in temporal, horizontal, and vertical dimension, we obtain an explainable framework with spatial and temporal scalability. We focus on investigating a novel trainable MCTF module that is implemented using the lifting scheme. We show how multiple temporal decomposition levels in MCTF can be considered during training and how larger temporal displacements due to the MCTF coding order can be handled. Further, we present a content adaptive extension to MCTF which adapts to different motion strengths during inference. In our experiments, we compare our MCTF-based approach to learning-based conditional coders and traditional hybrid video coding. Especially at high rates, our approach has promising rate-distortion performance. Our method achieves average Bj{\o}ntegaard Delta savings of up to 21% over HEVC on the UVG data set and thereby outperforms state-of-the-art learned video coders.
The Bjøntegaard Bible -- Why your Way of Comparing Video Codecs May Be Wrong
Apr 25, 2023



In this paper, we provide an in-depth assessment on the Bj{\o}ntegaard Delta. We construct a large data set of video compression performance comparisons using a diverse set of metrics including PSNR, VMAF, bitrate, and processing energies. These metrics are evaluated for visual data types such as classic perspective video, 360{\deg} video, point clouds, and screen content. As compression technology, we consider multiple hybrid video codecs as well as state-of-the-art neural network based compression methods. Using additional performance points inbetween standard points defined by parameters such as the quantization parameter, we assess the interpolation error of the Bj{\o}ntegaard-Delta (BD) calculus and its impact on the final BD value. Performing an in-depth analysis, we find that the BD calculus is most accurate in the standard application of rate-distortion comparisons with mean errors below 0.5 percentage points. For other applications, the errors are higher (up to 10 percentage points), but can be reduced by a higher number of performance points. We finally come up with recommendations on how to use the BD calculus such that the validity of the resulting BD-values is maximized. Main recommendations include the use of Akima interpolation, the interpretation of relative difference curves, and the use of the logarithmic domain for saturating metrics such as SSIM and VMAF.
Multispectral Image Compression Based on HEVC Using Pel-Recursive Inter-Band Prediction
Mar 09, 2023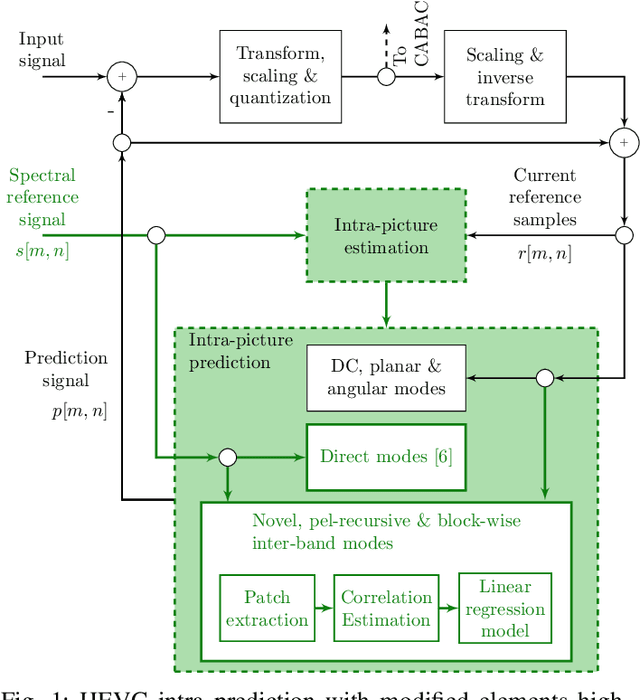
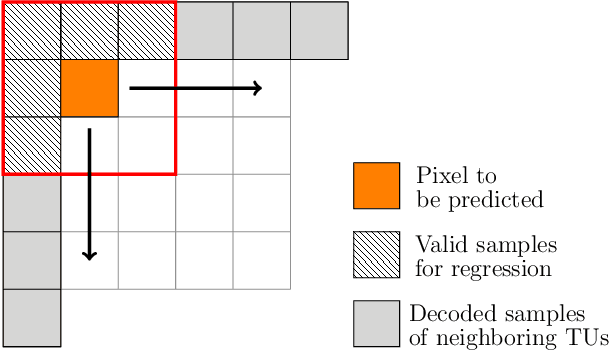
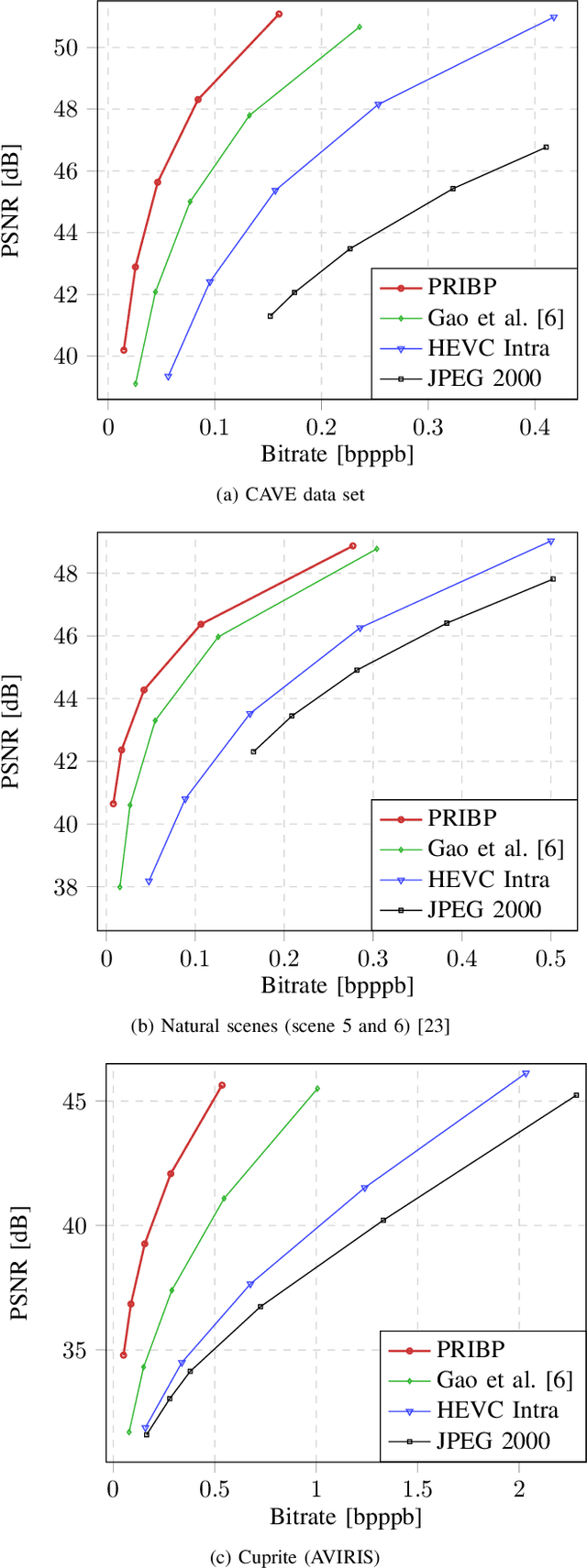

