 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Color Palette Modeling for Lossless Screen Content Compression
Jan 09, 2024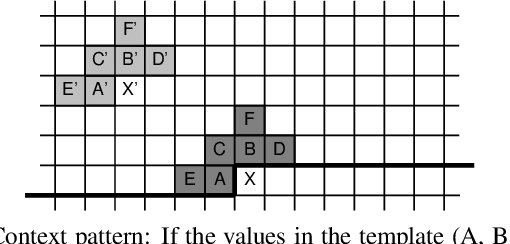
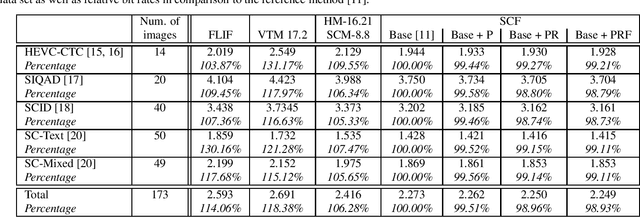
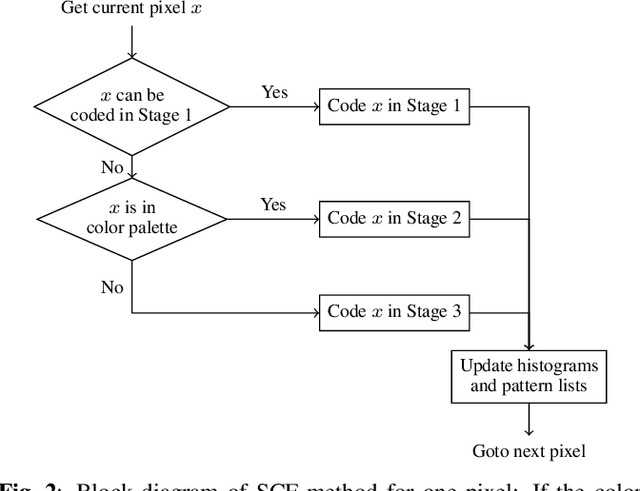
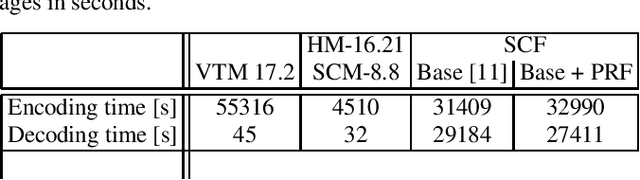
Soft context formation is a lossless image coding method for screen content. It encodes images pixel by pixel via arithmetic coding by collecting statistics for probability distribution estimation. Its main pipeline includes three stages, namely a context model based stage, a color palette stage and a residual coding stage. Each subsequent stage is only employed if the previous stage can not be applied since necessary statistics, e.g. colors or contexts, have not been learned yet. We propose the following enhancements: First, information from previous stages is used to remove redundant color palette entries and prediction errors in subsequent stages. Additionally, implicitly known stage decision signals are no longer explicitly transmitted. These enhancements lead to an average bit rate decrease of 1.07% on the evaluated data. Compared to VVC and HEVC, the proposed method needs roughly 0.44 and 0.17 bits per pixel less on average for 24-bit screen content images, respectively.
Image Segmentation For Improved Lossless Screen Content Compression
May 10, 2023



In recent years, it has been found that screen content images (SCI) can be effectively compressed based on appropriate probability modelling and suitable entropy coding methods such as arithmetic coding. The key objective is determining the best probability distribution for each pixel position. This strategy works particularly well for images with synthetic (textual) content. However, usually screen content images not only consist of synthetic but also pictorial (natural) regions. These images require diverse models of probability distributions to be optimally compressed. One way to achieve this goal is to separate synthetic and natural regions. This paper proposes a segmentation method that identifies natural regions enabling better adaptive treatment. It supplements a compression method known as Soft Context Formation (SCF) and operates as a pre-processing step. If at least one natural segment is found within the SCI, it is split into two sub images (natural and synthetic parts), and the process of modelling and coding is performed separately for both. For SCIs with natural regions, the proposed method achieves a bit-rate reduction of up to 11.6% and 1.52% with respect to HEVC and the previous version of the SCF.
Improved Screen Content Coding in VVC Using Soft Context Formation
May 09, 2023Screen content images (SCIs) often contain a mix of natural and synthetic image parts. Synthetic sections usually are comprised of uniformly colored areas as well as repeating colors and patterns. In the Versatile Video Coding (VVC) standard, these properties are largely exploited using Intra Block Copy and Palette Mode. However, the Soft Context Formation (SCF) coder, a pixel-wise lossless coder for SCIs based on pattern matching and entropy coding, outperforms the VVC in very synthetic image areas even when compared to the lossy VVC. In this paper, we propose an enhanced VVC coding approach for SCIs using Soft Context Formation. First, the image is separated into two distinct layers in a block-wise manner using a learning-based method with 4 block features. Highly synthetic image parts are coded losslessly using the SCF coder, whereas the rest of the image is coded using VVC. The SCF coder is further modified to incorporate information gained by the decoded VVC layer when encoding the SCF layer. Using this approach, we achieve BD-rate gains of 4.15% on average on the evaluated data sets when compared to VVC.