Recent developments in optical sensors enable a wide range of applications for multispectral imaging, e.g., in surveillance, optical sorting, and life-science instrumentation. Increasing spatial and spectral resolution allows creating higher quality products, however, it poses challenges in handling such large amounts of data. Consequently, specialized compression techniques for multispectral images are required. High Efficiency Video Coding (HEVC) is known to be the state of the art in efficiency for both video coding and still image coding. In this paper, we propose a cross-spectral compression scheme for efficiently coding multispectral data based on HEVC. Extending intra picture prediction by a novel inter-band predictor, spectral as well as spatial redundancies can be effectively exploited. Dependencies among the current band and further spectral references are considered jointly by adaptive linear regression modeling. The proposed backward prediction scheme does not require additional side information for decoding. We show that our novel approach is able to outperform state-of-the-art lossy compression techniques in terms of rate-distortion performance. On different data sets, average Bj{\o}ntegaard delta rate savings of 82 % and 55 % compared to HEVC and a reference method from literature are achieved, respectively.
* 6 pages, 4 figures, 1 table; Originally published as conference paper at IEEE MMSP 2020
A novel Cross-Component Context Model for End-to-End Wavelet Image Coding
Mar 09, 2023
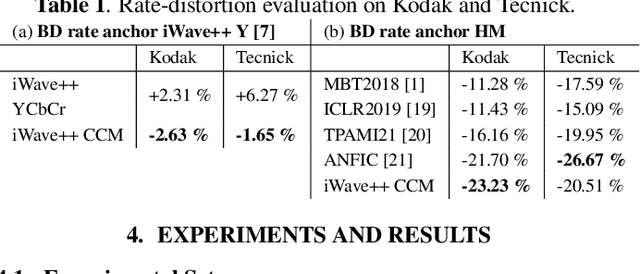
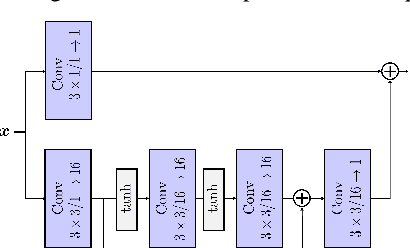
In contrast to traditional compression techniques performing linear transforms, the latent space of popular compressive autoencoders is obtained from a learned nonlinear mapping and hard to interpret. In this paper, we explore a promising alternative approach for neural compression, with an autoencoder whose latent space represents a nonlinear wavelet decomposition. Previous work has shown that neural wavelet image coding can outperform HEVC. However, the approach codes color components independently, thereby ignoring inter-component dependencies. Hence, we propose a novel cross-component context model (CCM). With CCM, the entropy model for the chroma latent space can be conditioned on previously coded components exploiting correlations in the learned wavelet space. The proposed CCM outperforms the baseline model with average Bj{\o}ntegaard delta rate savings of 2.6 % and 1.6 % for the Kodak and Tecnick image sets. Also, our method is competitive with VVC and learning-based methods.
A machine learning based algorithm selection method to solve the minimum cost flow problem
Oct 03, 2022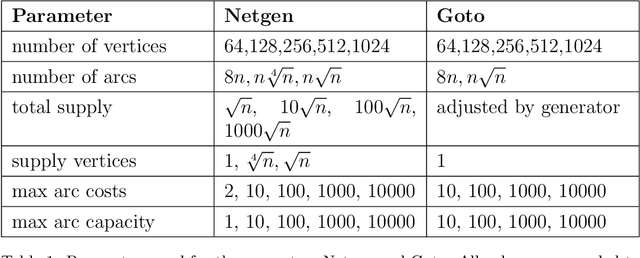
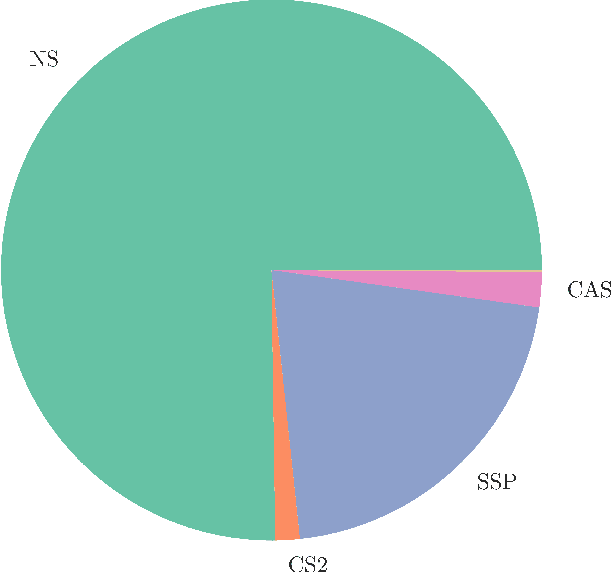
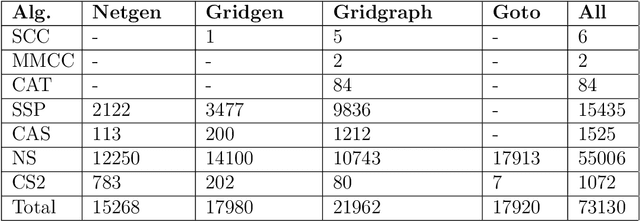
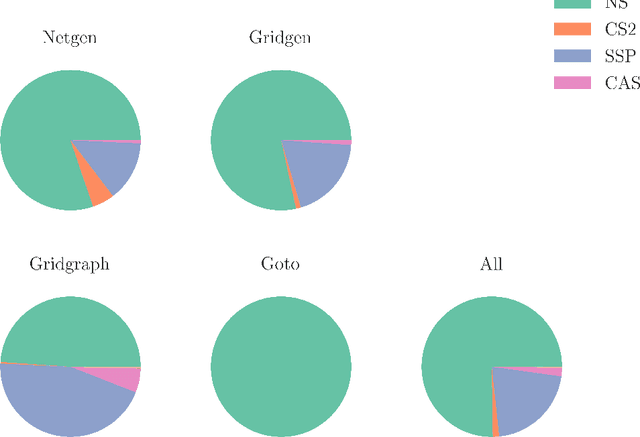
The minimum cost flow problem is one of the most studied network optimization problems and appears in numerous applications. Some efficient algorithms exist for this problem, which are freely available in the form of libraries or software packages. It is noticeable that none of these solvers is better than the other solution methods on all instances. Thus, the question arises whether the fastest algorithm can be selected for a given instance based on the characteristics of the instance. To this end, we train several machine learning classifiers to predict the fastest among a given set of solvers. We accomplish this by creating a representative data set of 81,000 instances and characterizing each of these instances by a vector of relevant features. To achieve better performance, we conduct a grid search to optimize the hyperparameters of the classifiers. Finally, we evaluate the different classifiers by means of accuracy. It is shown that tree-based models appear to adapt and exploit the relevant structures of the minimum-cost flow problem particularly well on a large number of instances, predicting the fastest solver with an accuracy of more than 90%.